Cumulative Distribution and Survival Functions
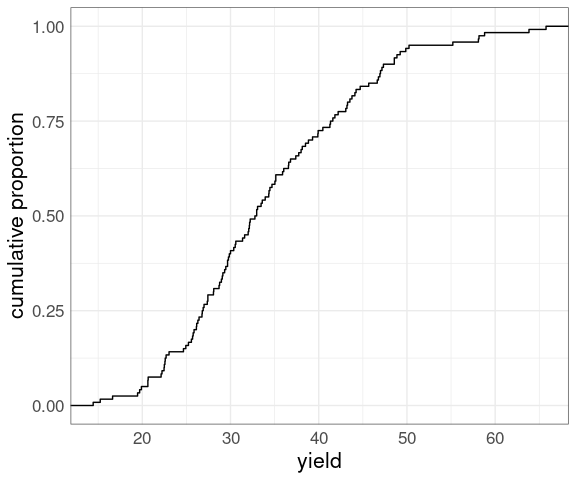
The empirical cumulative distribution function (ECDF) of a numeric sample computes the proportion of the sample at or below a specified value.
For the yields of the barley data:
library(ggplot2)
data(barley, package = "lattice")
thm <- theme_minimal() +
theme(text = element_text(size = 16)) +
theme(panel.border =
element_rect(color = "grey30",
fill = NA))
p <- ggplot(barley) +
stat_ecdf(aes(x = yield)) +
ylab("cumulative proportion") +
thm
p
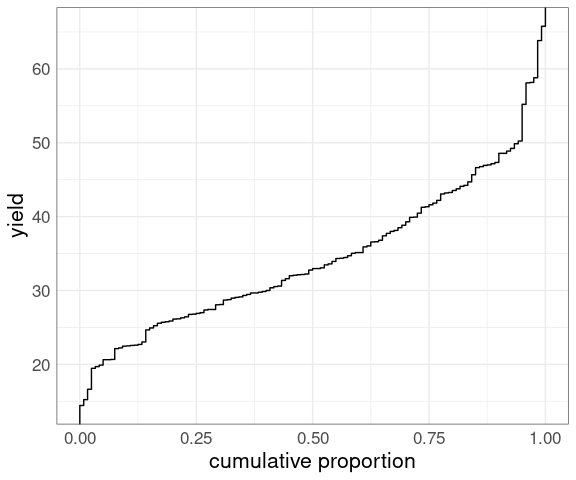
Flipping the axes produces an empirical quantile plot :
p + coord_flip()
Both make it easy to look up:
medians, quartiles, and other quantiles;
the proportion of the sample below a particular value;
the proportion above a particular value (one minus the proportion below).
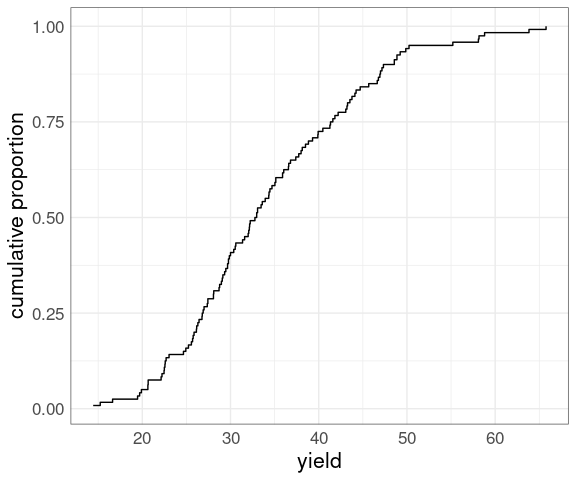
An ECDF plot can also be constructed as a step function plot of the relative rank (rank over sample size) against the observed values:
ggplot(barley) +
geom_step(
aes(x = yield,
y = rank(yield) /
length(yield))) +
ylab("cumulative proportion") +
thm
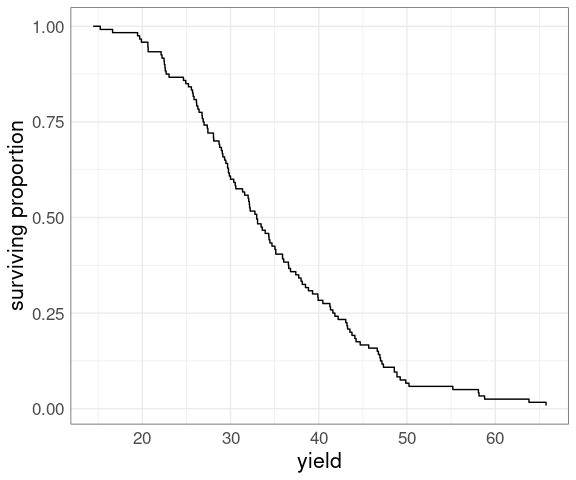
Reversing the relative ranks produces a plot of the empirical survival function :
ggplot(barley) +
geom_step(
aes(x = yield,
y = rank(-yield) /
length(yield))) +
ylab("surviving proportion") +
thm
Survival plots are often used for data representing time to failure in engineering or time to death or disease recurrence in medicine.
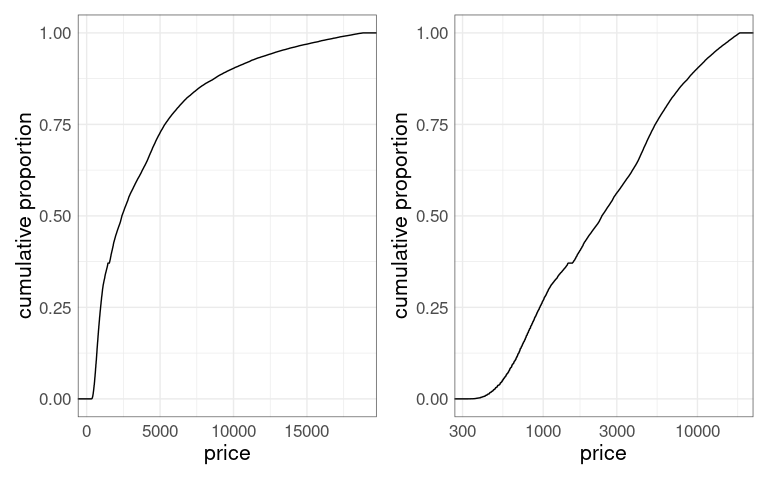
For a highly skewed distribution, such as the distribution of price in the diamonds data, transforming the axis to a square root or log scale may help.
library(patchwork)
p1 <- ggplot(diamonds) +
stat_ecdf(aes(x = price)) +
ylab("cumulative proportion") +
thm
p2 <- p1 + scale_x_log10()
p1 + p2
There is a downside: Interpolating on a non-linear scale is much harder.
QQ Plots
Basics
One way to assess how well a particular theoretical model describes a data distribution is to plot data quantiles against theoretical quantiles.
This corresponds to transforming the ECDF horizontal axis to the scale of the theoretical distribution.
The result is a plot of sample quantiles against theoretical quantiles, and should be close to a 45-degree straight line if the model fits the data well.
Such a plot is called a quantile-quantile plot, or a QQ plot for short.
Usually a QQ plot
uses points rather than a step function, and
1/2 is subtracted from the ranks before calculating relative ranks (this makes the rank range more symmetric):
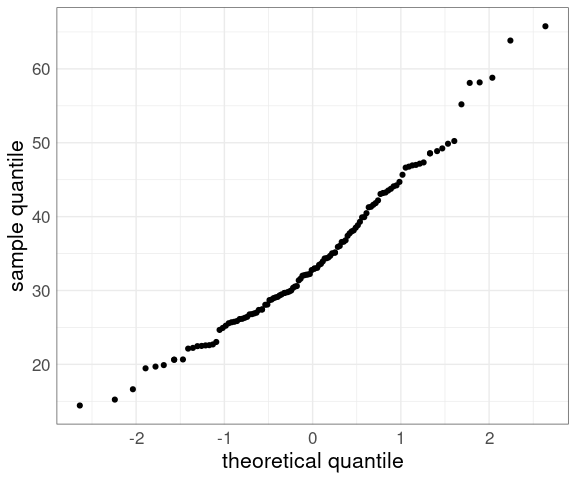
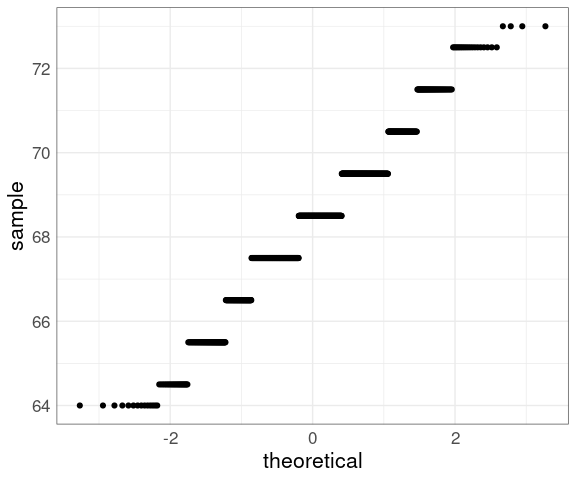
For the barley data:
p <- ggplot(barley) +
geom_point(
aes(y = yield,
x = qnorm((rank(yield) - 0.5) /
length(yield)))) +
xlab("theoretical quantile") +
ylab("sample quantile") +
thm
p
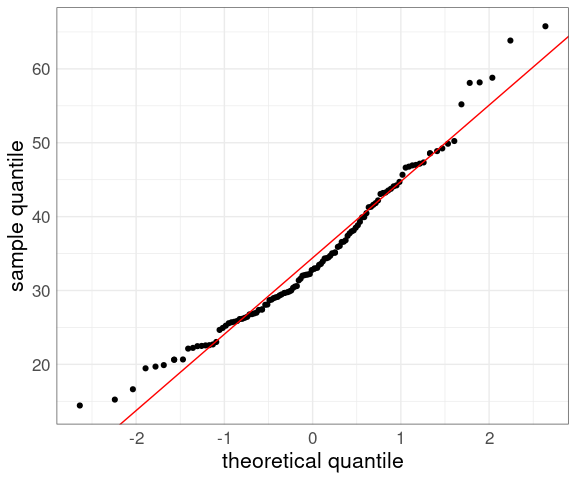
For a location-scale family of models, like the normal family, a QQ plot against standard normal quantiles should be close to a straight line if the model is a good fit.
For the normal family the intercept will be the mean and the slope will be the standard deviation.
Adding a line can help judge the quality of the fit:
p + geom_abline(aes(intercept = mean(yield),
slope = sd(yield)),
color = "red")
ggplot provides geom_qq that makes this a little easier; base graphics provides qqnorm and lattice has qqmath.
Some Examples
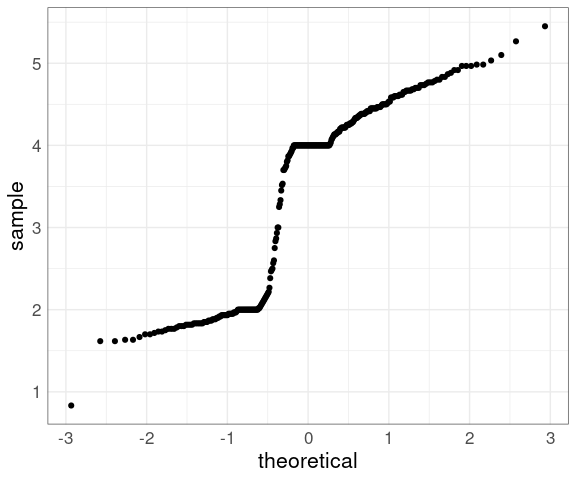
The histograms and density estimates for the duration variable in the geyser data set showed that the distribution is far from a normal distribution, and the normal QQ plot shows this as well:
data(geyser, package = "MASS")
ggplot(geyser) +
geom_qq(aes(sample = duration)) +
thm
Except for rounding the parent heights in the Galton data seemed not too far from normally distributed:
data(Galton, package = "HistData")
ggplot(Galton) +
geom_qq(aes(sample = parent)) +
thm
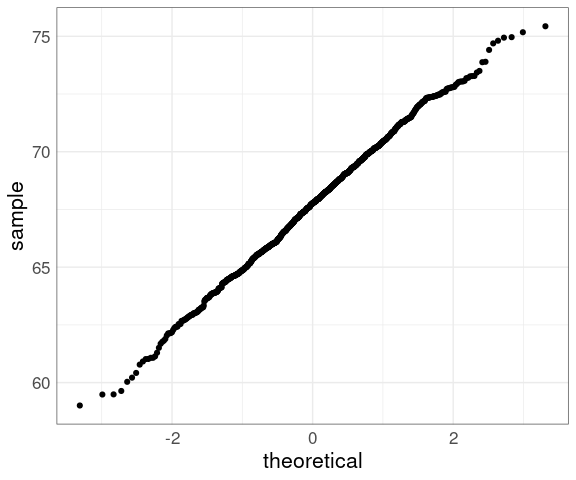
Another Gatlton dataset available in the UsingR package with less rounding is father.son:
data(father.son, package = "UsingR")
ggplot(father.son) +
geom_qq(aes(sample = fheight)) +
thm
The middle seems to be fairly straight, but the ends are somewhat wiggly.
How can you calibrate your judgment?
Calibrating the Variability
One approach is to use simulation, sometimes called a graphical bootstrap .
The nboot function will simulate R samples from a normal distribution that match a variable x on sample size, sample mean, and sample SD.
The result is returned in a data frame suitable for plotting:
library(dplyr)
nsim <- function(n, m = 0, s = 1) {
z <- rnorm(n)
m + s * ((z - mean(z)) / sd(z))
}
nboot <- function(x, R) {
n <- length(x)
m <- mean(x)
s <- sd(x)
sim <- function(i) {
xx <- sort(nsim(n, m, s))
p <- (seq_along(x) - 0.5) / n
data.frame(x = xx, p = p, sim = i)
}
bind_rows(lapply(1 : R, sim))
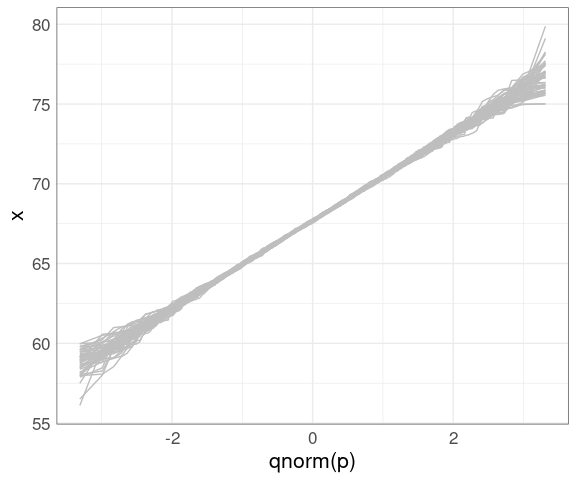
}Plotting these as lines shows the variability in shapes we can expect when sampling from the theoretical normal distribution:
gb <- nboot(father.son$fheight, 50)
ggplot() +
geom_line(aes(x = qnorm(p),
y = x,
group = sim),
color = "gray", data = gb) +
thm
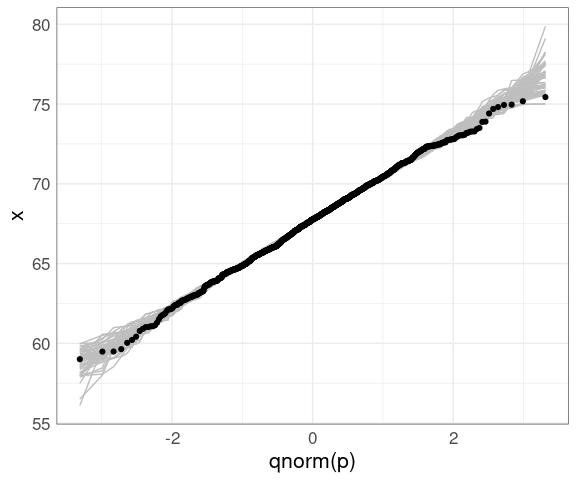
We can then insert this simulation behind our data to help calibrate the visualization:
ggplot(father.son) +
geom_line(aes(x = qnorm(p),
y = x,
group = sim),
color = "gray", data = gb) +
geom_qq(aes(sample = fheight)) +
thm
Scalability
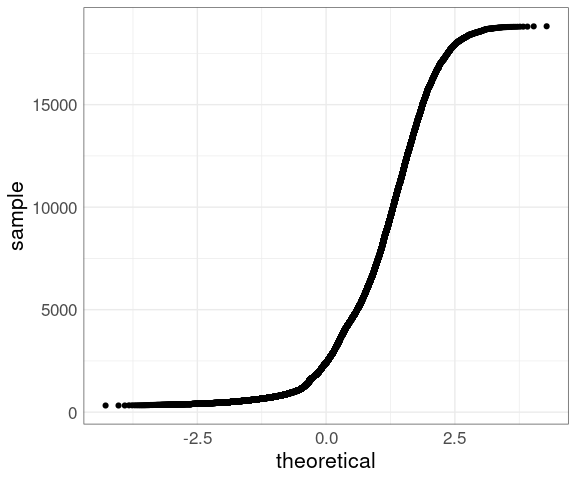
For large sample sizes, such as price from the diamonds data, overplotting will occur:
ggplot(diamonds) +
geom_qq(aes(sample = price)) +
thm
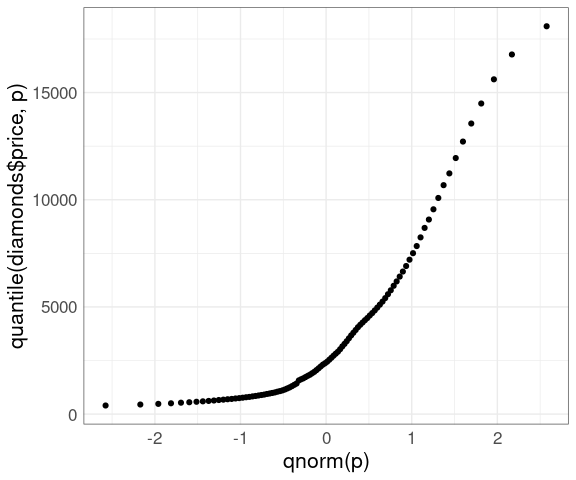
This can be alleviated by using a grid of quantiles:
nq <- 100
p <- ((1 : nq) - 0.5) / nq
ggplot() +
geom_point(aes(x = qnorm(p),
y = quantile(diamonds$price, p))) +
thm
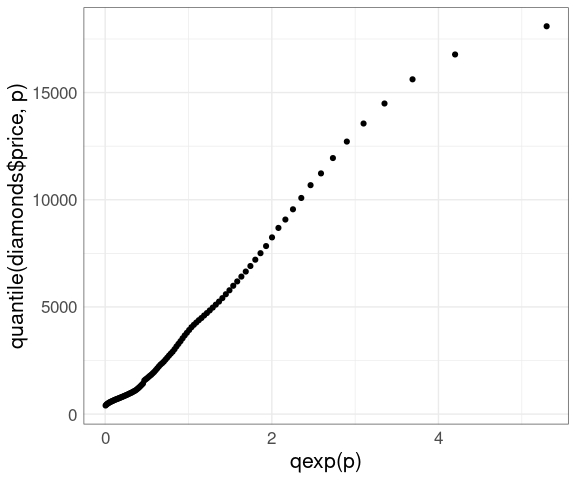
A more reasonable model might be an exponential distribution:
ggplot() +
geom_point(aes(x = qexp(p), y = quantile(diamonds$price, p))) +
thm
Comparing Two Distributions
The QQ plot can also be used to compare two distributions based on a sample from each.
If the samples are the same size then this is just a plot of the ordered sample values against each other.
Choosing a fixed set of quantiles allows samples of unequal size to be compared.
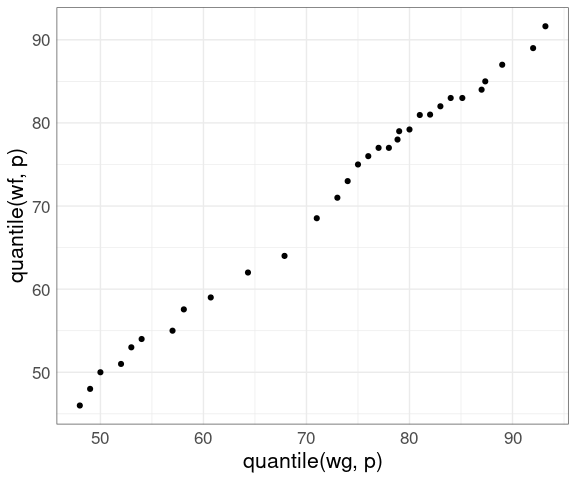
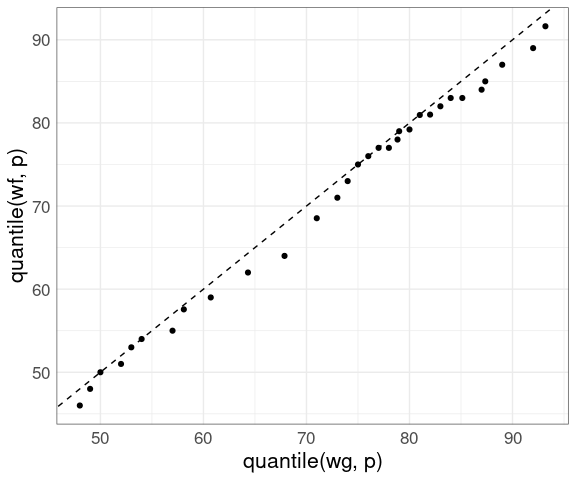
Using a small set of quantiles we can compare the distributions of waiting times between eruptions of Old Faithful from the two different data sets we have looked at:
nq <- 31
p <- (1 : nq) / nq - 0.5 / nq
wg <- geyser$waiting
wf <- faithful$waiting
ggplot() +
geom_point(aes(x = quantile(wg, p),
y = quantile(wf, p))) +
thm
Adding a 45-degree line:
ggplot() +
geom_abline(intercept = 0, slope = 1, lty = 2) +
geom_point(aes(x = quantile(wg, p), y = quantile(wf, p))) +
thm
PP Plots
The PP plot for comparing a sample to a theoretical model plots the theoretical proportion less than or equal to each observed value against the actual proportion.
For a theoretical cumulative distribution function \(F\) this means plotting
\[
F(x_i) \sim p_i
\]
with
\[
p_i = \frac{r_i - 1/2}{n}
\]
where \(r_i\) is the \(i\) -th observation’s rank.
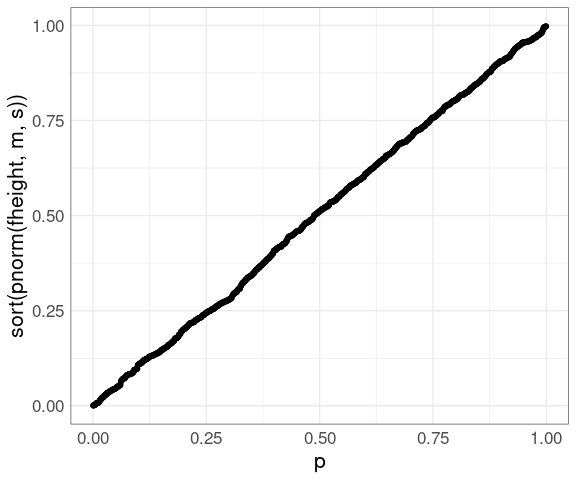
For the fheight variable in the father.son data:
m <- mean(father.son$fheight)
s <- sd(father.son$fheight)
n <- nrow(father.son)
p <- (1 : n) / n - 0.5 / n
ggplot(father.son) +
geom_point(aes(x = p,
y = sort(pnorm(fheight, m, s)))) +
thm
The values on the vertical axis are the probability integral transform of the data for the theoretical distribution.
If the data are a sample from the theoretical distribution then these transforms would be uniformly distributed on \([0, 1]\) .
The PP plot is a QQ plot of these transformed values against a uniform distribution.
The PP plot goes through the points \((0, 0)\) and \((1, 1)\) and so is much less variable in the tails.
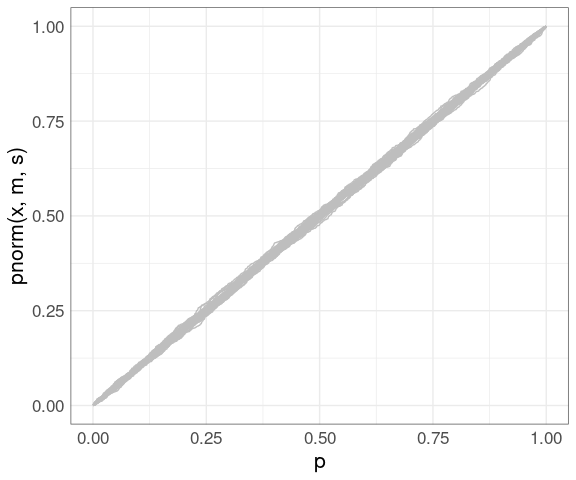
Using the simulated data:
pp <- ggplot() +
geom_line(aes(x = p,
y = pnorm(x, m, s),
group = sim),
color = "gray",
data = gb) +
thm
pp
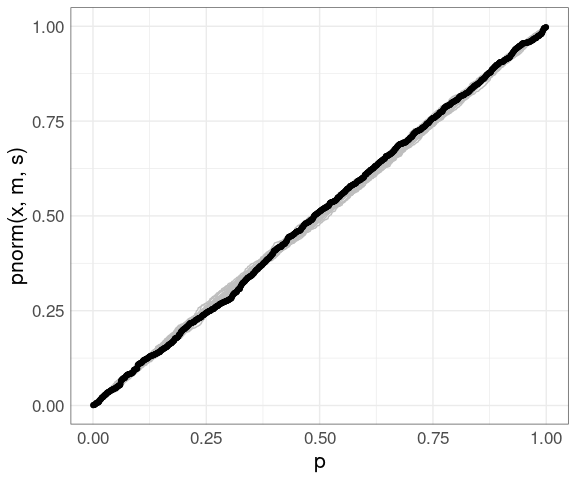
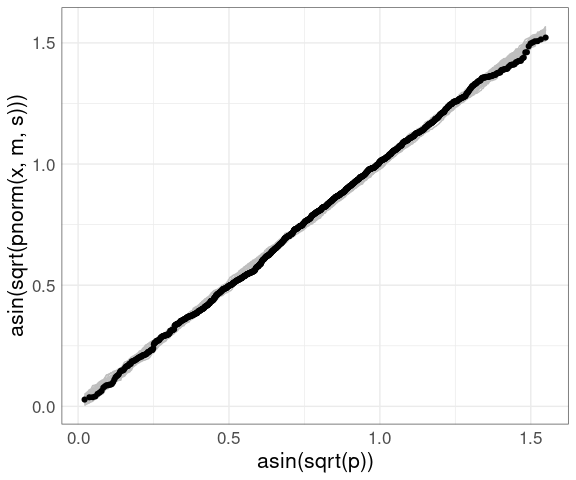
Adding the father.son data:
pp +
geom_point(aes(x = p, y = sort(pnorm(fheight, m, s))), data = (father.son))
The PP plot is also less sensitive to deviations in the tails.
A compromise between the QQ and PP plots uses the arcsine square root variance-stabilizing transformation, which makes the variability approximately constant across the range of the plot:
vpp <- ggplot() +
geom_line(aes(x = asin(sqrt(p)),
y = asin(sqrt(pnorm(x, m, s))),
group = sim),
color = "gray", data = gb) +
thm
vpp
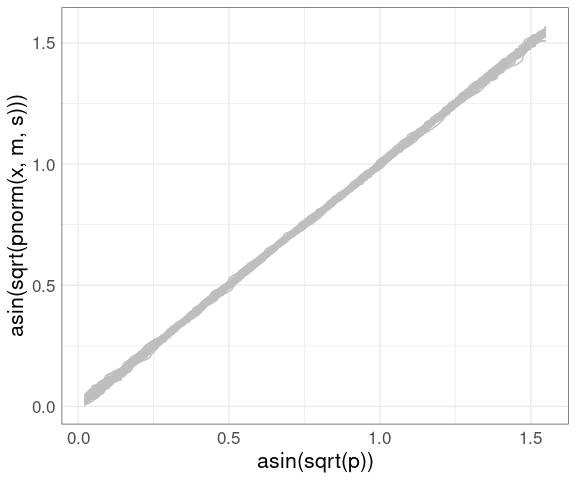
Adding the data:
vpp +
geom_point(
aes(x = asin(sqrt(p)),
y = sort(asin(sqrt(pnorm(fheight, m, s))))),
data = (father.son))
Plots For Assessing Model Fit
Both QQ and PP plots can be used to asses how well a theoretical family of models fits your data, or your residuals.
To use a PP plot you have to estimate the parameters first.
For a location-scale family, like the normal distribution family, you can use a QQ plot with a standard member of the family.
Some other families can use other transformations that lead to straight lines for family members.
The Weibull family is widely used in reliability modeling; its CDF is
\[ F(t) = 1 - \exp\left\(-\left(\frac{t}{b}\right)^a\right\)\]
The logarithms of Weibull random variables form a location-scale family.
Special paper used to be available for Weibull probability plots .
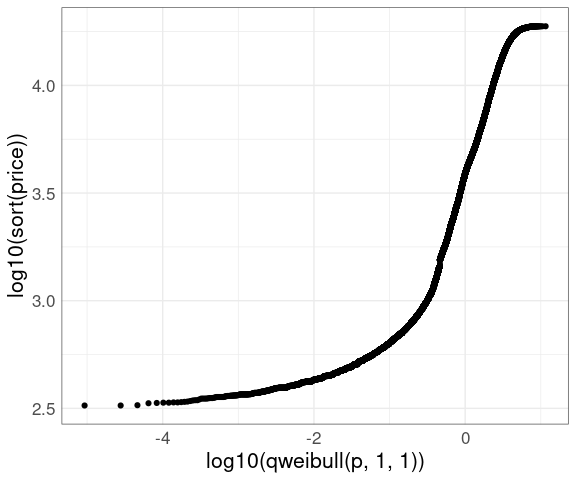
A Weibull QQ plot for price in the diamonds data:
n <- nrow(diamonds)
p <- (1 : n) / n - 0.5 / n
ggplot(diamonds) +
geom_point(aes(x = log10(qweibull(p, 1, 1)), y = log10(sort(price)))) +
thm
The lower tail does not match a Weibull distribution.
Is this important?
In engineering applications it often is.
In selecting a reasonable model to capture the shape of this distribution it may not be.
QQ plots are helpful for understanding departures from a theoretical model.
No data will fit a theoretical model perfectly.
Case-specific judgment is needed to decide whether departures are important.
George Box: All models are wrong but some are useful.
Some References
Adam Loy, Lendie Follett, and Heike Hofmann (2016), “Variations of Q–Q plots: The power of our eyes!”, The American Statistician ; (preprint ).
John R. Michael (1983), “The stabilized probability plot,” Biometrika JSTOR .
M. B. Wilk and R. Gnanadesikan (1968), “Probability plotting methods for the analysis of data,” Biometrika JSTOR .
Box, G. E. P. (1979), “Robustness in the strategy of scientific model building”, in Launer, R. L.; Wilkinson, G. N., Robustness in Statistics , Academic Press, pp. 201–236.
Thomas Lumley (2019), “What have I got against the Shapiro-Wilk test?”
Exercises
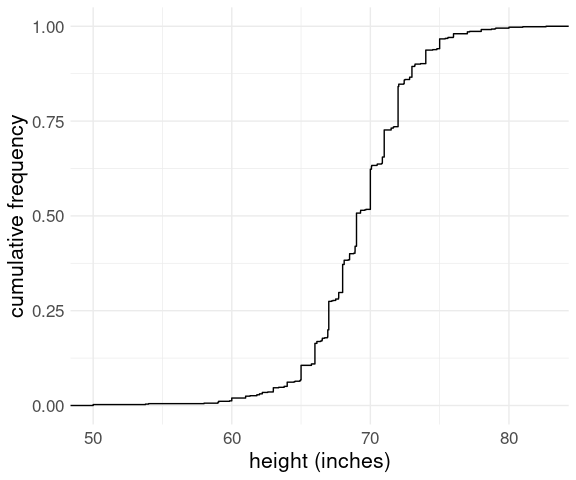
The data set heights in package dslabs contains self-reported heights for a number of female and male students. The plot below shows the empirical CDF for male heights:
Based on the plot, what percentage of males are taller than 75 inches?
100%
15%
20%
3%
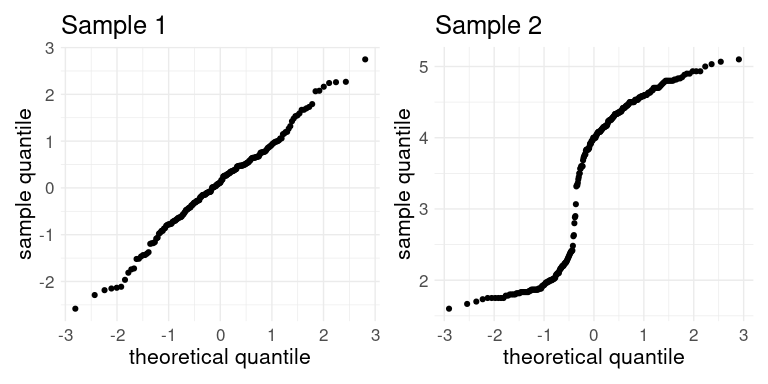
Consider the following normal QQ plots.
library(dplyr)
library(ggplot2)
library(patchwork)
thm <- theme_minimal() + theme(text = element_text(size = 16))
data(heights, package = "dslabs")
set.seed(12345)
p1 <- ggplot(NULL, aes(sample = rnorm(200))) +
geom_qq() +
labs(title = "Sample 1",
x = "theoretical quantile",
y = "sample quantile") +
thm
p2 <- ggplot(faithful, aes(sample = eruptions)) +
geom_qq() +
labs(title = "Sample 2",
x = "theoretical quantile",
y = "sample quantile") +
thm
p1 + p2
Would a normal distribution be a reasonable model for either of these samples?
No for Sample 1. Yes for Sample 2.
Yes for Sample 1. No for Sample 2.
Yes for both.
No for both.
LS0tCnRpdGxlOiAiRUNERiwgUVEsIGFuZCBQUCBQbG90cyIKb3V0cHV0OgogIGh0bWxfZG9jdW1lbnQ6CiAgICB0b2M6IHllcwogICAgY29kZV9mb2xkaW5nOiBzaG93CiAgICBjb2RlX2Rvd25sb2FkOiB0cnVlCi0tLQoKPGxpbmsgcmVsPSJzdHlsZXNoZWV0IiBocmVmPSJzdGF0NDU4MC5jc3MiIHR5cGU9InRleHQvY3NzIiAvPgo8IS0tIHRpdGxlIGJhc2VkIG9uIFdpbGtlJ3MgY2hhcHRlciAtLT4KCmBgYHtyIHNldHVwLCBpbmNsdWRlID0gRkFMU0UsIG1lc3NhZ2UgPSBGQUxTRX0Kc291cmNlKGhlcmU6OmhlcmUoInNldHVwLlIiKSkKa25pdHI6Om9wdHNfY2h1bmskc2V0KGNvbGxhcHNlID0gVFJVRSwgbWVzc2FnZSA9IEZBTFNFLAogICAgICAgICAgICAgICAgICAgICAgZmlnLmhlaWdodCA9IDUsIGZpZy53aWR0aCA9IDYsIGZpZy5hbGlnbiA9ICJjZW50ZXIiKQoKc2V0LnNlZWQoMTIzNDUpCmxpYnJhcnkoZHBseXIpCmxpYnJhcnkoZ2dwbG90MikKbGlicmFyeShsYXR0aWNlKQpsaWJyYXJ5KGdyaWRFeHRyYSkKc291cmNlKGhlcmU6OmhlcmUoImRhdGFzZXRzLlIiKSkKYGBgCgoKIyMgQ3VtdWxhdGl2ZSBEaXN0cmlidXRpb24gYW5kIFN1cnZpdmFsIEZ1bmN0aW9ucwoKVGhlIF9lbXBpcmljYWwgY3VtdWxhdGl2ZSBkaXN0cmlidXRpb24gZnVuY3Rpb25fIChFQ0RGKSBvZiBhIG51bWVyaWMKc2FtcGxlIGNvbXB1dGVzIHRoZSBwcm9wb3J0aW9uIG9mIHRoZSBzYW1wbGUgYXQgb3IgYmVsb3cgYSBzcGVjaWZpZWQKdmFsdWUuCiAgICAKRm9yIHRoZSBgeWllbGRzYCBvZiB0aGUgYGJhcmxleWAgZGF0YToKCmBgYHtyLCBjbGFzcy5zb3VyY2UgPSAiZm9sZC1oaWRlIn0KbGlicmFyeShnZ3Bsb3QyKQpkYXRhKGJhcmxleSwgcGFja2FnZSA9ICJsYXR0aWNlIikKdGhtIDwtIHRoZW1lX21pbmltYWwoKSArCiAgICB0aGVtZSh0ZXh0ID0gZWxlbWVudF90ZXh0KHNpemUgPSAxNikpICsKICAgIHRoZW1lKHBhbmVsLmJvcmRlciA9CiAgICAgICAgICBlbGVtZW50X3JlY3QoY29sb3IgPSAiZ3JleTMwIiwKICAgICAgICAgICAgICAgICAgICAgICBmaWxsID0gTkEpKQpwIDwtIGdncGxvdChiYXJsZXkpICsKICAgIHN0YXRfZWNkZihhZXMoeCA9IHlpZWxkKSkgKwogICAgeWxhYigiY3VtdWxhdGl2ZSBwcm9wb3J0aW9uIikgKwogICAgdGhtCnAKYGBgCgpGbGlwcGluZyB0aGUgYXhlcyBwcm9kdWNlcyBhbiBfZW1waXJpY2FsIHF1YW50aWxlIHBsb3RfOgoKYGBge3IsIGNsYXNzLnNvdXJjZSA9ICJmb2xkLWhpZGUifQpwICsgY29vcmRfZmxpcCgpCmBgYAoKQm90aCBtYWtlIGl0IGVhc3kgdG8gbG9vayB1cDoKCiogbWVkaWFucywgcXVhcnRpbGVzLCBhbmQgb3RoZXIgcXVhbnRpbGVzOwoKKiB0aGUgcHJvcG9ydGlvbiBvZiB0aGUgc2FtcGxlIGJlbG93IGEgcGFydGljdWxhciB2YWx1ZTsKCiogdGhlIHByb3BvcnRpb24gYWJvdmUgYSBwYXJ0aWN1bGFyIHZhbHVlIChvbmUgbWludXMgdGhlIHByb3BvcnRpb24gYmVsb3cpLgoKQW4gRUNERiBwbG90IGNhbiBhbHNvIGJlIGNvbnN0cnVjdGVkIGFzIGEgc3RlcCBmdW5jdGlvbiBwbG90IG9mIHRoZQpfcmVsYXRpdmUgcmFua18gKHJhbmsgb3ZlciBzYW1wbGUgc2l6ZSkgYWdhaW5zdCB0aGUgb2JzZXJ2ZWQgdmFsdWVzOgoKYGBge3IsIGNsYXNzLnNvdXJjZSA9ICJmb2xkLWhpZGUifQpnZ3Bsb3QoYmFybGV5KSArCiAgICBnZW9tX3N0ZXAoCiAgICAgICAgYWVzKHggPSB5aWVsZCwKICAgICAgICAgICAgeSA9IHJhbmsoeWllbGQpIC8KICAgICAgICAgICAgICAgIGxlbmd0aCh5aWVsZCkpKSArCiAgICB5bGFiKCJjdW11bGF0aXZlIHByb3BvcnRpb24iKSArCiAgICB0aG0KYGBgCgpSZXZlcnNpbmcgdGhlIHJlbGF0aXZlIHJhbmtzIHByb2R1Y2VzIGEgcGxvdCBvZiB0aGUgX2VtcGlyaWNhbCBzdXJ2aXZhbApmdW5jdGlvbl86CgpgYGB7cn0KZ2dwbG90KGJhcmxleSkgKwogICAgZ2VvbV9zdGVwKAogICAgICAgIGFlcyh4ID0geWllbGQsCiAgICAgICAgICAgIHkgPSByYW5rKC15aWVsZCkgLwogICAgICAgICAgICAgICAgbGVuZ3RoKHlpZWxkKSkpICsKICAgIHlsYWIoInN1cnZpdmluZyBwcm9wb3J0aW9uIikgKwogICAgdGhtCmBgYAoKU3Vydml2YWwgcGxvdHMgYXJlIG9mdGVuIHVzZWQgZm9yIGRhdGEgcmVwcmVzZW50aW5nIHRpbWUgdG8gZmFpbHVyZQppbiBlbmdpbmVlcmluZyBvciB0aW1lIHRvIGRlYXRoIG9yIGRpc2Vhc2UgcmVjdXJyZW5jZSBpbgptZWRpY2luZS4KCkZvciBhIGhpZ2hseSBza2V3ZWQgZGlzdHJpYnV0aW9uLCBzdWNoIGFzIHRoZSBkaXN0cmlidXRpb24gb2YgYHByaWNlYAppbiB0aGUgYGRpYW1vbmRzYCBkYXRhLCB0cmFuc2Zvcm1pbmcgdGhlIGF4aXMgdG8gYSBzcXVhcmUgcm9vdCBvciBsb2cKc2NhbGUgbWF5IGhlbHAuCgpgYGB7ciwgZmlnLndpZHRoID0gOCwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CmxpYnJhcnkocGF0Y2h3b3JrKQpwMSA8LSBnZ3Bsb3QoZGlhbW9uZHMpICsKICAgIHN0YXRfZWNkZihhZXMoeCA9IHByaWNlKSkgKwogICAgeWxhYigiY3VtdWxhdGl2ZSBwcm9wb3J0aW9uIikgKwogICAgdGhtCnAyIDwtIHAxICsgc2NhbGVfeF9sb2cxMCgpCnAxICsgcDIKYGBgCgpUaGVyZSBpcyBhIGRvd25zaWRlOiBJbnRlcnBvbGF0aW5nIG9uIGEgbm9uLWxpbmVhciBzY2FsZSBpcyBtdWNoIGhhcmRlci4KCgojIyBRUSBQbG90cwoKCiMjIyBCYXNpY3MKCk9uZSB3YXkgdG8gYXNzZXNzIGhvdyB3ZWxsIGEgcGFydGljdWxhciB0aGVvcmV0aWNhbCBtb2RlbCBkZXNjcmliZXMgYQpkYXRhIGRpc3RyaWJ1dGlvbiBpcyB0byBwbG90IGRhdGEgcXVhbnRpbGVzIGFnYWluc3QgdGhlb3JldGljYWwgcXVhbnRpbGVzLgoKVGhpcyBjb3JyZXNwb25kcyB0byB0cmFuc2Zvcm1pbmcgdGhlIEVDREYgaG9yaXpvbnRhbCBheGlzIHRvIHRoZSBzY2FsZSBvZgp0aGUgdGhlb3JldGljYWwgZGlzdHJpYnV0aW9uLgoKVGhlIHJlc3VsdCBpcyBhIHBsb3Qgb2Ygc2FtcGxlIHF1YW50aWxlcyBhZ2FpbnN0IHRoZW9yZXRpY2FsCnF1YW50aWxlcywgYW5kIHNob3VsZCBiZSBjbG9zZSB0byBhIDQ1LWRlZ3JlZSBzdHJhaWdodCBsaW5lIGlmIHRoZQptb2RlbCBmaXRzIHRoZSBkYXRhIHdlbGwuCgpTdWNoIGEgcGxvdCBpcyBjYWxsZWQgYSBxdWFudGlsZS1xdWFudGlsZSBwbG90LCBvciBhIFFRIHBsb3QgZm9yIHNob3J0LgoKVXN1YWxseSBhIFFRIHBsb3QKCiogdXNlcyBwb2ludHMgcmF0aGVyIHRoYW4gYSBzdGVwIGZ1bmN0aW9uLCBhbmQKCiogMS8yIGlzIHN1YnRyYWN0ZWQgZnJvbSB0aGUgcmFua3MgYmVmb3JlIGNhbGN1bGF0aW5nIHJlbGF0aXZlIHJhbmtzICh0aGlzCiAgbWFrZXMgdGhlIHJhbmsgcmFuZ2UgbW9yZSBzeW1tZXRyaWMpOgoKRm9yIHRoZSBgYmFybGV5YCBkYXRhOgoKYGBge3IsIGNsYXNzLnNvdXJjZSA9ICJmb2xkLWhpZGUifQpwIDwtIGdncGxvdChiYXJsZXkpICsKICAgIGdlb21fcG9pbnQoCiAgICAgICAgYWVzKHkgPSB5aWVsZCwKICAgICAgICAgICAgeCA9IHFub3JtKChyYW5rKHlpZWxkKSAtIDAuNSkgLwogICAgICAgICAgICAgICAgICAgICAgbGVuZ3RoKHlpZWxkKSkpKSArCiAgICB4bGFiKCJ0aGVvcmV0aWNhbCBxdWFudGlsZSIpICsKICAgIHlsYWIoInNhbXBsZSBxdWFudGlsZSIpICsKICAgIHRobQpwCmBgYAoKRm9yIGEgbG9jYXRpb24tc2NhbGUgZmFtaWx5IG9mIG1vZGVscywgbGlrZSB0aGUgbm9ybWFsIGZhbWlseSwgYSBRUQpwbG90IGFnYWluc3Qgc3RhbmRhcmQgbm9ybWFsIHF1YW50aWxlcyBzaG91bGQgYmUgY2xvc2UgdG8gYSBzdHJhaWdodApsaW5lIGlmIHRoZSBtb2RlbCBpcyBhIGdvb2QgZml0LgoKRm9yIHRoZSBub3JtYWwgZmFtaWx5IHRoZSBpbnRlcmNlcHQgd2lsbCBiZSB0aGUgbWVhbiBhbmQgdGhlIHNsb3BlCndpbGwgYmUgdGhlIHN0YW5kYXJkIGRldmlhdGlvbi4KCkFkZGluZyBhIGxpbmUgY2FuIGhlbHAganVkZ2UgdGhlIHF1YWxpdHkgb2YgdGhlIGZpdDoKCmBgYHtyLCBjbGFzcy5zb3VyY2UgPSAiZm9sZC1oaWRlIn0KcCArIGdlb21fYWJsaW5lKGFlcyhpbnRlcmNlcHQgPSBtZWFuKHlpZWxkKSwKICAgICAgICAgICAgICAgICAgICBzbG9wZSA9IHNkKHlpZWxkKSksCiAgICAgICAgICAgICAgICBjb2xvciA9ICJyZWQiKQpgYGAKCmBnZ3Bsb3RgIHByb3ZpZGVzIGBnZW9tX3FxYCB0aGF0IG1ha2VzIHRoaXMgYSBsaXR0bGUgZWFzaWVyOyBiYXNlCmdyYXBoaWNzIHByb3ZpZGVzIGBxcW5vcm1gIGFuZCBgbGF0dGljZWAgaGFzIGBxcW1hdGhgLgoKCiMjIyBTb21lIEV4YW1wbGVzCgpUaGUgaGlzdG9ncmFtcyBhbmQgZGVuc2l0eSBlc3RpbWF0ZXMgZm9yIHRoZSBgZHVyYXRpb25gIHZhcmlhYmxlIGluCnRoZSBgZ2V5c2VyYCBkYXRhIHNldCBzaG93ZWQgdGhhdCB0aGUgZGlzdHJpYnV0aW9uIGlzIGZhciBmcm9tIGEKbm9ybWFsIGRpc3RyaWJ1dGlvbiwgYW5kIHRoZSBub3JtYWwgUVEgcGxvdCBzaG93cyB0aGlzIGFzIHdlbGw6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CmRhdGEoZ2V5c2VyLCBwYWNrYWdlID0gIk1BU1MiKQpnZ3Bsb3QoZ2V5c2VyKSArCiAgICBnZW9tX3FxKGFlcyhzYW1wbGUgPSBkdXJhdGlvbikpICsKICAgIHRobQpgYGAKCkV4Y2VwdCBmb3Igcm91bmRpbmcgdGhlIGBwYXJlbnRgIGhlaWdodHMgaW4gdGhlIGBHYWx0b25gIGRhdGEgc2VlbWVkCm5vdCB0b28gZmFyIGZyb20gbm9ybWFsbHkgZGlzdHJpYnV0ZWQ6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CmRhdGEoR2FsdG9uLCBwYWNrYWdlID0gIkhpc3REYXRhIikKZ2dwbG90KEdhbHRvbikgKwogICAgZ2VvbV9xcShhZXMoc2FtcGxlID0gcGFyZW50KSkgKwogICAgdGhtCmBgYAoKKiBSb3VuZGluZyBpbnRlcmZlcmVzIG1vcmUgd2l0aCB0aGlzIHZpc3VhbGl6YXRpb24gdGhhbiB3aXRoIGEgaGlzdG9ncmFtIG9yIGEKICBkZW5zaXR5IHBsb3QuCgoqIFJvdW5kaW5nIGlzIG1vcmUgdmlzaWJsZSB3aXRoIHRoaXMgdmlzdWFsaXphdGlvbiB0aGFuIHdpdGggYSBoaXN0b2dyYW0gb3IgYQogIGRlbnNpdHkgcGxvdC4KCkFub3RoZXIgR2F0bHRvbiBkYXRhc2V0IGF2YWlsYWJsZSBpbiB0aGUgYFVzaW5nUmAgcGFja2FnZSB3aXRoIGxlc3MKcm91bmRpbmcgaXMgYGZhdGhlci5zb25gOgoKYGBge3IsIGNsYXNzLnNvdXJjZSA9ICJmb2xkLWhpZGUifQpkYXRhKGZhdGhlci5zb24sIHBhY2thZ2UgPSAiVXNpbmdSIikKZ2dwbG90KGZhdGhlci5zb24pICsKICAgIGdlb21fcXEoYWVzKHNhbXBsZSA9IGZoZWlnaHQpKSArCiAgICB0aG0KYGBgCgpUaGUgbWlkZGxlIHNlZW1zIHRvIGJlIGZhaXJseSBzdHJhaWdodCwgYnV0IHRoZSBlbmRzIGFyZSBzb21ld2hhdCB3aWdnbHkuCgpIb3cgY2FuIHlvdSBjYWxpYnJhdGUgeW91ciBqdWRnbWVudD8KCgojIyMgQ2FsaWJyYXRpbmcgdGhlIFZhcmlhYmlsaXR5CgpPbmUgYXBwcm9hY2ggaXMgdG8gdXNlIHNpbXVsYXRpb24sIHNvbWV0aW1lcyBjYWxsZWQgYSBfZ3JhcGhpY2FsCmJvb3RzdHJhcF8uCgpUaGUgYG5ib290YCBmdW5jdGlvbiB3aWxsIHNpbXVsYXRlIGBSYCBzYW1wbGVzIGZyb20gYSBub3JtYWwKZGlzdHJpYnV0aW9uIHRoYXQgbWF0Y2ggYSB2YXJpYWJsZSBgeGAgb24gc2FtcGxlIHNpemUsIHNhbXBsZSBtZWFuLAphbmQgc2FtcGxlIFNELgoKVGhlIHJlc3VsdCBpcyByZXR1cm5lZCBpbiBhIGRhdGEgZnJhbWUgc3VpdGFibGUgZm9yIHBsb3R0aW5nOgoKYGBge3IsIG1lc3NhZ2UgPSBGQUxTRX0KbGlicmFyeShkcGx5cikKbnNpbSA8LSBmdW5jdGlvbihuLCBtID0gMCwgcyA9IDEpIHsKICAgIHogPC0gcm5vcm0obikKICAgIG0gKyBzICogKCh6IC0gbWVhbih6KSkgLyBzZCh6KSkKfQoKbmJvb3QgPC0gZnVuY3Rpb24oeCwgUikgewogICAgbiA8LSBsZW5ndGgoeCkKICAgIG0gPC0gbWVhbih4KQogICAgcyA8LSBzZCh4KQogICAgc2ltIDwtIGZ1bmN0aW9uKGkpIHsKICAgICAgICB4eCA8LSBzb3J0KG5zaW0obiwgbSwgcykpCiAgICAgICAgcCA8LSAoc2VxX2Fsb25nKHgpIC0gMC41KSAvIG4KICAgICAgICBkYXRhLmZyYW1lKHggPSB4eCwgcCA9IHAsIHNpbSA9IGkpCiAgICB9CiAgICBiaW5kX3Jvd3MobGFwcGx5KDEgOiBSLCBzaW0pKQp9CmBgYAoKUGxvdHRpbmcgdGhlc2UgYXMgbGluZXMgc2hvd3MgdGhlIHZhcmlhYmlsaXR5IGluIHNoYXBlcyB3ZSBjYW4gZXhwZWN0CndoZW4gc2FtcGxpbmcgZnJvbSB0aGUgdGhlb3JldGljYWwgbm9ybWFsIGRpc3RyaWJ1dGlvbjoKCmBgYHtyLCBjbGFzcy5zb3VyY2UgPSAiZm9sZC1oaWRlIn0KZ2IgPC0gbmJvb3QoZmF0aGVyLnNvbiRmaGVpZ2h0LCA1MCkKZ2dwbG90KCkgKwogICAgZ2VvbV9saW5lKGFlcyh4ID0gcW5vcm0ocCksCiAgICAgICAgICAgICAgICAgIHkgPSB4LAogICAgICAgICAgICAgICAgICBncm91cCA9IHNpbSksCiAgICAgICAgICAgICAgY29sb3IgPSAiZ3JheSIsIGRhdGEgPSBnYikgKwogICAgdGhtCmBgYAoKV2UgY2FuIHRoZW4gaW5zZXJ0IHRoaXMgc2ltdWxhdGlvbiBiZWhpbmQgb3VyIGRhdGEgdG8gaGVscCBjYWxpYnJhdGUKdGhlIHZpc3VhbGl6YXRpb246CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CmdncGxvdChmYXRoZXIuc29uKSArCiAgICBnZW9tX2xpbmUoYWVzKHggPSBxbm9ybShwKSwKICAgICAgICAgICAgICAgICAgeSA9IHgsCiAgICAgICAgICAgICAgICAgIGdyb3VwID0gc2ltKSwKICAgICAgICAgICAgICBjb2xvciA9ICJncmF5IiwgZGF0YSA9IGdiKSArCiAgICBnZW9tX3FxKGFlcyhzYW1wbGUgPSBmaGVpZ2h0KSkgKwogICAgdGhtCmBgYAoKCiMjIyBTY2FsYWJpbGl0eQoKRm9yIGxhcmdlIHNhbXBsZSBzaXplcywgc3VjaCBhcyBgcHJpY2VgIGZyb20gdGhlIGBkaWFtb25kc2AgZGF0YSwKb3ZlcnBsb3R0aW5nIHdpbGwgb2NjdXI6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CmdncGxvdChkaWFtb25kcykgKwogICAgZ2VvbV9xcShhZXMoc2FtcGxlID0gcHJpY2UpKSArCiAgICB0aG0KYGBgCgpUaGlzIGNhbiBiZSBhbGxldmlhdGVkIGJ5IHVzaW5nIGEgZ3JpZCBvZiBxdWFudGlsZXM6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9Cm5xIDwtIDEwMApwIDwtICgoMSA6IG5xKSAtIDAuNSkgLyBucQpnZ3Bsb3QoKSArCiAgICBnZW9tX3BvaW50KGFlcyh4ID0gcW5vcm0ocCksCiAgICAgICAgICAgICAgICAgICB5ID0gcXVhbnRpbGUoZGlhbW9uZHMkcHJpY2UsIHApKSkgKwogICAgdGhtCmBgYAoKQSBtb3JlIHJlYXNvbmFibGUgbW9kZWwgbWlnaHQgYmUgYW4gZXhwb25lbnRpYWwgZGlzdHJpYnV0aW9uOgoKYGBge3J9CmdncGxvdCgpICsKICAgIGdlb21fcG9pbnQoYWVzKHggPSBxZXhwKHApLCB5ID0gcXVhbnRpbGUoZGlhbW9uZHMkcHJpY2UsIHApKSkgKwogICAgdGhtCmBgYAoKCiMjIyBDb21wYXJpbmcgVHdvIERpc3RyaWJ1dGlvbnMKClRoZSBRUSBwbG90IGNhbiBhbHNvIGJlIHVzZWQgdG8gY29tcGFyZSB0d28gZGlzdHJpYnV0aW9ucyBiYXNlZCBvbiBhCnNhbXBsZSBmcm9tIGVhY2guCgpJZiB0aGUgc2FtcGxlcyBhcmUgdGhlIHNhbWUgc2l6ZSB0aGVuIHRoaXMgaXMganVzdCBhIHBsb3Qgb2YgdGhlCm9yZGVyZWQgc2FtcGxlIHZhbHVlcyBhZ2FpbnN0IGVhY2ggb3RoZXIuCgpDaG9vc2luZyBhIGZpeGVkIHNldCBvZiBxdWFudGlsZXMgYWxsb3dzIHNhbXBsZXMgb2YgdW5lcXVhbCBzaXplIHRvIGJlCmNvbXBhcmVkLgoKVXNpbmcgYSBzbWFsbCBzZXQgb2YgcXVhbnRpbGVzIHdlIGNhbiBjb21wYXJlIHRoZSBkaXN0cmlidXRpb25zIG9mCndhaXRpbmcgdGltZXMgYmV0d2VlbiBlcnVwdGlvbnMgb2YgT2xkIEZhaXRoZnVsIGZyb20gdGhlIHR3byBkaWZmZXJlbnQKZGF0YSBzZXRzIHdlIGhhdmUgbG9va2VkIGF0OgoKYGBge3IsIGNsYXNzLnNvdXJjZSA9ICJmb2xkLWhpZGUifQpucSA8LSAzMQpwIDwtICgxIDogbnEpIC8gbnEgLSAwLjUgLyBucQp3ZyA8LSBnZXlzZXIkd2FpdGluZwp3ZiA8LSBmYWl0aGZ1bCR3YWl0aW5nCmdncGxvdCgpICsKICAgIGdlb21fcG9pbnQoYWVzKHggPSBxdWFudGlsZSh3ZywgcCksCiAgICAgICAgICAgICAgICAgICB5ID0gcXVhbnRpbGUod2YsIHApKSkgKwogICAgdGhtCmBgYAoKQWRkaW5nIGEgNDUtZGVncmVlIGxpbmU6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CmdncGxvdCgpICsKICAgIGdlb21fYWJsaW5lKGludGVyY2VwdCA9IDAsIHNsb3BlID0gMSwgbHR5ID0gMikgKwogICAgZ2VvbV9wb2ludChhZXMoeCA9IHF1YW50aWxlKHdnLCBwKSwgeSA9IHF1YW50aWxlKHdmLCBwKSkpICsKICAgIHRobQpgYGAKCgojIyBQUCBQbG90cwoKVGhlIFBQIHBsb3QgZm9yIGNvbXBhcmluZyBhIHNhbXBsZSB0byBhIHRoZW9yZXRpY2FsIG1vZGVsIHBsb3RzIHRoZQp0aGVvcmV0aWNhbCBwcm9wb3J0aW9uIGxlc3MgdGhhbiBvciBlcXVhbCB0byBlYWNoIG9ic2VydmVkIHZhbHVlCmFnYWluc3QgdGhlIGFjdHVhbCBwcm9wb3J0aW9uLgoKRm9yIGEgdGhlb3JldGljYWwgY3VtdWxhdGl2ZSBkaXN0cmlidXRpb24gZnVuY3Rpb24gJEYkIHRoaXMgbWVhbnMgcGxvdHRpbmcKCiQkCkYoeF9pKSBcc2ltIHBfaQokJAoKd2l0aAoKJCQKcF9pID0gXGZyYWN7cl9pIC0gMS8yfXtufQokJAoKd2hlcmUgJHJfaSQgaXMgdGhlICRpJC10aCBvYnNlcnZhdGlvbidzIHJhbmsuCgpGb3IgdGhlIGBmaGVpZ2h0YCB2YXJpYWJsZSBpbiB0aGUgYGZhdGhlci5zb25gIGRhdGE6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9Cm0gPC0gbWVhbihmYXRoZXIuc29uJGZoZWlnaHQpCnMgPC0gc2QoZmF0aGVyLnNvbiRmaGVpZ2h0KQpuIDwtIG5yb3coZmF0aGVyLnNvbikKcCA8LSAoMSA6IG4pIC8gbiAtIDAuNSAvIG4KZ2dwbG90KGZhdGhlci5zb24pICsKICAgIGdlb21fcG9pbnQoYWVzKHggPSBwLAogICAgICAgICAgICAgICAgICAgeSA9IHNvcnQocG5vcm0oZmhlaWdodCwgbSwgcykpKSkgKwogICAgdGhtCmBgYAoKKiBUaGUgdmFsdWVzIG9uIHRoZSB2ZXJ0aWNhbCBheGlzIGFyZSB0aGUgX3Byb2JhYmlsaXR5IGludGVncmFsCiAgdHJhbnNmb3JtXyBvZiB0aGUgZGF0YSBmb3IgdGhlIHRoZW9yZXRpY2FsIGRpc3RyaWJ1dGlvbi4KCiogSWYgdGhlIGRhdGEgYXJlIGEgc2FtcGxlIGZyb20gdGhlIHRoZW9yZXRpY2FsIGRpc3RyaWJ1dGlvbiB0aGVuCiAgdGhlc2UgdHJhbnNmb3JtcyB3b3VsZCBiZSB1bmlmb3JtbHkgZGlzdHJpYnV0ZWQgb24gJFswLCAxXSQuCgoqIFRoZSBQUCBwbG90IGlzIGEgUVEgcGxvdCBvZiB0aGVzZSB0cmFuc2Zvcm1lZCB2YWx1ZXMgYWdhaW5zdCBhCiAgdW5pZm9ybSBkaXN0cmlidXRpb24uCgoqIFRoZSBQUCBwbG90IGdvZXMgdGhyb3VnaCB0aGUgcG9pbnRzICQoMCwgMCkkIGFuZCAkKDEsIDEpJCBhbmQgc28gaXMKICBtdWNoIGxlc3MgdmFyaWFibGUgaW4gdGhlIHRhaWxzLgoKVXNpbmcgdGhlIHNpbXVsYXRlZCBkYXRhOgoKYGBge3IsIGNsYXNzLnNvdXJjZSA9ICJmb2xkLWhpZGUifQpwcCA8LSBnZ3Bsb3QoKSArCiAgICBnZW9tX2xpbmUoYWVzKHggPSBwLAogICAgICAgICAgICAgICAgICB5ID0gcG5vcm0oeCwgbSwgcyksCiAgICAgICAgICAgICAgICAgIGdyb3VwID0gc2ltKSwKICAgICAgICAgICAgICBjb2xvciA9ICJncmF5IiwKICAgICAgICAgICAgICBkYXRhID0gZ2IpICsKICAgIHRobQpwcApgYGAKCkFkZGluZyB0aGUgYGZhdGhlci5zb25gIGRhdGE6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CnBwICsKICAgIGdlb21fcG9pbnQoYWVzKHggPSBwLCB5ID0gc29ydChwbm9ybShmaGVpZ2h0LCBtLCBzKSkpLCBkYXRhID0gKGZhdGhlci5zb24pKQpgYGAKClRoZSBQUCBwbG90IGlzIGFsc28gbGVzcyBzZW5zaXRpdmUgdG8gZGV2aWF0aW9ucyBpbiB0aGUgdGFpbHMuCgpBIGNvbXByb21pc2UgYmV0d2VlbiB0aGUgUVEgYW5kIFBQIHBsb3RzIHVzZXMgdGhlIF9hcmNzaW5lIHNxdWFyZSByb290Xwp2YXJpYW5jZS1zdGFiaWxpemluZyB0cmFuc2Zvcm1hdGlvbiwgd2hpY2ggbWFrZXMgdGhlIHZhcmlhYmlsaXR5CmFwcHJveGltYXRlbHkgY29uc3RhbnQgYWNyb3NzIHRoZSByYW5nZSBvZiB0aGUgcGxvdDoKCmBgYHtyLCBjbGFzcy5zb3VyY2UgPSAiZm9sZC1oaWRlIn0KdnBwIDwtIGdncGxvdCgpICsKICAgIGdlb21fbGluZShhZXMoeCA9IGFzaW4oc3FydChwKSksCiAgICAgICAgICAgICAgICAgIHkgPSBhc2luKHNxcnQocG5vcm0oeCwgbSwgcykpKSwKICAgICAgICAgICAgICAgICAgZ3JvdXAgPSBzaW0pLAogICAgICAgICAgICAgIGNvbG9yID0gImdyYXkiLCBkYXRhID0gZ2IpICsKICAgIHRobQp2cHAKYGBgCgpBZGRpbmcgdGhlIGRhdGE6CgpgYGB7ciwgY2xhc3Muc291cmNlID0gImZvbGQtaGlkZSJ9CnZwcCArCiAgICBnZW9tX3BvaW50KAogICAgICAgIGFlcyh4ID0gYXNpbihzcXJ0KHApKSwKICAgICAgICAgICAgeSA9IHNvcnQoYXNpbihzcXJ0KHBub3JtKGZoZWlnaHQsIG0sIHMpKSkpKSwKICAgICAgICBkYXRhID0gKGZhdGhlci5zb24pKQpgYGAKCgojIyBQbG90cyBGb3IgQXNzZXNzaW5nIE1vZGVsIEZpdAoKQm90aCBRUSBhbmQgUFAgcGxvdHMgY2FuIGJlIHVzZWQgdG8gYXNzZXMgaG93IHdlbGwgYSB0aGVvcmV0aWNhbApmYW1pbHkgb2YgbW9kZWxzIGZpdHMgeW91ciBkYXRhLCBvciB5b3VyIHJlc2lkdWFscy4KClRvIHVzZSBhIFBQIHBsb3QgeW91IGhhdmUgdG8gZXN0aW1hdGUgdGhlIHBhcmFtZXRlcnMgZmlyc3QuCgpGb3IgYSBsb2NhdGlvbi1zY2FsZSBmYW1pbHksIGxpa2UgdGhlIG5vcm1hbCBkaXN0cmlidXRpb24gZmFtaWx5LCB5b3UKY2FuIHVzZSBhIFFRIHBsb3Qgd2l0aCBhIHN0YW5kYXJkIG1lbWJlciBvZiB0aGUgZmFtaWx5LgoKU29tZSBvdGhlciBmYW1pbGllcyBjYW4gdXNlIG90aGVyIHRyYW5zZm9ybWF0aW9ucyB0aGF0IGxlYWQgdG8Kc3RyYWlnaHQgbGluZXMgZm9yIGZhbWlseSBtZW1iZXJzLgoKVGhlIFdlaWJ1bGwgZmFtaWx5IGlzIHdpZGVseSB1c2VkIGluIHJlbGlhYmlsaXR5IG1vZGVsaW5nOyBpdHMKQ0RGIGlzCgokJCBGKHQpID0gMSAtIFxleHBcbGVmdFwoLVxsZWZ0KFxmcmFje3R9e2J9XHJpZ2h0KV5hXHJpZ2h0XCkkJAoKVGhlIGxvZ2FyaXRobXMgb2YgV2VpYnVsbCByYW5kb20gdmFyaWFibGVzIGZvcm0gYSBsb2NhdGlvbi1zY2FsZQpmYW1pbHkuCgpTcGVjaWFsIHBhcGVyIHVzZWQgdG8gYmUgYXZhaWxhYmxlIGZvciBbV2VpYnVsbCBwcm9iYWJpbGl0eQpwbG90c10oaHR0cHM6Ly93ZWIuYXJjaGl2ZS5vcmcvd2ViLzIwMTMwMjA3MDcxODI1L2h0dHBzOi8vd2VpYnVsbC5jb20vaG90d2lyZS9pc3N1ZTgvcmVsYmFzaWNzOC5odG0pLgoKQSBXZWlidWxsIFFRIHBsb3QgZm9yIGBwcmljZWAgaW4gdGhlIGBkaWFtb25kc2AgZGF0YToKCmBgYHtyLCBjbGFzcy5zb3VyY2UgPSAiZm9sZC1oaWRlIn0KbiA8LSBucm93KGRpYW1vbmRzKQpwIDwtICgxIDogbikgLyBuIC0gMC41IC8gbgpnZ3Bsb3QoZGlhbW9uZHMpICsKICAgIGdlb21fcG9pbnQoYWVzKHggPSBsb2cxMChxd2VpYnVsbChwLCAxLCAxKSksIHkgPSBsb2cxMChzb3J0KHByaWNlKSkpKSArCiAgICB0aG0KYGBgCgpUaGUgbG93ZXIgdGFpbCBkb2VzIG5vdCBtYXRjaCBhIFdlaWJ1bGwgZGlzdHJpYnV0aW9uLgoKSXMgdGhpcyBpbXBvcnRhbnQ/CgpJbiBlbmdpbmVlcmluZyBhcHBsaWNhdGlvbnMgaXQgb2Z0ZW4gaXMuCgpJbiBzZWxlY3RpbmcgYSByZWFzb25hYmxlIG1vZGVsIHRvIGNhcHR1cmUgdGhlIHNoYXBlIG9mIHRoaXMKZGlzdHJpYnV0aW9uIGl0IG1heSBub3QgYmUuCgpRUSBwbG90cyBhcmUgaGVscGZ1bCBmb3IgdW5kZXJzdGFuZGluZyBkZXBhcnR1cmVzIGZyb20gYSB0aGVvcmV0aWNhbAptb2RlbC4KCk5vIGRhdGEgd2lsbCBmaXQgYSB0aGVvcmV0aWNhbCBtb2RlbCBwZXJmZWN0bHkuCgpDYXNlLXNwZWNpZmljIGp1ZGdtZW50IGlzIG5lZWRlZCB0byBkZWNpZGUgd2hldGhlciBkZXBhcnR1cmVzIGFyZQppbXBvcnRhbnQuCgo+IEdlb3JnZSBCb3g6IEFsbCBtb2RlbHMgYXJlIHdyb25nIGJ1dCBzb21lIGFyZSB1c2VmdWwuCgoKIyMgU29tZSBSZWZlcmVuY2VzCgpBZGFtIExveSwgTGVuZGllIEZvbGxldHQsIGFuZCBIZWlrZSBIb2ZtYW5uICgyMDE2KSwgIlZhcmlhdGlvbnMgb2YgUeKAk1EKcGxvdHM6IFRoZSBwb3dlciBvZiBvdXIgZXllcyEiLCBfVGhlIEFtZXJpY2FuIFN0YXRpc3RpY2lhbl87CihbcHJlcHJpbnRdKGh0dHBzOi8vYXJ4aXYub3JnL2Ficy8xNTAzLjAyMDk4KSkuCgpKb2huIFIuIE1pY2hhZWwgKDE5ODMpLCAiVGhlIHN0YWJpbGl6ZWQgcHJvYmFiaWxpdHkgcGxvdCwiIF9CaW9tZXRyaWthXwpbSlNUT1JdKGh0dHBzOi8vd3d3LmpzdG9yLm9yZy9zdGFibGUvMjMzNTkzOT9zZXE9MSNwYWdlX3NjYW5fdGFiX2NvbnRlbnRzKS4KCk0uIEIuIFdpbGsgYW5kIFIuIEduYW5hZGVzaWthbiAoMTk2OCksICJQcm9iYWJpbGl0eSBwbG90dGluZyBtZXRob2RzCmZvciB0aGUgYW5hbHlzaXMgb2YgZGF0YSwiIF9CaW9tZXRyaWthXwpbSlNUT1JdKGh0dHBzOi8vd3d3LmpzdG9yLm9yZy9zdGFibGUvMjMzNDQ0OD9zZXE9MSNwYWdlX3NjYW5fdGFiX2NvbnRlbnRzKS4KCkJveCwgRy4gRS4gUC4gKDE5NzkpLCAiUm9idXN0bmVzcyBpbiB0aGUgc3RyYXRlZ3kgb2Ygc2NpZW50aWZpYyBtb2RlbApidWlsZGluZyIsIGluIExhdW5lciwgUi4gTC47IFdpbGtpbnNvbiwgRy4gTi4sIF9Sb2J1c3RuZXNzIGluClN0YXRpc3RpY3NfLCBBY2FkZW1pYyBQcmVzcywgcHAuIDIwMeKAkzIzNi4KClRob21hcyBMdW1sZXkgKDIwMTkpLCBbIldoYXQgaGF2ZSBJIGdvdCBhZ2FpbnN0IHRoZSBTaGFwaXJvLVdpbGsKdGVzdD8iXShodHRwczovL25vdHN0YXRzY2hhdC5yYmluZC5pby8yMDE5LzAyLzA5L3doYXQtaGF2ZS1pLWdvdC1hZ2FpbnN0LXRoZS1zaGFwaXJvLXdpbGstdGVzdC8pCgoKIyMgUmVhZGluZ3MKCkNoYXB0ZXIgW19WaXN1YWxpemluZyBkaXN0cmlidXRpb25zOiBFbXBpcmljYWwgY3VtdWxhdGl2ZSBkaXN0cmlidXRpb24KICBmdW5jdGlvbnMgYW5kIHEtcQogIHBsb3RzX10oaHR0cHM6Ly9jbGF1c3dpbGtlLmNvbS9kYXRhdml6L2VjZGYtcXEuaHRtbCkgaW4KICBbX0Z1bmRhbWVudGFscyBvZiBEYXRhCiAgVmlzdWFsaXphdGlvbl9dKGh0dHBzOi8vY2xhdXN3aWxrZS5jb20vZGF0YXZpei8pLgoKCiMjIEV4ZXJjaXNlcwoKMS4gVGhlIGRhdGEgc2V0IGBoZWlnaHRzYCBpbiBwYWNrYWdlIGBkc2xhYnNgIGNvbnRhaW5zIHNlbGYtcmVwb3J0ZWQKICAgIGhlaWdodHMgZm9yIGEgbnVtYmVyIG9mIGZlbWFsZSBhbmQgbWFsZSBzdHVkZW50cy4gVGhlIHBsb3QgYmVsb3cKICAgIHNob3dzIHRoZSBlbXBpcmljYWwgQ0RGIGZvciBtYWxlIGhlaWdodHM6CgogICAgYGBge3IsIGVjaG8gPSBGQUxTRSwgbWVzc2FnZSA9IEZBTFNFfQogICAgbGlicmFyeShkcGx5cikKICAgIGxpYnJhcnkoZ2dwbG90MikKICAgIGRhdGEoaGVpZ2h0cywgcGFja2FnZSA9ICJkc2xhYnMiKQogICAgdGhtIDwtIHRoZW1lX21pbmltYWwoKSArIHRoZW1lKHRleHQgPSBlbGVtZW50X3RleHQoc2l6ZSA9IDE2KSkKICAgIGZpbHRlcihoZWlnaHRzLCBzZXggPT0gIk1hbGUiKSB8PgogICAgICAgIGdncGxvdChhZXMoeCA9IGhlaWdodCkpICsKICAgICAgICBzdGF0X2VjZGYoKSArCiAgICAgICAgbGFicyh5ID0gImN1bXVsYXRpdmUgZnJlcXVlbmN5IiwKICAgICAgICAgICAgIHggPSAiaGVpZ2h0IChpbmNoZXMpIikgKwogICAgICAgIHRobQogICAgYGBgCgogICAgQmFzZWQgb24gdGhlIHBsb3QsIHdoYXQgcGVyY2VudGFnZSBvZiBtYWxlcyBhcmUgdGFsbGVyIHRoYW4gNzUgaW5jaGVzPwoKICAgIGEuIDEwMCUKICAgIGIuIDE1JQogICAgYy4gMjAlCiAgICBkLiAzJQoKCjIuIENvbnNpZGVyIHRoZSBmb2xsb3dpbmcgbm9ybWFsIFFRIHBsb3RzLgoKCiAgICBgYGB7ciwgZmlnLmhlaWdodCA9IDQsIGZpZy53aWR0aCA9IDgsIG1lc3NhZ2UgPSBGQUxTRX0KICAgIGxpYnJhcnkoZHBseXIpCiAgICBsaWJyYXJ5KGdncGxvdDIpCiAgICBsaWJyYXJ5KHBhdGNod29yaykKICAgIHRobSA8LSB0aGVtZV9taW5pbWFsKCkgKyB0aGVtZSh0ZXh0ID0gZWxlbWVudF90ZXh0KHNpemUgPSAxNikpCiAgICBkYXRhKGhlaWdodHMsIHBhY2thZ2UgPSAiZHNsYWJzIikKICAgIHNldC5zZWVkKDEyMzQ1KQogICAgcDEgPC0gZ2dwbG90KE5VTEwsIGFlcyhzYW1wbGUgPSBybm9ybSgyMDApKSkgKwogICAgICAgIGdlb21fcXEoKSArCiAgICAgICAgbGFicyh0aXRsZSA9ICJTYW1wbGUgMSIsCiAgICAgICAgICAgICB4ID0gInRoZW9yZXRpY2FsIHF1YW50aWxlIiwKICAgICAgICAgICAgIHkgPSAic2FtcGxlIHF1YW50aWxlIikgKwogICAgICAgIHRobQogICAgcDIgPC0gZ2dwbG90KGZhaXRoZnVsLCBhZXMoc2FtcGxlID0gZXJ1cHRpb25zKSkgKwogICAgICAgIGdlb21fcXEoKSArCiAgICAgICAgbGFicyh0aXRsZSA9ICJTYW1wbGUgMiIsCiAgICAgICAgICAgICB4ID0gInRoZW9yZXRpY2FsIHF1YW50aWxlIiwKICAgICAgICAgICAgIHkgPSAic2FtcGxlIHF1YW50aWxlIikgKwogICAgICAgIHRobQogICAgcDEgKyBwMgogICAgYGBgCgogICAgV291bGQgYSBub3JtYWwgZGlzdHJpYnV0aW9uIGJlIGEgcmVhc29uYWJsZSBtb2RlbCBmb3IgZWl0aGVyIG9mCiAgICB0aGVzZSBzYW1wbGVzPwoKICAgIGEuIE5vIGZvciBTYW1wbGUgMS4gWWVzIGZvciBTYW1wbGUgMi4KICAgIGIuIFllcyBmb3IgU2FtcGxlIDEuIE5vIGZvciBTYW1wbGUgMi4KICAgIGMuIFllcyBmb3IgYm90aC4KICAgIGQuIE5vIGZvciBib3RoLgo=