Data Cleaning
After reading data from text files or web pages it is common to have to
This can be done using
Some examples of strings that need to be processed:
"12%"
"New York *"
"2,100"
"Temp: 12 °F"Some of the most common cases are covered here.
Much more is available in R for Data Science
Removing a Percent Sign
Reading the GDP growth rate data from a web page produced a data frame with a column like
s <- c("12%", "2%")This can be converted to a numeric variable by
nchar(s)
## [1] 3 2
substr(s, 1, nchar(s) - 1)
## [1] "12" "2"
as.numeric(substr(s, 1, nchar(s) - 1))
## [1] 12 2An alternative is to use sub() function to replace "%" by the empty string "".
as.numeric(sub("%", "", s))
## [1] 12 2The function parse_number in the readr package ignores the percent sign and extracts the numbers correctly:
library(readr)
parse_number(s)
## [1] 12 2
Removing Grouping Characters
Numbers are sometimes written using grouping characters :
s1 <- c("800", "2,100")
s2 <- c("800", "2,100", "3,123,500")
The comma is often used as a grouping character in the US.
Other countries use different characters.
Other countries also use different characters for the decimal separator.
sub and gsub can be used to remove grouping characters:
sub(",", "", s1)
## [1] "800" "2100"
sub(",", "", s2)
## [1] "800" "2100" "3123,500"gsub(",", "", s2)
## [1] "800" "2100" "3123500"
as.numeric(gsub(",", "", s2))
## [1] 800 2100 3123500parse_number can again be used:
parse_number(s2)
## [1] 800 2100 3123500parse_number is convenient but may be less robust:
parse_number(s2, locale = locale(grouping_mark = "'"))
## [1] 800 2 3
Separating City and State
Data often has city and state specified in a variable like
s <- c("Boston, MA", "Iowa City, IA")If all state specifications are in two-letter form then city and state can be extracted as sub-strings:
substr(s, 1, nchar(s) - 4)
## [1] "Boston" "Iowa City"
substr(s, nchar(s) - 1, nchar(s))
## [1] "MA" "IA"This would not work if full state names are used.
An alternative is to use a regular expression .
Regular Expressions
Regular expressions are a language for expressing patterns in strings.
Regular expressions should be developed carefully, like any program, starting with simple steps and building up.
The simplest regular expressions are literal strings, like %.
More complex expressions are built up using meta-characters that have special meanings in regular expressions.
Many punctuation characters are regular expression meta-characters.
Paul Murrell’s Introduction to Data Technologies
The Strings chapter in R for Data Science also provides an introduction to regular expressions, but uses its own set of functions from the tidyverse.
The web site Regular-Expressions.info is a useful on-line resource.
Trimming White Space
If the data file is not consistent on the use of spaces in the separator another possibility is to
sub(".*,", "", s)
## [1] " MA" " IA"trimws(sub(".*,", "", s))
## [1] "MA" "IA"
Using separate
If the city-state variable is already in a data frame or tibble, then the separate function from the tidyr package can be used:
library(tibble)
library(tidyr)
d <- tibble(citystate = s)
d
## # A tibble: 2 × 1
## citystate
## <chr>
## 1 Boston, MA
## 2 Iowa City, IAseparate(d, citystate, c("city", "state"), sep = ", ")
## # A tibble: 2 × 2
## city state
## <chr> <chr>
## 1 Boston MA
## 2 Iowa City IA
Escaping Meta-Characters
Reading data from city temperatures produces a variable that looks like
s <- c("London *", "Sydney")The * indicates daylight saving or summer time.
We would like to
The * is a meta-character.
To include a literal meta-character in a pattern the meta-characters needs to be escaped .
A meta-character is escaped by preceding it by a backslash \.
But the backslash is a meta-character for R strings!
To put a backslash into an R string it needs to be written as \\.
The pattern we want to match, a space followed by a *, is ␣\*, with ␣ denoting a space character.
An R string containing these three characters is written as " \\*".
It is often useful to write a pattern once and save it in a variable.:
(pat <- " \\*")
## [1] " \\*"This string contains three characters:
nchar(pat)
## [1] 3Standard printing includes the backslash escape, and other escape characters, so the printed string can be read back into R:
"a, b
and c"
## [1] "a, b\n and c"The writeLines function is useful to see the characters in a string.
writeLines(pat)
## \*To help make the space more visible we can add a delimiter:
writeLines(paste0("'", pat, "'"))
## ' \*'Another option is to use sprintf with writeLines:
writeLines(sprintf("'%s'", pat))
## ' \*'This pattern removes the space and asterisk if present:
s
## [1] "London *" "Sydney"
sub(pat, "", s)
## [1] "London" "Sydney"The grep and grepl functions check whether a pattern matches in elements of a character vector.
grep is short for Get REgular exPression.
grep is a standard Linux command-line utility for searching text files.
In R, grep returns the indices of the elements that match the pattern.
grepl returns a logical vector indicating whether there is a match:
grep(pat, s)
## [1] 1
grepl(pat, s)
## [1] TRUE FALSE
Matching Numbers
Reading temperature data might produce a string like
s <- c("32F", "-11F")This can be processed as
substr(s, 1, nchar(s) - 1)
## [1] "32" "-11"or as
sub("F", "", s)
## [1] "32" "-11"An alternative uses some more regular expression features:
A pattern to match an integer, possibly preceded by a sign, is
intpat <- "[-+]?[[:digit:]]+"
s
## [1] "32F" "-11F"
sub(intpat, "X", s)
## [1] "XF" "XF"The [ and ] meta-characters define character sets ; any character between these will match.
[:digit:] specifies a character class of digits.
There are a number of character classes , including
[:alpha:] alphabetic letters;
[:digit:] digits;
[:space:] white space (spaces, tabs).
[:lower:] lower case letters
[:upper:] upper case letters
[:alnum:] characters from [:alpha:] and [:digit:]
[:punct:] punctuation characters
A sub_pattern can be extracted using back references :
sub("([-+]?[[:digit:]]+).*", "\\1", s)
## [1] "32" "-11"
Sub-patterns can be specified with ( and ).
Back references can be used to refer to previous sub-patterns by number.
The digit needs to be escaped with a \;
In an R string the \ needs to be escaped with a second \.
A sub-string approach for a temperature embedded in a string:
s <- c("Temp: 32F", "Temp: -11F")
(s1 <- substr(s, 6, nchar(s)))
## [1] " 32F" " -11F"
(s2 <- substr(s1, 1, nchar(s1) - 1))
## [1] " 32" " -11"
as.numeric(s2)
## [1] 32 -11Using regular expressions, sub-patterns, and back references:
sub(".*[[:space:]]+([-+]?[[:digit:]]+).*", "\\1", s)
## [1] "32" "-11"parse_number is again an alternative:
parse_number(s)
## [1] 32 -11
City Temperatures
The city temperatures data used previously can be read using
library(rvest)
library(dplyr)
weather <- read_html("https://www.timeanddate.com/weather/")
w <- html_table(html_nodes(weather, "table"))[[1]]
w1 <- w[c(1, 4)]; names(w1) <- c("city", "temp")
w2 <- w[c(5, 8)]; names(w2) <- c("city", "temp")
w3 <- w[c(9, 12)]; names(w3) <- c("city", "temp")
ww <- rbind(w1, w2, w3)
ww <- filter(ww, city != "")
head(ww)
## # A tibble: 6 × 2
## city temp
## <chr> <chr>
## 1 Accra 86 °F
## 2 Addis Ababa 64 °F
## 3 Adelaide 62 °F
## 4 Algiers 60 °F
## 5 Almaty 46 °F
## 6 Amman 64 °FCleaning up and extracting dst:
www <- mutate(ww,
dst = grepl(" \\*", city),
city = sub(" \\*", "", city),
temp.txt = temp, ## for checking on conversion failures`
temp = as.numeric(sub("([-+]?[[:digit:]]+).*", "\\1", temp)))Check on NA values from conversion:
filter(www, is.na(temp))
## # A tibble: 0 × 4
## # ℹ 4 variables: city <chr>, temp <dbl>, dst <lgl>, temp.txt <chr>
www <- select(www, -temp.txt)Five highest and lowest temperatures:
slice_max(www, temp, n = 5)
## # A tibble: 5 × 3
## city temp dst
## <chr> <dbl> <lgl>
## 1 Managua 93 FALSE
## 2 Lagos 90 FALSE
## 3 New Delhi 89 FALSE
## 4 Caracas 88 FALSE
## 5 San Salvador 88 FALSEslice_min(www, temp, n = 5)
## # A tibble: 7 × 3
## city temp dst
## <chr> <dbl> <lgl>
## 1 Anadyr 4 FALSE
## 2 Anchorage 35 TRUE
## 3 Montréal 36 TRUE
## 4 Ottawa 37 TRUE
## 5 Calgary 39 TRUE
## 6 Edmonton 39 TRUE
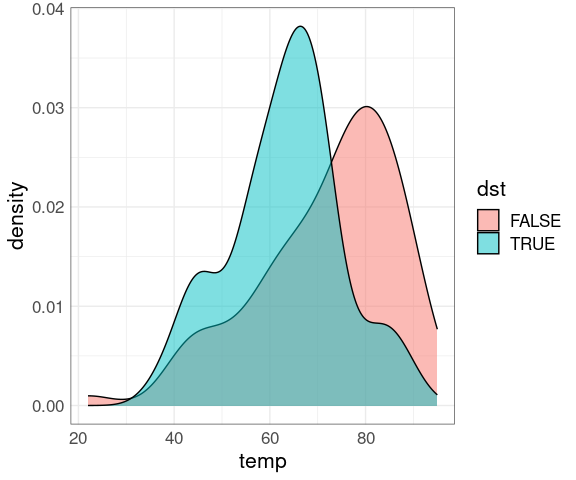
## 7 Toronto 39 TRUETemperatures for northern and southern hemisphere (approximately):
ggplot(www, aes(x = temp, fill = dst)) +
geom_density(alpha = 0.5)
Tricky Characters
Some examples:
(s <- head(ww$temp))
## [1] "86 °F" "64 °F" "62 °F" "60 °F" "46 °F" "64 °F"
nchar(s)
## [1] 5 5 5 5 5 5
substr(s, 1, nchar(s) - 3)
## [1] "86" "64" "62" "60" "46" "64"
substr(s, 1, nchar(s) - 2)
## [1] "86 " "64 " "62 " "60 " "46 " "64 "
as.numeric(substr(s, 1, nchar(s) - 2))
## Warning: NAs introduced by coercion
## [1] NA NA NA NA NA NA
as.numeric("82 ")
## [1] 82
sub(" .*", "", s)
## [1] "86 °F" "64 °F" "62 °F" "60 °F" "46 °F" "64 °F"The problem is two non-ascii characters.
The stri_escape_unicode function from the stringi package can make these characters more visible:
stringi::stri_escape_unicode(s)
## [1] "86\\u00a0\\u00b0F" "64\\u00a0\\u00b0F" "62\\u00a0\\u00b0F"
## [4] "60\\u00a0\\u00b0F" "46\\u00a0\\u00b0F" "64\\u00a0\\u00b0F"The troublesome characters are:
Using the unicode specification for the no-break space does work:
sub("\u00a0.*", "", s)
## [1] "86" "64" "62" "60" "46" "64"
Variations in Regular Expression Engines
Many tools and languages support working with regular expressions.
R supports:
The POSIX standard for extended regular expressions . This is the default engine.
Perl-compatible regular expressions (PCRE ). This engine is selected by adding perl = TRUE in calls to functions using regular expressions.
Different engines can differ in how certain regular expressions are interpreted, especially when non-ASCII characters are involved.
Different engines also sometimes offer shorthand notations, in particular for character classes.
Some examples:
[:digit:][0-9]\ddigits
[:upper:][A-Z]\uupper case letters
[:lower:][a-z]\llower-case letters
[:alpha:][A-Za-z]upper- and lower-case letters
[:space:][ \t\n]\swhitespace characters
The shorthand versions need to have their \ escaped when used in an R string:
intpat <- ".*\\s([-+]?\\d+).*"
sub(intpat, "\\1", c("Temp: 32F", "Temp: -11F"))
## [1] "32" "-11"
Raw Strings
Raw strings can make writing regular expressions a little easier.
In R a raw string is specified as r"(...)".
The ... characters can be any characters and are taken literally, without special interpretation that might require escaping.
For the integer pattern:
intpat <- ".*\\s([-+]?\\d+).*"
intpat_raw <- r"(.*\s([-+]?\d+).*)"
intpat == intpat_raw
## [1] TRUEPython, C++, and other languages provide similar facilites.
R’s raw string syntax it modeled after the one used in C++.
A Note on Sorting
Non-ASCII characters can create issues for sorting strings, but even ASCII character sort order is not the same in all locales .
The LETTERS data set contains the upper-case letters in alphabetical order for the English sorting convention and most other locales:
LETTERS
## [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S"
## [20] "T" "U" "V" "W" "X" "Y" "Z"But in Estonian, Latvian, and Lithuanian:
stringr::str_sort(LETTERS, locale = "est")
## [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S"
## [20] "Z" "T" "U" "V" "W" "X" "Y"Ordering of lower case and upper case letters in English and most other locales:
stringr::str_sort(c("A", "a"), locale = "eng")
## [1] "a" "A"But in Danish, and also Maltese:
stringr::str_sort(c("A", "a"), locale = "dan")
## [1] "A" "a"
Encoding Issues
Files contain a sequence of 8-bit integers, or bytes .
These are the integers from 0 through 255.
For text files, these bytes are interpreted as representing characters.
The mapping from bytes to characters is called an encoding .
The encoding for the characters used in American English is ASCII: the American Standard Code for Information Interchange .
The ASCII encoding uses only the integers 0 through 127.
The ASCII encoding is adequate for American uses; even UK text files need more: the pound sign £.
Encodings that use integers 128 through 255:
Many encodings are available to support other alphabets and character sets.
Fortunately most systems now use Unicode with the UTF-8 encoding for representing non-ASCII characters.
If you need to read a file with non-ASCII characters using read.csv() or similar base functions a good place to start is to specify encoding = "UTF-8".
The functions in the readr package default to assuming the encoding is UTF-8.
Getting the encoding wrong can result in a few messed up characters or in an entire string being messed up:
Reading files without specifying the correct encoding might produce strings like
x1
## [1] "El Ni\xf1o was particularly bad this year"
x2
## [1] "\x82\xb1\x82\xf1\x82ɂ\xbf\x82\xcd"If the correct encoding is known, then these can be fixed after the fact with iconv():
iconv(x1, "Latin1", "UTF-8")
## [1] "El Niño was particularly bad this year"
iconv(x2, "Shift-JIS", "UTF-8")
## [1] "こんにちは"Re-reading the file with the proper encoding specified may be a better option.
The readr function guess_encoding() may help identify the correct encoding if it is not specified in the data documentation.
Handling encoding issues in R used to be more complicated on Windows, but this has improved with recent releases of R.
Fonts
Once you have the right encoding for character data, you also need a set of fonts so your data shows up properly in the console, the editor, and graphs.
Fonts may already be installed.
c("\U{1f600}", "\u3041", "\u4a00")
## [1] "😀" "ぁ" "䨀"If glyphs are not availabl, the characters may be shown in various ways.
c("\U{105b8}", "\u3040")
## [1] "𐖸" "\u3040"How to install fonts will depend on your platform.
A plot with emojis:
data.frame(x = 1:10,
y = runif(10),
z = sapply(0x1f600 + 0:9,
intToUtf8)) |>
ggplot(aes(x, y, label = z)) +
geom_text()
A Note on Line Endings
On Linux and current macOS lines of text in files are terminated by a line feed (LF) character \n or \x0a.
On Windows, and in HTML, lines are terminated by a carriage return (CR, \r, x0d) followed by a linefeed (CRLF).
On Linux and macOS there is no difference in reading or writing to a file in text mode or binary mode .
On Windows, reading in text mode translates from CRLF line endings to LF, and writing translates LF line endings to CRLF.
Many file transfer operations will do this conversion.
Git will check out text files with the appropriate line endings for the platform.
Most higher-level tools on Linux will work with CRLF line endings, and on Windows will work for LF line endings.
Occasionally you may see some issues, and need to fix the line endings yourself.
Getting the Current Temperature
The tools described here come in handy when scraping data from the web.
This code gets the current temperature in Iowa City from the National Weather Service:
library(xml2)
url <- "http://forecast.weather.gov/zipcity.php?inputstring=Iowa+City,IA"
page <- read_html(url)
xpath <- "//p[@class=\"myforecast-current-lrg\"]"
tempNode <- xml_find_first(page, xpath)
nodeText <- xml_text(tempNode)
as.numeric(sub("([-+]?[[:digit:]]+).*", "\\1", nodeText))An example of creating a current temperature map is described here .
Exercises
Complete all lessons and exercises in the https://regexone.com/ online interactive tutorial.
Consider the code
library(tidyverse)
filter(mpg, grepl(---, model))For which of the following regular expressions in place of --- will this code return the subset of rows for all models that contain either 4wd or awd in their model names?
“[a4]wd”
“[a4]wd”
“4awd”
“[[4a]]wd”
LS0tCnRpdGxlOiAiU3RyaW5nIFBhcnNpbmcgYW5kIFJlZ3VsYXIgRXhwcmVzc2lvbnMiCm91dHB1dDoKICBodG1sX2RvY3VtZW50OgogICAgdG9jOiB5ZXMKICAgIGNvZGVfZm9sZGluZzogc2hvdwogICAgY29kZV9kb3dubG9hZDogdHJ1ZQotLS0KCjxsaW5rIHJlbD0ic3R5bGVzaGVldCIgaHJlZj0ic3RhdDQ1ODAuY3NzIiB0eXBlPSJ0ZXh0L2NzcyIgLz4KPHN0eWxlIHR5cGU9InRleHQvY3NzIj4gLnJlbWFyay1jb2RlIHsgZm9udC1zaXplOiA4NSU7IH0gPC9zdHlsZT4KYGBge3Igc2V0dXAsIGluY2x1ZGUgPSBGQUxTRX0Kc291cmNlKGhlcmU6OmhlcmUoInNldHVwLlIiKSkKa25pdHI6Om9wdHNfY2h1bmskc2V0KGNvbGxhcHNlID0gVFJVRSwgbWVzc2FnZSA9IEZBTFNFLAogICAgICAgICAgICAgICAgICAgICAgZmlnLmhlaWdodCA9IDUsIGZpZy53aWR0aCA9IDYsIGZpZy5hbGlnbiA9ICJjZW50ZXIiKQoKb3B0aW9ucyhodG1sdG9vbHMuZGlyLnZlcnNpb24gPSBGQUxTRSkKCnNldC5zZWVkKDEyMzQ1KQpsaWJyYXJ5KGdncGxvdDIpCmxpYnJhcnkobGF0dGljZSkKbGlicmFyeSh0aWR5dmVyc2UpCmxpYnJhcnkoZ3JpZEV4dHJhKQp0aGVtZV9zZXQodGhlbWVfbWluaW1hbCgpICsKICAgICAgICAgIHRoZW1lKHRleHQgPSBlbGVtZW50X3RleHQoc2l6ZSA9IDE2KSwKICAgICAgICAgICAgICAgIHBhbmVsLmJvcmRlciA9IGVsZW1lbnRfcmVjdChjb2xvciA9ICJncmV5MzAiLCBmaWxsID0gTkEpKSkKYGBgCgoKIyMgRGF0YSBDbGVhbmluZwoKQWZ0ZXIgcmVhZGluZyBkYXRhIGZyb20gdGV4dCBmaWxlcyBvciB3ZWIgcGFnZXMgaXQgaXMgY29tbW9uIHRvIGhhdmUgdG8KCiogY2xlYW4gdXAgc3RyaW5nIHZhcmlhYmxlczsKCiogZXh0cmFjdCBudW1iZXJzLgoKVGhpcyBjYW4gYmUgZG9uZSB1c2luZwoKKiBoaWdoLWxldmVsIGZ1bmN0aW9ucyB0aGF0IHVzdWFsbHkgd29yayBidXQgbm90IGFsd2F5czsKCiogdXNpbmcgc3RyaW5nIHN1YnNldHRpbmc7CgoqIHVzaW5nIF9yZWd1bGFyIGV4cHJlc3Npb25zXy4KClNvbWUgZXhhbXBsZXMgb2Ygc3RyaW5ncyB0aGF0IG5lZWQgdG8gYmUgcHJvY2Vzc2VkOgoKYGBge3IsIGV2YWwgPSBGQUxTRX0KIjEyJSIKIk5ldyBZb3JrICoiCiIyLDEwMCIKIlRlbXA6IDEyIMKwRiIKYGBgCgpTb21lIG9mIHRoZSBtb3N0IGNvbW1vbiBjYXNlcyBhcmUgY292ZXJlZCBoZXJlLgoKTXVjaCBtb3JlIGlzIGF2YWlsYWJsZSBpbiBbX1IgZm9yIERhdGEKU2NpZW5jZV9dKGh0dHBzOi8vcjRkcy5oYWRsZXkubnovKSwgaW4gcGFydGljdWxhciBpbiB0aGUgY2hhcHRlcnMKCiogW19EYXRhIEltcG9ydF9dKGh0dHBzOi8vcjRkcy5oYWRsZXkubnovZGF0YS1pbXBvcnQuaHRtbCk7CiogW19TdHJpbmdzX10oaHR0cHM6Ly9yNGRzLmhhZGxleS5uei9zdHJpbmdzLmh0bWwpLgoKCiMjIFJlbW92aW5nIGEgUGVyY2VudCBTaWduCgpSZWFkaW5nIHRoZSBHRFAgZ3Jvd3RoIHJhdGUgZGF0YSBmcm9tIGEgClt3ZWIgcGFnZV0oaHR0cHM6Ly93d3cubXVsdHBsLmNvbS91cy1yZWFsLWdkcC1ncm93dGgtcmF0ZS90YWJsZS9ieS1xdWFydGVyKQpwcm9kdWNlZCBhIGRhdGEgZnJhbWUgd2l0aCBhIGNvbHVtbiBsaWtlCgpgYGB7cn0KcyA8LSBjKCIxMiUiLCAiMiUiKQpgYGAKClRoaXMgY2FuIGJlIGNvbnZlcnRlZCB0byBhIG51bWVyaWMgdmFyaWFibGUgYnkKCiogZXh0cmFjdGluZyB0aGUgc3ViLXN0cmluZyB3aXRob3V0IHRoZSBgJWAKCiogYW5kIHRoZW4gdXNpbmcgYGFzLm51bWVyaWNgLgoKYGBge3J9Cm5jaGFyKHMpCnN1YnN0cihzLCAxLCBuY2hhcihzKSAtIDEpCmFzLm51bWVyaWMoc3Vic3RyKHMsIDEsIG5jaGFyKHMpIC0gMSkpCmBgYAoKQW4gYWx0ZXJuYXRpdmUgaXMgdG8gdXNlIGBzdWIoKWAgZnVuY3Rpb24gdG8gcmVwbGFjZSBgIiUiYCBieSB0aGUKZW1wdHkgc3RyaW5nIGAiImAuCgpgYGB7cn0KYXMubnVtZXJpYyhzdWIoIiUiLCAiIiwgcykpCmBgYAoKVGhlIGZ1bmN0aW9uIGBwYXJzZV9udW1iZXJgIGluIHRoZSBgcmVhZHJgIHBhY2thZ2UgaWdub3JlcyB0aGUgcGVyY2VudApzaWduIGFuZCBleHRyYWN0cyB0aGUgbnVtYmVycyBjb3JyZWN0bHk6CgpgYGB7cn0KbGlicmFyeShyZWFkcikKcGFyc2VfbnVtYmVyKHMpCmBgYAoKCiMjIFJlbW92aW5nIEdyb3VwaW5nIENoYXJhY3RlcnMKCk51bWJlcnMgYXJlIHNvbWV0aW1lcyB3cml0dGVuIHVzaW5nIF9ncm91cGluZyBjaGFyYWN0ZXJzXzoKCmBgYHtyfQpzMSA8LSBjKCI4MDAiLCAiMiwxMDAiKQpzMiA8LSBjKCI4MDAiLCAiMiwxMDAiLCAiMywxMjMsNTAwIikKYGBgCgoqIFRoZSBjb21tYSBpcyBvZnRlbiB1c2VkIGFzIGEgZ3JvdXBpbmcgY2hhcmFjdGVyIGluIHRoZSBVUy4KCiogT3RoZXIgY291bnRyaWVzIHVzZSBkaWZmZXJlbnQgY2hhcmFjdGVycy4KCiogT3RoZXIgY291bnRyaWVzIGFsc28gdXNlIGRpZmZlcmVudCBjaGFyYWN0ZXJzIGZvciB0aGUgZGVjaW1hbCBzZXBhcmF0b3IuCgpgc3ViYCBhbmQgYGdzdWJgIGNhbiBiZSB1c2VkIHRvIHJlbW92ZSBncm91cGluZyBjaGFyYWN0ZXJzOgoKYGBge3J9CnN1YigiLCIsICIiLCBzMSkKc3ViKCIsIiwgIiIsIHMyKQpgYGAKCmBgYHtyfQpnc3ViKCIsIiwgIiIsIHMyKQphcy5udW1lcmljKGdzdWIoIiwiLCAiIiwgczIpKQpgYGAKCiogYHN1YmAgcmVwbGFjZXMgdGhlIGZpcnN0IG1hdGNoIHRvIGEgcGF0dGVybjsKCiogYGdzdWJgIHJlcGxhY2VzIGFsbCBtYXRjaGVzLgoKYHBhcnNlX251bWJlcmAgY2FuIGFnYWluIGJlIHVzZWQ6CgpgYGB7cn0KcGFyc2VfbnVtYmVyKHMyKQpgYGAKCmBwYXJzZV9udW1iZXJgIGlzIGNvbnZlbmllbnQgYnV0IG1heSBiZSBsZXNzIHJvYnVzdDoKCiogSW4gU3dpdHplcmxhbmQgdGhlIGdyb3VwaW5nIGNoYXJhY3RlciBpcyBgJ2AuCgoqIElmIGBwYXJzZV9udW1iZXJgIGhhcyBpdHMgZGVmYXVsdHMgc2V0IHRvIFN3aXNzIGNvbnZlbnRpb25zOgoKYGBge3J9CnBhcnNlX251bWJlcihzMiwgbG9jYWxlID0gbG9jYWxlKGdyb3VwaW5nX21hcmsgPSAiJyIpKQpgYGAKCiMjIFNlcGFyYXRpbmcgQ2l0eSBhbmQgU3RhdGUKCkRhdGEgb2Z0ZW4gaGFzIGNpdHkgYW5kIHN0YXRlIHNwZWNpZmllZCBpbiBhIHZhcmlhYmxlIGxpa2UKCmBgYHtyfQpzIDwtIGMoIkJvc3RvbiwgTUEiLCAiSW93YSBDaXR5LCBJQSIpCmBgYAoKSWYgYWxsIHN0YXRlIHNwZWNpZmljYXRpb25zIGFyZSBpbiB0d28tbGV0dGVyIGZvcm0gdGhlbiBjaXR5IGFuZCBzdGF0ZQpjYW4gYmUgZXh0cmFjdGVkIGFzIHN1Yi1zdHJpbmdzOgoKYGBge3J9CnN1YnN0cihzLCAxLCBuY2hhcihzKSAtIDQpCnN1YnN0cihzLCBuY2hhcihzKSAtIDEsIG5jaGFyKHMpKQpgYGAKClRoaXMgd291bGQgbm90IHdvcmsgaWYgZnVsbCBzdGF0ZSBuYW1lcyBhcmUgdXNlZC4KCkFuIGFsdGVybmF0aXZlIGlzIHRvIHVzZSBhIF9yZWd1bGFyIGV4cHJlc3Npb25fLgoKCiMjIFJlZ3VsYXIgRXhwcmVzc2lvbnMKClJlZ3VsYXIgZXhwcmVzc2lvbnMgYXJlIGEgbGFuZ3VhZ2UgZm9yIGV4cHJlc3NpbmcgcGF0dGVybnMgaW4gc3RyaW5ncy4KClJlZ3VsYXIgZXhwcmVzc2lvbnMgc2hvdWxkIGJlIGRldmVsb3BlZCBjYXJlZnVsbHksIGxpa2UgYW55IHByb2dyYW0sCnN0YXJ0aW5nIHdpdGggc2ltcGxlIHN0ZXBzIGFuZCBidWlsZGluZyB1cC4KClRoZSBzaW1wbGVzdCByZWd1bGFyIGV4cHJlc3Npb25zIGFyZSBsaXRlcmFsIHN0cmluZ3MsIGxpa2UgYCVgLgoKTW9yZSBjb21wbGV4IGV4cHJlc3Npb25zIGFyZSBidWlsdCB1cCB1c2luZyBfbWV0YS1jaGFyYWN0ZXJzXyB0aGF0CmhhdmUgc3BlY2lhbCBtZWFuaW5ncyBpbiByZWd1bGFyIGV4cHJlc3Npb25zLgoKTWFueSBwdW5jdHVhdGlvbiBjaGFyYWN0ZXJzIGFyZSByZWd1bGFyIGV4cHJlc3Npb24gbWV0YS1jaGFyYWN0ZXJzLgoKUGF1bCBNdXJyZWxsJ3MgW19JbnRyb2R1Y3Rpb24gdG8gRGF0YQogIFRlY2hub2xvZ2llc19dKGh0dHA6Ly93d3cuc3RhdC5hdWNrbGFuZC5hYy5uei9+cGF1bC9JdERULykgcHJvdmlkZXMKICBhIGdvb2QgaW50cm9kdWN0aW9uIGluIFNlY3Rpb24gOS45LjIgYW5kIGFuIGV4dGVuc2l2ZSByZWZlcmVuY2UgaW4KICBDaGFwdGVyIDExLgoKVGhlIFtTdHJpbmdzIGNoYXB0ZXJdKGh0dHBzOi8vcjRkcy5oYWRsZXkubnovc3RyaW5ncy5odG1sKSBpbiBbUiBmb3IKRGF0YSBTY2llbmNlXShodHRwczovL3I0ZHMuaGFkbGV5Lm56LykgYWxzbyBwcm92aWRlcyBhbiBpbnRyb2R1Y3Rpb24gdG8KcmVndWxhciBleHByZXNzaW9ucywgYnV0IHVzZXMgaXRzIG93biBzZXQgb2YgZnVuY3Rpb25zIGZyb20gdGhlCmB0aWR5dmVyc2VgLgoKVGhlIHdlYiBzaXRlCltSZWd1bGFyLUV4cHJlc3Npb25zLmluZm9dKGh0dHBzOi8vd3d3LnJlZ3VsYXItZXhwcmVzc2lvbnMuaW5mby8pIGlzIGEKdXNlZnVsIG9uLWxpbmUgcmVzb3VyY2UuCgoKIyMgUmVndWxhciBFeHByZXNzaW9uIE1ldGEtQ2hhcmN0ZXJzCgpTb21lIGltcG9ydGFudCBtZXRhLWNoYXJhY3RlcnMgYXJlIGAuYCwgYCpgLCBgK2AsIGFuZCBgP2A6CgoqIFRoZSBwZXJpb2QgYC5gIHN0YW5kcyBmb3IgYW55IGNoYXJhY3Rlci4KCiogVGhlIGFzdGVyaXNrIGAqYCBtZWFucyB6ZXJvLCBvbmUsIG9yIG1vcmUgb2YgdGhlIHByZWNlZGluZyBjaGFyYWN0ZXIKICBzcGVjaWZpY2F0aW9uLgoKKiBUaGUgcGx1cyBzaWduIGArYCBtZWFucyBvbmUsIG9yIG1vcmUgb2YgdGhlIHByZWNlZGluZyBjaGFyYWN0ZXIKICBzcGVjaWZpY2F0aW9uLgoKKiBUaGUgcXVlc3Rpb24gbWFyayBgP2AgbWVhbnMgemVybyBvciBvbmUgb2YgdGhlIHByZWNlZGluZyBjaGFyYWN0ZXIKICBzcGVjaWZpY2F0aW9uLgoKVGhlIHBhdHRlcm4gYCIsLioiYCBtYXRjaGVzIGEgY29tbWEgYCxgIGZvbGxvd2VkIGJ5IHplcm8gb3IgbW9yZQpjaGFyYWN0ZXJzOgoKYGBge3J9CnMKc3ViKCIsLioiLCAiIiwgcykKYGBgCgpUaGUgcGF0dGVybiBgIi4qLCAiYCBtYXRjaGVzIHplcm8gb3IgbW9yZSBjaGFyYWN0ZXJzIGZvbGxvd2VkIGJ5IGEKY29tbWEgYW5kIGEgc3BhY2U6CgpgYGB7cn0Kc3ViKCIuKiwgIiwgIiIsIHMpCmBgYAoKCiMjIFRyaW1taW5nIFdoaXRlIFNwYWNlCgpJZiB0aGUgZGF0YSBmaWxlIGlzIG5vdCBjb25zaXN0ZW50IG9uIHRoZSB1c2Ugb2Ygc3BhY2VzIGluIHRoZQpzZXBhcmF0b3IgYW5vdGhlciBwb3NzaWJpbGl0eSBpcyB0bwoKKiByZW1vdmUgdGhlIGNoYXJhY3RlcnMgdGhyb3VnaCB0aGUgY29tbWE7CgoqIHRyaW0gdGhlIHdoaXRlIHNwYWNlIGZyb20gdGhlIHJlc3VsdC4KCmBgYHtyfQpzdWIoIi4qLCIsICIiLCBzKQpgYGAKCmBgYHtyfQp0cmltd3Moc3ViKCIuKiwiLCAiIiwgcykpCmBgYAoKCiMjIFVzaW5nIGBzZXBhcmF0ZWAKCklmIHRoZSBjaXR5LXN0YXRlIHZhcmlhYmxlIGlzIGFscmVhZHkgaW4gYSBkYXRhIGZyYW1lIG9yIHRpYmJsZSwgdGhlbgp0aGUgYHNlcGFyYXRlYCBmdW5jdGlvbiBmcm9tIHRoZSBgdGlkeXJgIHBhY2thZ2UgY2FuIGJlIHVzZWQ6CgpgYGB7cn0KbGlicmFyeSh0aWJibGUpCmxpYnJhcnkodGlkeXIpCmQgPC0gdGliYmxlKGNpdHlzdGF0ZSA9IHMpCmQKYGBgCgpgYGB7cn0Kc2VwYXJhdGUoZCwgY2l0eXN0YXRlLCBjKCJjaXR5IiwgInN0YXRlIiksIHNlcCA9ICIsICIpCmBgYAoKCiMjIEVzY2FwaW5nIE1ldGEtQ2hhcmFjdGVycwoKUmVhZGluZyBkYXRhIGZyb20KW2NpdHkgdGVtcGVyYXR1cmVzXShodHRwczovL3d3dy50aW1lYW5kZGF0ZS5jb20vd2VhdGhlci8pCnByb2R1Y2VzIGEgdmFyaWFibGUgdGhhdCBsb29rcyBsaWtlCgpgYGB7cn0KcyA8LSBjKCJMb25kb24gKiIsICJTeWRuZXkiKQpgYGAKClRoZSBgKmAgaW5kaWNhdGVzIGRheWxpZ2h0IHNhdmluZyBvciBzdW1tZXIgdGltZS4KCldlIHdvdWxkIGxpa2UgdG8KCiogZXh0cmFjdCB0aGUgY2l0eSBuYW1lOwoKKiBleHRyYWN0IHdoZXRoZXIgdGhlcmUgaXMgYSBgKmAuCgpUaGUgYCpgIGlzIGEgbWV0YS1jaGFyYWN0ZXIuCgpUbyBpbmNsdWRlIGEgbGl0ZXJhbCBtZXRhLWNoYXJhY3RlciBpbiBhIHBhdHRlcm4gdGhlIG1ldGEtY2hhcmFjdGVycwpuZWVkcyB0byBiZSBfZXNjYXBlZF8uCgpBIG1ldGEtY2hhcmFjdGVyIGlzIGVzY2FwZWQgYnkgcHJlY2VkaW5nIGl0IGJ5IGEgYmFja3NsYXNoIGBcYC4KCkJ1dCB0aGUgYmFja3NsYXNoIGlzIGEgbWV0YS1jaGFyYWN0ZXIgZm9yIFIgc3RyaW5ncyEKClRvIHB1dCBhIGJhY2tzbGFzaCBpbnRvIGFuIFIgc3RyaW5nIGl0IG5lZWRzIHRvIGJlIHdyaXR0ZW4gYXMgYFxcYC4KClRoZSBwYXR0ZXJuIHdlIHdhbnQgdG8gbWF0Y2gsIGEgc3BhY2UgZm9sbG93ZWQgYnkgYSBgKmAsIGlzIApg4pCjXCpgLCB3aXRoIGDikKNgIGRlbm90aW5nIGEgc3BhY2UgY2hhcmFjdGVyLgoKQW4gUiBzdHJpbmcgY29udGFpbmluZyB0aGVzZSB0aHJlZSBjaGFyYWN0ZXJzIGlzIHdyaXR0ZW4gYXMgYCIgXFwqImAuCgpJdCBpcyBvZnRlbiB1c2VmdWwgdG8gd3JpdGUgYSBwYXR0ZXJuIG9uY2UgYW5kIHNhdmUgaXQgaW4gYSB2YXJpYWJsZS5cOgoKYGBge3J9CihwYXQgPC0gIiBcXCoiKQpgYGAKClRoaXMgc3RyaW5nIGNvbnRhaW5zIHRocmVlIGNoYXJhY3RlcnM6CgpgYGB7cn0KbmNoYXIocGF0KQpgYGAKClN0YW5kYXJkIHByaW50aW5nIGluY2x1ZGVzIHRoZSBiYWNrc2xhc2ggZXNjYXBlLCBhbmQgb3RoZXIgZXNjYXBlCmNoYXJhY3RlcnMsIHNvIHRoZSBwcmludGVkIHN0cmluZyBjYW4gYmUgcmVhZCBiYWNrIGludG8gUjoKCmBgYHtyfQoiYSwgYgogYW5kIGMiCmBgYAoKVGhlIGB3cml0ZUxpbmVzYCBmdW5jdGlvbiBpcyB1c2VmdWwgdG8gc2VlIHRoZSBjaGFyYWN0ZXJzIGluIGEgc3RyaW5nLgoKYGBge3J9CndyaXRlTGluZXMocGF0KQpgYGAKClRvIGhlbHAgbWFrZSB0aGUgc3BhY2UgbW9yZSB2aXNpYmxlIHdlIGNhbiBhZGQgYSBkZWxpbWl0ZXI6CgpgYGB7cn0Kd3JpdGVMaW5lcyhwYXN0ZTAoIiciLCBwYXQsICInIikpCmBgYAoKQW5vdGhlciBvcHRpb24gaXMgdG8gdXNlIGBzcHJpbnRmYCB3aXRoIGB3cml0ZUxpbmVzYDoKCmBgYHtyfQp3cml0ZUxpbmVzKHNwcmludGYoIiclcyciLCBwYXQpKQpgYGAKClRoaXMgcGF0dGVybiByZW1vdmVzIHRoZSBzcGFjZSBhbmQgYXN0ZXJpc2sgaWYgcHJlc2VudDoKCmBgYHtyfQpzCnN1YihwYXQsICIiLCBzKQpgYGAKClRoZSBgZ3JlcGAgYW5kIGBncmVwbGAgZnVuY3Rpb25zIGNoZWNrIHdoZXRoZXIgYSBwYXR0ZXJuIG1hdGNoZXMgaW4KZWxlbWVudHMgb2YgYSBjaGFyYWN0ZXIgdmVjdG9yLgoKKiBgZ3JlcGAgaXMgc2hvcnQgZm9yIEdldCBSRWd1bGFyIGV4UHJlc3Npb24uCgoqIGBncmVwYCBpcyBhIHN0YW5kYXJkIExpbnV4IGNvbW1hbmQtbGluZSB1dGlsaXR5IGZvciBzZWFyY2hpbmcgdGV4dCBmaWxlcy4KCiogSW4gUiwgYGdyZXBgIHJldHVybnMgdGhlIGluZGljZXMgb2YgdGhlIGVsZW1lbnRzIHRoYXQgbWF0Y2ggdGhlIHBhdHRlcm4uCgoqIGBncmVwbGAgcmV0dXJucyBhIGxvZ2ljYWwgdmVjdG9yIGluZGljYXRpbmcgd2hldGhlciB0aGVyZSBpcyBhIG1hdGNoOgoKYGBge3J9CmdyZXAocGF0LCBzKQpncmVwbChwYXQsIHMpCmBgYAoKCiMjIE1hdGNoaW5nIE51bWJlcnMKClJlYWRpbmcgdGVtcGVyYXR1cmUgZGF0YSBtaWdodCBwcm9kdWNlIGEgc3RyaW5nIGxpa2UKCmBgYHtyfQpzIDwtIGMoIjMyRiIsICItMTFGIikKYGBgCgpUaGlzIGNhbiBiZSBwcm9jZXNzZWQgYXMKCmBgYHtyfQpzdWJzdHIocywgMSwgbmNoYXIocykgLSAxKQpgYGAKCm9yIGFzCgpgYGB7cn0Kc3ViKCJGIiwgIiIsIHMpCmBgYAoKQW4gYWx0ZXJuYXRpdmUgdXNlcyBzb21lIG1vcmUgcmVndWxhciBleHByZXNzaW9uIGZlYXR1cmVzOgoKKiBtYXRjaCB0aGUgbnVtYmVyIHdpdGhpbiB0aGUgc3RyaW5nOwoKKiBleHRyYWN0IGEgc3ViLW1hdGNoLgoKQSBwYXR0ZXJuIHRvIG1hdGNoIGFuIGludGVnZXIsIHBvc3NpYmx5IHByZWNlZGVkIGJ5IGEgc2lnbiwgaXMKCmBgYHtyfQppbnRwYXQgPC0gIlstK10/W1s6ZGlnaXQ6XV0rIgpzCnN1YihpbnRwYXQsICJYIiwgcykKYGBgCgpUaGUgYFtgIGFuZCBgXWAgbWV0YS1jaGFyYWN0ZXJzIGRlZmluZSBfY2hhcmFjdGVyIHNldHNfOyBhbnkgY2hhcmFjdGVyCmJldHdlZW4gdGhlc2Ugd2lsbCBtYXRjaC4KCmBbOmRpZ2l0Ol1gIHNwZWNpZmllcyBhIF9jaGFyYWN0ZXIgY2xhc3NfIG9mIGRpZ2l0cy4KClRoZXJlIGFyZSBhIG51bWJlciBvZiBfY2hhcmFjdGVyIGNsYXNzZXNfLCBpbmNsdWRpbmcKCiogYFs6YWxwaGE6XWAgYWxwaGFiZXRpYyBsZXR0ZXJzOwoKKiBgWzpkaWdpdDpdYCBkaWdpdHM7CgoqIGBbOnNwYWNlOl1gIHdoaXRlIHNwYWNlIChzcGFjZXMsIHRhYnMpLgoKKiBgWzpsb3dlcjpdYCBsb3dlciBjYXNlIGxldHRlcnMKCiogYFs6dXBwZXI6XWAgdXBwZXIgY2FzZSBsZXR0ZXJzCgoqIGBbOmFsbnVtOl1gIGNoYXJhY3RlcnMgZnJvbSBgWzphbHBoYTpdYCBhbmQgYFs6ZGlnaXQ6XWAKCiogYFs6cHVuY3Q6XWAgcHVuY3R1YXRpb24gY2hhcmFjdGVycwoKQSBfc3ViX3BhdHRlcm5fIGNhbiBiZSBleHRyYWN0ZWQgdXNpbmcgX2JhY2sgcmVmZXJlbmNlc186CgpgYGB7cn0Kc3ViKCIoWy0rXT9bWzpkaWdpdDpdXSspLioiLCAiXFwxIiwgcykKYGBgCgoqIFN1Yi1wYXR0ZXJucyBjYW4gYmUgc3BlY2lmaWVkIHdpdGggYChgIGFuZCBgKWAuCgoqIF9CYWNrIHJlZmVyZW5jZXNfIGNhbiBiZSB1c2VkIHRvIHJlZmVyIHRvIHByZXZpb3VzIHN1Yi1wYXR0ZXJucyBieSBudW1iZXIuCgoqIFRoZSBkaWdpdCBuZWVkcyB0byBiZSBlc2NhcGVkIHdpdGggYSBgXGA7CgoqIEluIGFuIFIgc3RyaW5nIHRoZSBgXGAgbmVlZHMgdG8gYmUgZXNjYXBlZCB3aXRoIGEgc2Vjb25kIGBcYC4KCkEgc3ViLXN0cmluZyBhcHByb2FjaCBmb3IgYSB0ZW1wZXJhdHVyZSBlbWJlZGRlZCBpbiBhIHN0cmluZzoKCmBgYHtyfQpzIDwtIGMoIlRlbXA6ICAzMkYiLCAiVGVtcDogLTExRiIpCihzMSA8LSBzdWJzdHIocywgNiwgbmNoYXIocykpKQooczIgPC0gc3Vic3RyKHMxLCAxLCBuY2hhcihzMSkgLSAxKSkKYXMubnVtZXJpYyhzMikKYGBgCgpVc2luZyByZWd1bGFyIGV4cHJlc3Npb25zLCBzdWItcGF0dGVybnMsIGFuZCBiYWNrIHJlZmVyZW5jZXM6CgpgYGB7cn0Kc3ViKCIuKltbOnNwYWNlOl1dKyhbLStdP1tbOmRpZ2l0Ol1dKykuKiIsICJcXDEiLCBzKQpgYGAKCmBwYXJzZV9udW1iZXJgIGlzIGFnYWluIGFuIGFsdGVybmF0aXZlOgoKYGBge3J9CnBhcnNlX251bWJlcihzKQpgYGAKCgojIyBDaXR5IFRlbXBlcmF0dXJlcwoKVGhlIFtjaXR5IHRlbXBlcmF0dXJlc10oaHR0cHM6Ly93d3cudGltZWFuZGRhdGUuY29tL3dlYXRoZXIvKQpkYXRhIHVzZWQgcHJldmlvdXNseSBjYW4gYmUgcmVhZCB1c2luZwoKYGBge3IsIG1lc3NhZ2UgPSBGQUxTRX0KbGlicmFyeShydmVzdCkKbGlicmFyeShkcGx5cikKd2VhdGhlciA8LSByZWFkX2h0bWwoImh0dHBzOi8vd3d3LnRpbWVhbmRkYXRlLmNvbS93ZWF0aGVyLyIpCncgPC0gaHRtbF90YWJsZShodG1sX25vZGVzKHdlYXRoZXIsICJ0YWJsZSIpKVtbMV1dCgp3MSA8LSB3W2MoMSwgNCldOyBuYW1lcyh3MSkgPC0gYygiY2l0eSIsICJ0ZW1wIikKdzIgPC0gd1tjKDUsIDgpXTsgbmFtZXModzIpIDwtIGMoImNpdHkiLCAidGVtcCIpCnczIDwtIHdbYyg5LCAxMildOyBuYW1lcyh3MykgPC0gYygiY2l0eSIsICJ0ZW1wIikKd3cgPC0gcmJpbmQodzEsIHcyLCB3MykKd3cgPC0gZmlsdGVyKHd3LCBjaXR5ICE9ICIiKQpoZWFkKHd3KQpgYGAKCkNsZWFuaW5nIHVwIGFuZCBleHRyYWN0aW5nIGBkc3RgOgpgYGB7cn0Kd3d3IDwtIG11dGF0ZSh3dywKICAgICAgICAgICAgICBkc3QgPSBncmVwbCgiIFxcKiIsIGNpdHkpLAogICAgICAgICAgICAgIGNpdHkgPSBzdWIoIiBcXCoiLCAiIiwgY2l0eSksCiAgICAgICAgICAgICAgdGVtcC50eHQgPSB0ZW1wLCAgICMjIGZvciBjaGVja2luZyBvbiBjb252ZXJzaW9uIGZhaWx1cmVzYAogICAgICAgICAgICAgIHRlbXAgPSBhcy5udW1lcmljKHN1YigiKFstK10/W1s6ZGlnaXQ6XV0rKS4qIiwgIlxcMSIsIHRlbXApKSkKYGBgCgpDaGVjayBvbiBgTkFgIHZhbHVlcyBmcm9tIGNvbnZlcnNpb246CgpgYGB7cn0KZmlsdGVyKHd3dywgaXMubmEodGVtcCkpCnd3dyA8LSBzZWxlY3Qod3d3LCAtdGVtcC50eHQpCmBgYAoKRml2ZSBoaWdoZXN0IGFuZCBsb3dlc3QgdGVtcGVyYXR1cmVzOiAKYGBge3J9CnNsaWNlX21heCh3d3csIHRlbXAsIG4gPSA1KQpgYGAKYGBge3J9CnNsaWNlX21pbih3d3csIHRlbXAsIG4gPSA1KQpgYGAKClRlbXBlcmF0dXJlcyBmb3Igbm9ydGhlcm4gYW5kIHNvdXRoZXJuIGhlbWlzcGhlcmUgKGFwcHJveGltYXRlbHkpOgoKYGBge3IgdGVtcC1kZW5zaXRpZXMsIGV2YWwgPSBGQUxTRX0KZ2dwbG90KHd3dywgYWVzKHggPSB0ZW1wLCBmaWxsID0gZHN0KSkgKwogICAgZ2VvbV9kZW5zaXR5KGFscGhhID0gMC41KQpgYGAKYGBge3IgdGVtcC1kZW5zaXRpZXMsIGVjaG8gPSBGQUxTRX0KYGBgCgoKIyMgVHJpY2t5IENoYXJhY3RlcnMKClNvbWUgZXhhbXBsZXM6CgpgYGB7cn0KKHMgPC0gaGVhZCh3dyR0ZW1wKSkKbmNoYXIocykKc3Vic3RyKHMsIDEsIG5jaGFyKHMpIC0gMykKc3Vic3RyKHMsIDEsIG5jaGFyKHMpIC0gMikKYXMubnVtZXJpYyhzdWJzdHIocywgMSwgbmNoYXIocykgLSAyKSkKYXMubnVtZXJpYygiODIgIikKc3ViKCIgLioiLCAiIiwgcykKYGBgCgpUaGUgcHJvYmxlbSBpcyBfdHdvXyBub24tYXNjaWkgY2hhcmFjdGVycy4KClRoZSBgc3RyaV9lc2NhcGVfdW5pY29kZWAgZnVuY3Rpb24gZnJvbSB0aGUgYHN0cmluZ2lgIHBhY2thZ2UgY2FuIG1ha2UKdGhlc2UgY2hhcmFjdGVycyBtb3JlIHZpc2libGU6CgpgYGB7cn0Kc3RyaW5naTo6c3RyaV9lc2NhcGVfdW5pY29kZShzKQpgYGAKClRoZSB0cm91Ymxlc29tZSBjaGFyYWN0ZXJzIGFyZToKCiogW05vLWJyZWFrIHNwYWNlIFUwMEEwXShodHRwczovL3d3dy5maWxlZm9ybWF0LmluZm8vaW5mby91bmljb2RlL2NoYXIvMDBhMC9pbmRleC5odG0pLgoKKiBbRGVncmVlIHN5bWJvbAogIFUwMEIwXShodHRwczovL3d3dy5maWxlZm9ybWF0LmluZm8vaW5mby91bmljb2RlL2NoYXIvMDBiMC9pbmRleC5odG0pLgoKVXNpbmcgdGhlIHVuaWNvZGUgc3BlY2lmaWNhdGlvbiBmb3IgdGhlIG5vLWJyZWFrIHNwYWNlIGRvZXMgd29yazoKCmBgYHtyfQpzdWIoIlx1MDBhMC4qIiwgIiIsIHMpCmBgYAoKCiMjIFZhcmlhdGlvbnMgaW4gUmVndWxhciBFeHByZXNzaW9uIEVuZ2luZXMKCjwhLS0gTm90ZSBvbiB1bmljb2RlIGRpZ2l0czoKIGh0dHBzOi8vdW5peC5zdGFja2V4Y2hhbmdlLmNvbS9xdWVzdGlvbnMvNDE0MjI2L2RpZmZlcmVuY2UtYmV0d2Vlbi0wLTktZGlnaXQtYW5kLWQKLS0+CgpNYW55IHRvb2xzIGFuZCBsYW5ndWFnZXMgc3VwcG9ydCB3b3JraW5nIHdpdGggcmVndWxhciBleHByZXNzaW9ucy4KClIgc3VwcG9ydHM6CgoqIFRoZSBQT1NJWCBzdGFuZGFyZCBmb3IgX2V4dGVuZGVkIHJlZ3VsYXIgZXhwcmVzc2lvbnNfLiBUaGlzIGlzIHRoZQogIGRlZmF1bHQgZW5naW5lLgoKKiBQZXJsLWNvbXBhdGlibGUgcmVndWxhciBleHByZXNzaW9ucwogIChbUENSRV0oaHR0cHM6Ly9lbi53aWtpcGVkaWEub3JnL3dpa2kvUGVybF9Db21wYXRpYmxlX1JlZ3VsYXJfRXhwcmVzc2lvbnMpKS4KICBUaGlzIGVuZ2luZSBpcyBzZWxlY3RlZCBieSBhZGRpbmcgYHBlcmwgPSBUUlVFYCBpbiBjYWxscyB0bwogIGZ1bmN0aW9ucyB1c2luZyByZWd1bGFyIGV4cHJlc3Npb25zLgoKRGlmZmVyZW50IGVuZ2luZXMgY2FuIGRpZmZlciBpbiBob3cgY2VydGFpbiByZWd1bGFyIGV4cHJlc3Npb25zIGFyZQppbnRlcnByZXRlZCwgZXNwZWNpYWxseSB3aGVuIG5vbi1BU0NJSSBjaGFyYWN0ZXJzIGFyZSBpbnZvbHZlZC4KCkRpZmZlcmVudCBlbmdpbmVzIGFsc28gc29tZXRpbWVzIG9mZmVyIHNob3J0aGFuZCBub3RhdGlvbnMsIGluCnBhcnRpY3VsYXIgZm9yIGNoYXJhY3RlciBjbGFzc2VzLgoKU29tZSBleGFtcGxlczoKCnwgUE9TSVggY2xhc3MgfCAgc2ltaWxhciB0byB8IHNob3J0aGFuZCB8ICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICB8CnwgLS0tLS0tLS0tLS0gfCAtLS0tLS0tLS0tLSB8IC0tLS0tLS0tLSB8IC0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLSB8CnxgWzpkaWdpdDpdYCB8ICBgWzAtOV1gICAgfCAgYFxkYCAgICAgfCAgIGRpZ2l0cyAgICAgICAgICAgICAgICAgICAgICAgfAp8YFs6dXBwZXI6XWAgfCAgIGBbQS1aXWAgIHwgIGBcdWAgICAgIHwgICB1cHBlciBjYXNlIGxldHRlcnMgICAgICAgICAgIHwKfGBbOmxvd2VyOl1gIHwgIGBbYS16XWAgICB8ICBgXGxgICAgICB8ICBsb3dlci1jYXNlIGxldHRlcnMgICAgICAgICAgICB8CnxgWzphbHBoYTpdYCB8ICBgW0EtWmEtel1gfCAgICAgICAgICAgfCAgdXBwZXItIGFuZCBsb3dlci1jYXNlIGxldHRlcnMgfAp8YFs6c3BhY2U6XWAgfCAgYFsgXHRcbl1gIHwgIGBcc2AgICAgIHwgIHdoaXRlc3BhY2UgY2hhcmFjdGVycyAgICAgICAgIHwKClRoZSBzaG9ydGhhbmQgdmVyc2lvbnMgbmVlZCB0byBoYXZlIHRoZWlyIGBcYCBlc2NhcGVkIHdoZW4gdXNlZCBpbiBhbiBSCnN0cmluZzoKCmBgYHtyfQppbnRwYXQgPC0gIi4qXFxzKFstK10/XFxkKykuKiIKc3ViKGludHBhdCwgIlxcMSIsIGMoIlRlbXA6ICAzMkYiLCAiVGVtcDogLTExRiIpKQpgYGAKCgojIyBSYXcgU3RyaW5ncwoKX1JhdyBzdHJpbmdzXyBjYW4gbWFrZSB3cml0aW5nIHJlZ3VsYXIgZXhwcmVzc2lvbnMgYSBsaXR0bGUgZWFzaWVyLgoKSW4gUiBhIHJhdyBzdHJpbmcgaXMgc3BlY2lmaWVkIGFzIGByIiguLi4pImAuCgpUaGUgYC4uLmAgY2hhcmFjdGVycyBjYW4gYmUgYW55IGNoYXJhY3RlcnMgYW5kIGFyZSB0YWtlbiBsaXRlcmFsbHksCndpdGhvdXQgc3BlY2lhbCBpbnRlcnByZXRhdGlvbiB0aGF0IG1pZ2h0IHJlcXVpcmUgZXNjYXBpbmcuCgpGb3IgdGhlIGludGVnZXIgcGF0dGVybjoKCmBgYHtyfQppbnRwYXQgPC0gIi4qXFxzKFstK10/XFxkKykuKiIKaW50cGF0X3JhdyA8LSByIiguKlxzKFstK10/XGQrKS4qKSIKaW50cGF0ID09IGludHBhdF9yYXcKYGBgCgpQeXRob24sIEMrKywgYW5kIG90aGVyIGxhbmd1YWdlcyBwcm92aWRlIHNpbWlsYXIgZmFjaWxpdGVzLgoKUidzIHJhdyBzdHJpbmcgc3ludGF4IGl0IG1vZGVsZWQgYWZ0ZXIgdGhlIG9uZSB1c2VkIGluIEMrKy4KCgojIyBBIE5vdGUgb24gU29ydGluZwoKTm9uLUFTQ0lJIGNoYXJhY3RlcnMgY2FuIGNyZWF0ZSBpc3N1ZXMgZm9yIHNvcnRpbmcgc3RyaW5ncywgYnV0IGV2ZW4KQVNDSUkgY2hhcmFjdGVyIHNvcnQgb3JkZXIgaXMgbm90IHRoZSBzYW1lIGluIGFsbApbbG9jYWxlc10oaHR0cHM6Ly9lbi53aWtpcGVkaWEub3JnL3dpa2kvTGlzdF9vZl9JU09fNjM5LTFfY29kZXMpLgoKVGhlIGBMRVRURVJTYCBkYXRhIHNldCBjb250YWlucyB0aGUgdXBwZXItY2FzZSBsZXR0ZXJzIGluIGFscGhhYmV0aWNhbApvcmRlciBmb3IgdGhlIEVuZ2xpc2ggc29ydGluZyBjb252ZW50aW9uIGFuZCBtb3N0IG90aGVyIGxvY2FsZXM6CgpgYGB7cn0KTEVUVEVSUwpgYGAKCkJ1dCBpbiBFc3RvbmlhbiwgTGF0dmlhbiwgYW5kIExpdGh1YW5pYW46CgpgYGB7cn0Kc3RyaW5ncjo6c3RyX3NvcnQoTEVUVEVSUywgbG9jYWxlID0gImVzdCIpCmBgYAoKT3JkZXJpbmcgb2YgbG93ZXIgY2FzZSBhbmQgdXBwZXIgY2FzZSBsZXR0ZXJzIGluIEVuZ2xpc2ggYW5kIG1vc3Qgb3RoZXIKbG9jYWxlczoKCmBgYHtSfQpzdHJpbmdyOjpzdHJfc29ydChjKCJBIiwgImEiKSwgbG9jYWxlID0gImVuZyIpCmBgYAoKQnV0IGluIERhbmlzaCwgYW5kIGFsc28gTWFsdGVzZToKCmBgYHtSfQpzdHJpbmdyOjpzdHJfc29ydChjKCJBIiwgImEiKSwgbG9jYWxlID0gImRhbiIpCmBgYAoKYGBge3IsIGVjaG8gPSBGQUxTRSwgZXZhbCA9IEZBTFNFfQojIyByZWFkIGEgdGFibGUgZnJvbSBXaWtpcGVkaWEgd2l0aCB0aGUgbG9jYWxlIGFiYnJldmlhdGlvbnMKdXJsIDwtICJodHRwczovL2VuLndpa2lwZWRpYS5vcmcvd2lraS9MaXN0X29mX0lTT182MzktMV9jb2RlcyIKbGlicmFyeShydmVzdCkKbGlicmFyeShkcGx5cikKdyA8LSByZWFkX2h0bWwodXJsKQoKIyMgZGlmZmVyZW50IGxldHRlciBzb3J0IG9yZGVyCnRibCA8LSBodG1sX3RhYmxlKGh0bWxfbm9kZXModywgInRhYmxlIiksIGZpbGwgPSBUUlVFKQpsdGJsIDwtIHRibFtbMl1dCmxjb2RlcyA8LSBsdGJsW1s2XV0KdiA8LSBzYXBwbHkobGNvZGVzLAogICAgICAgICAgICBmdW5jdGlvbihsb2MpCiAgICAgICAgICAgICAgICBpZGVudGljYWwoc3RyaW5ncjo6c3RyX3NvcnQoTEVUVEVSUywgbG9jYWxlID0gbG9jKSwKICAgICAgICAgICAgICAgICAgICAgICAgICBMRVRURVJTKSkKbHRibFshdiwgYygiTGFuZ3VhZ2UgZmFtaWx5IiwgIklTTyBsYW5ndWFnZSBuYW1lIiwgIjYzOS0yL1QiKV0KCiMjIGRpZmZlcmVudCB1cHBlci9sb3dlciBjYXNlIHNvcnQgb3JkZXIKc3MgPC0gYygiYSIsICJBIikKdnYgPC0gc2FwcGx5KGxjb2RlcywKICAgICAgICAgICAgIGZ1bmN0aW9uKGxvYykKICAgICAgICAgICAgICAgIGlkZW50aWNhbChzdHJpbmdyOjpzdHJfc29ydChzcywgbG9jYWxlID0gbG9jKSwKICAgICAgICAgICAgICAgICAgICAgICAgICBzcykpCmx0YmxbIXZ2LCBjKCJMYW5ndWFnZSBmYW1pbHkiLCAiSVNPIGxhbmd1YWdlIG5hbWUiLCAiNjM5LTIvVCIpXQoKYGBgCgoKIyMgRW5jb2RpbmcgSXNzdWVzCgpGaWxlcyBjb250YWluIGEgc2VxdWVuY2Ugb2YgOC1iaXQgaW50ZWdlcnMsIG9yIF9ieXRlc18uCgpUaGVzZSBhcmUgdGhlIGludGVnZXJzIGZyb20gMCB0aHJvdWdoIDI1NS4KCkZvciB0ZXh0IGZpbGVzLCB0aGVzZSBieXRlcyBhcmUgaW50ZXJwcmV0ZWQgYXMgcmVwcmVzZW50aW5nIGNoYXJhY3RlcnMuCgpUaGUgbWFwcGluZyBmcm9tIGJ5dGVzIHRvIGNoYXJhY3RlcnMgaXMgY2FsbGVkIGFuIF9lbmNvZGluZ18uCgpUaGUgZW5jb2RpbmcgZm9yIHRoZSBjaGFyYWN0ZXJzIHVzZWQgaW4gQW1lcmljYW4gRW5nbGlzaCBpcyBBU0NJSToKdGhlIF9BbWVyaWNhbiBTdGFuZGFyZCBDb2RlIGZvciBJbmZvcm1hdGlvbiBJbnRlcmNoYW5nZV8uCgpUaGUgW0FTQ0lJIGVuY29kaW5nXShodHRwczovL2FzY2lpLXRhYmxlcy5jb20vKSB1c2VzIG9ubHkgdGhlCmludGVnZXJzIDAgdGhyb3VnaCAxMjcuCgpUaGUgQVNDSUkgZW5jb2RpbmcgaXMgYWRlcXVhdGUgZm9yIEFtZXJpY2FuIHVzZXM7IGV2ZW4gVUsgdGV4dCBmaWxlcwpuZWVkIG1vcmU6IHRoZSBwb3VuZCBzaWduIMKjLgoKRW5jb2RpbmdzIHRoYXQgdXNlIGludGVnZXJzIDEyOCB0aHJvdWdoIDI1NToKCiogTGF0aW4xIChha2EgSVNPLTg4NTktMSkgZm9yIHdlc3Rlcm4gRXVyb3BlYW4gbGFuZ3VhZ2VzIChpbmNsdWRlcyDCoyk7CgoqIExhdGluMiAoYWthIElTTy04ODU5LTIpIGZvciBlYXN0ZXJuIEV1cm9wZWFuIGxhbmd1YWdlcy4KCk1hbnkgZW5jb2RpbmdzIGFyZSBhdmFpbGFibGUgdG8gc3VwcG9ydCBvdGhlciBhbHBoYWJldHMgYW5kIGNoYXJhY3RlciBzZXRzLgoKRm9ydHVuYXRlbHkgbW9zdCBzeXN0ZW1zIG5vdyB1c2UgW1VuaWNvZGVdKGh0dHBzOi8vaG9tZS51bmljb2RlLm9yZy8pCndpdGggdGhlIFtVVEYtOCBlbmNvZGluZ10oaHR0cHM6Ly9lbi53aWtpcGVkaWEub3JnL3dpa2kvVVRGLTgpIGZvcgpyZXByZXNlbnRpbmcgbm9uLUFTQ0lJIGNoYXJhY3RlcnMuCgpJZiB5b3UgbmVlZCB0byByZWFkIGEgZmlsZSB3aXRoIG5vbi1BU0NJSSBjaGFyYWN0ZXJzIHVzaW5nIGByZWFkLmNzdigpYApvciBzaW1pbGFyIGJhc2UgZnVuY3Rpb25zIGEgZ29vZCBwbGFjZSB0byBzdGFydCBpcyB0byBzcGVjaWZ5CmBlbmNvZGluZyA9ICJVVEYtOCJgLgoKVGhlIGZ1bmN0aW9ucyBpbiB0aGUgYHJlYWRyYCBwYWNrYWdlIGRlZmF1bHQgdG8gYXNzdW1pbmcgdGhlIGVuY29kaW5nCmlzIFVURi04LgoKR2V0dGluZyB0aGUgZW5jb2Rpbmcgd3JvbmcgY2FuIHJlc3VsdCBpbiBhIGZldyBtZXNzZWQgdXAgY2hhcmFjdGVycwpvciBpbiBhbiBlbnRpcmUgc3RyaW5nIGJlaW5nIG1lc3NlZCB1cDoKCmBgYHtyIGluY2x1ZGUgPSBGQUxTRX0KeDEgPC0gIkVsIE5pXHhmMW8gd2FzIHBhcnRpY3VsYXJseSBiYWQgdGhpcyB5ZWFyIgp4MiA8LSAiXHg4Mlx4YjFceDgyXHhmMVx4ODJceGM5XHg4Mlx4YmZceDgyXHhjZCIKYGBgCgpSZWFkaW5nIGZpbGVzIHdpdGhvdXQgc3BlY2lmeWluZyB0aGUgY29ycmVjdCBlbmNvZGluZwptaWdodCBwcm9kdWNlIHN0cmluZ3MgbGlrZQoKYGBge3J9CngxCngyCmBgYAoKSWYgdGhlIGNvcnJlY3QgZW5jb2RpbmcgaXMga25vd24sIHRoZW4gdGhlc2UgY2FuIGJlIGZpeGVkIGFmdGVyIHRoZQpmYWN0IHdpdGggYGljb252KClgOgoKYGBge3J9Cmljb252KHgxLCAiTGF0aW4xIiwgIlVURi04IikKaWNvbnYoeDIsICJTaGlmdC1KSVMiLCAiVVRGLTgiKQpgYGAKClJlLXJlYWRpbmcgdGhlIGZpbGUgd2l0aCB0aGUgcHJvcGVyIGVuY29kaW5nIHNwZWNpZmllZCBtYXkgYmUgYSBiZXR0ZXIKb3B0aW9uLgoKVGhlIGByZWFkcmAgZnVuY3Rpb24gYGd1ZXNzX2VuY29kaW5nKClgIG1heSBoZWxwIGlkZW50aWZ5IHRoZSBjb3JyZWN0CmVuY29kaW5nIGlmIGl0IGlzIG5vdCBzcGVjaWZpZWQgaW4gdGhlIGRhdGEgZG9jdW1lbnRhdGlvbi4KCkhhbmRsaW5nIGVuY29kaW5nIGlzc3VlcyBpbiBSIHVzZWQgdG8gYmUgbW9yZSBjb21wbGljYXRlZCBvbiBXaW5kb3dzLCBidXQKdGhpcyBoYXMgaW1wcm92ZWQgd2l0aCByZWNlbnQgcmVsZWFzZXMgb2YgUi4KCgojIyBGb250cwoKT25jZSB5b3UgaGF2ZSB0aGUgcmlnaHQgZW5jb2RpbmcgZm9yIGNoYXJhY3RlciBkYXRhLCB5b3UgYWxzbyBuZWVkIGEgc2V0Cm9mIGZvbnRzIHNvIHlvdXIgZGF0YSBzaG93cyB1cCBwcm9wZXJseSBpbiB0aGUgY29uc29sZSwgdGhlIGVkaXRvciwgYW5kCmdyYXBocy4KCkZvbnRzIG1heSBhbHJlYWR5IGJlIGluc3RhbGxlZC4KCmBgYHtyfQpjKCJcVXsxZjYwMH0iLCAiXHUzMDQxIiwgIlx1NGEwMCIpCmBgYAoKSWYgZ2x5cGhzIGFyZSBub3QgYXZhaWxhYmwsIHRoZSBjaGFyYWN0ZXJzIG1heSBiZSBzaG93biBpbiB2YXJpb3VzIHdheXMuCgpgYGB7cn0KYygiXFV7MTA1Yjh9IiwgIlx1MzA0MCIpCmBgYAoKSG93IHRvIGluc3RhbGwgZm9udHMgd2lsbCBkZXBlbmQgb24geW91ciBwbGF0Zm9ybS4KCkEgcGxvdCB3aXRoIGVtb2ppczoKYGBge3IsIGNsYXNzLnNvdXJjZSA9ICJmb2xkLWhpZGUifQpkYXRhLmZyYW1lKHggPSAxOjEwLAogICAgICAgICAgIHkgPSBydW5pZigxMCksCiAgICAgICAgICAgeiA9IHNhcHBseSgweDFmNjAwICsgMDo5LAogICAgICAgICAgICAgICAgICAgICAgaW50VG9VdGY4KSkgfD4KZ2dwbG90KGFlcyh4LCB5LCBsYWJlbCA9IHopKSArCiAgICBnZW9tX3RleHQoKQpgYGAKCgojIyBBIE5vdGUgb24gTGluZSBFbmRpbmdzCgpPbiBMaW51eCBhbmQgY3VycmVudCBtYWNPUyBsaW5lcyBvZiB0ZXh0IGluIGZpbGVzIGFyZSB0ZXJtaW5hdGVkIGJ5IGEKX2xpbmUgZmVlZF8gKExGKSBjaGFyYWN0ZXIgYFxuYCBvciBgXHgwYWAuCgpPbiBXaW5kb3dzLCBhbmQgaW4gSFRNTCwgbGluZXMgYXJlIHRlcm1pbmF0ZWQgYnkgYSBfY2FycmlhZ2UgcmV0dXJuXwooQ1IsIGBccmAsIGB4MGRgKSBmb2xsb3dlZCBieSBhIGxpbmVmZWVkIChDUkxGKS4KCk9uIExpbnV4IGFuZCBtYWNPUyB0aGVyZSBpcyBubyBkaWZmZXJlbmNlIGluIHJlYWRpbmcgb3Igd3JpdGluZyB0byBhCmZpbGUgaW4gX3RleHQgbW9kZV8gb3IgX2JpbmFyeSBtb2RlXy4KCk9uIFdpbmRvd3MsIHJlYWRpbmcgaW4gdGV4dCBtb2RlIHRyYW5zbGF0ZXMgZnJvbSBDUkxGIGxpbmUgZW5kaW5ncwp0byBMRiwgYW5kIHdyaXRpbmcgdHJhbnNsYXRlcyBMRiBsaW5lIGVuZGluZ3MgdG8gQ1JMRi4KCk1hbnkgZmlsZSB0cmFuc2ZlciBvcGVyYXRpb25zIHdpbGwgZG8gdGhpcyBjb252ZXJzaW9uLgoKR2l0IHdpbGwgY2hlY2sgb3V0IHRleHQgZmlsZXMgd2l0aCB0aGUgYXBwcm9wcmlhdGUgbGluZSBlbmRpbmdzIGZvcgp0aGUgcGxhdGZvcm0uCgpNb3N0IGhpZ2hlci1sZXZlbCB0b29scyBvbiBMaW51eCB3aWxsIHdvcmsgd2l0aCBDUkxGIGxpbmUgZW5kaW5ncywgYW5kCm9uIFdpbmRvd3Mgd2lsbCB3b3JrIGZvciBMRiBsaW5lIGVuZGluZ3MuCgpPY2Nhc2lvbmFsbHkgeW91IG1heSBzZWUgc29tZSBpc3N1ZXMsIGFuZCBuZWVkIHRvIGZpeCB0aGUgbGluZSBlbmRpbmdzCnlvdXJzZWxmLgoKCiMjIEdldHRpbmcgdGhlIEN1cnJlbnQgVGVtcGVyYXR1cmUgCgpUaGUgdG9vbHMgZGVzY3JpYmVkIGhlcmUgY29tZSBpbiBoYW5keSB3aGVuIHNjcmFwaW5nIGRhdGEgZnJvbSB0aGUgd2ViLgoKVGhpcyBjb2RlIGdldHMgdGhlIFtjdXJyZW50IHRlbXBlcmF0dXJlIGluIElvd2EKQ2l0eV0oaHR0cDovL2ZvcmVjYXN0LndlYXRoZXIuZ292L3ppcGNpdHkucGhwP2lucHV0c3RyaW5nPUlvd2ErQ2l0eSxJQSkKZnJvbSB0aGUgTmF0aW9uYWwgV2VhdGhlciBTZXJ2aWNlOgoKYGBge3IsIGV2YWwgPSBGQUxTRX0KbGlicmFyeSh4bWwyKQp1cmwgPC0gImh0dHA6Ly9mb3JlY2FzdC53ZWF0aGVyLmdvdi96aXBjaXR5LnBocD9pbnB1dHN0cmluZz1Jb3dhK0NpdHksSUEiCnBhZ2UgPC0gcmVhZF9odG1sKHVybCkKeHBhdGggPC0gIi8vcFtAY2xhc3M9XCJteWZvcmVjYXN0LWN1cnJlbnQtbHJnXCJdIgp0ZW1wTm9kZSA8LSB4bWxfZmluZF9maXJzdChwYWdlLCB4cGF0aCkKbm9kZVRleHQgPC0geG1sX3RleHQodGVtcE5vZGUpCmFzLm51bWVyaWMoc3ViKCIoWy0rXT9bWzpkaWdpdDpdXSspLioiLCAiXFwxIiwgbm9kZVRleHQpKQpgYGAKCkFuIGV4YW1wbGUgb2YgY3JlYXRpbmcgYSBjdXJyZW50IHRlbXBlcmF0dXJlIG1hcCBpcyBkZXNjcmliZWQKW2hlcmVdKGByIFdMTksoIndlYXRoZXIuaHRtbCIpYCkuCgoKIyMgUmVhZGluZwoKQ2hhcHRlcnMgW19EYXRhIEltcG9ydF9dKGh0dHBzOi8vcjRkcy5oYWRsZXkubnovZGF0YS1pbXBvcnQuaHRtbCkgYW5kCltfU3RyaW5nc19dKGh0dHBzOi8vcjRkcy5oYWRsZXkubnovc3RyaW5ncy5odG1sKSBpbiBbX1IgZm9yIERhdGEKU2NpZW5jZV9dKGh0dHBzOi8vcjRkcy5oYWRsZXkubnovKS4KCkNoYXB0ZXIgW19TdHJpbmcKcHJvY2Vzc2luZ19dKGh0dHBzOi8vcmFmYWxhYi5kZmNpLmhhcnZhcmQuZWR1L2RzYm9vay1wYXJ0LTEvd3JhbmdsaW5nL3N0cmluZy1wcm9jZXNzaW5nLmh0bWwpCmluIFtfSW50cm9kdWN0aW9uIHRvIERhdGEgU2NpZW5jZTogRGF0YSBBbmFseXNpcyBhbmQgUHJlZGljdGlvbgpBbGdvcml0aG1zIHdpdGggUl9dKGh0dHBzOi8vcmFmYWxhYi5kZmNpLmhhcnZhcmQuZWR1L2RzYm9vay1wYXJ0LTEvKS4KCgojIyBFeGVyY2lzZXMKCjwhLS0KZnJvbSBodHRwczovL3JhZmFsYWIuZ2l0aHViLmlvL2RzYm9vay9zdHJpbmctcHJvY2Vzc2luZy5odG1sI2V4ZXJjaXNlcy00MQotLT4KMS4gQ29tcGxldGUgYWxsIGxlc3NvbnMgYW5kIGV4ZXJjaXNlcyBpbiB0aGUgaHR0cHM6Ly9yZWdleG9uZS5jb20vCiAgIG9ubGluZSBpbnRlcmFjdGl2ZSB0dXRvcmlhbC4KCjIuIENvbnNpZGVyIHRoZSBjb2RlCgogICAgYGBge3IsIGV2YWwgPSBGQUxTRX0KICAgIGxpYnJhcnkodGlkeXZlcnNlKQogICAgZmlsdGVyKG1wZywgZ3JlcGwoLS0tLCBtb2RlbCkpCiAgICBgYGAKCiAgICBGb3Igd2hpY2ggb2YgdGhlIGZvbGxvd2luZyByZWd1bGFyIGV4cHJlc3Npb25zIGluIHBsYWNlIG9mIGAtLS1gIHdpbGwKICAgIHRoaXMgY29kZSByZXR1cm4gdGhlIHN1YnNldCBvZiByb3dzIGZvciBhbGwgbW9kZWxzIHRoYXQgY29udGFpbiBlaXRoZXIKICAgIGA0d2RgIG9yIGBhd2RgIGluIHRoZWlyIG1vZGVsIG5hbWVzPwoKICAgIGEuICJbYTRdd2QgIgogICAgYi4gIlthNF13ZCIKICAgIGMuICI0YXdkIgogICAgZC4gIltbNGFdXXdkIgo=