Dot Plots
Basics
One of the simplest visualizations of a single numerical variable with a modest number of observations and lables for the observations is a dot plot, or Cleveland dot plot:
library(ggplot2)
ggplot(Playfair) +
geom_point(aes(x = population, y = city))
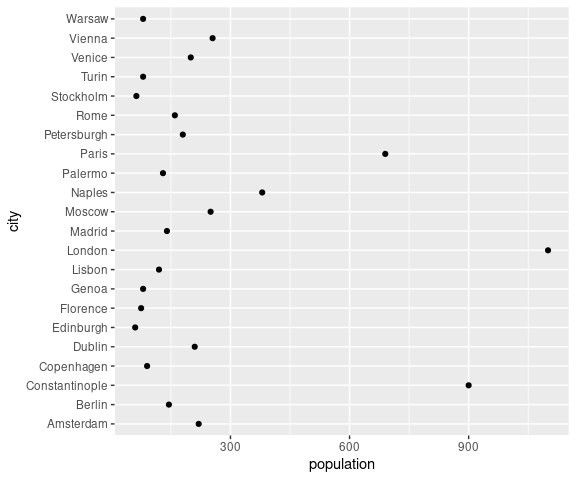
This visualization
- shows the overall distribution of the data, and
- makes it easy to locate the population of a particular city.
A useful variation is to order the vertical position by rank:
ggplot(Playfair) +
geom_point(aes(x = population, y = reorder(city, population)))
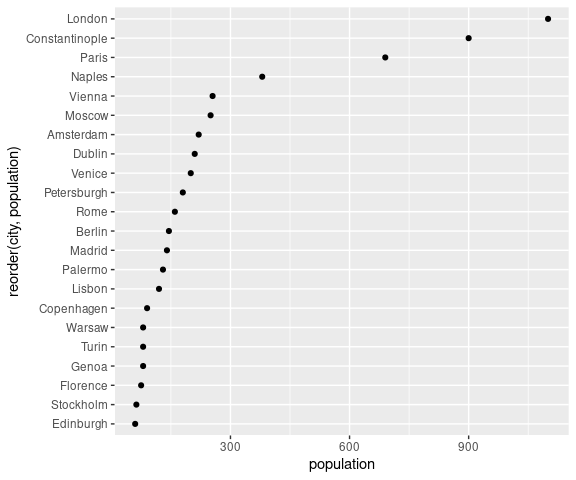
- locating a particular city is a little more difficult; but
- the shape of the distribution is more apparent
- approximate median and quartiles can be read off
This visualization is often very useful for group summaries.
Larger Data Sets
Using labels can become impractical for larger numbers of observations:
ggplot(citytemps) + geom_point(aes(x = temp, y = reorder(city, temp)))
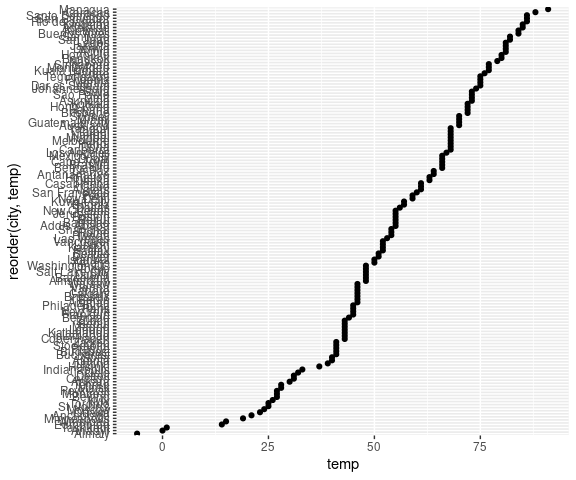
Instead we can use ranks:
ggplot(citytemps) + geom_point(aes(x = temp, y = rank(temp)))
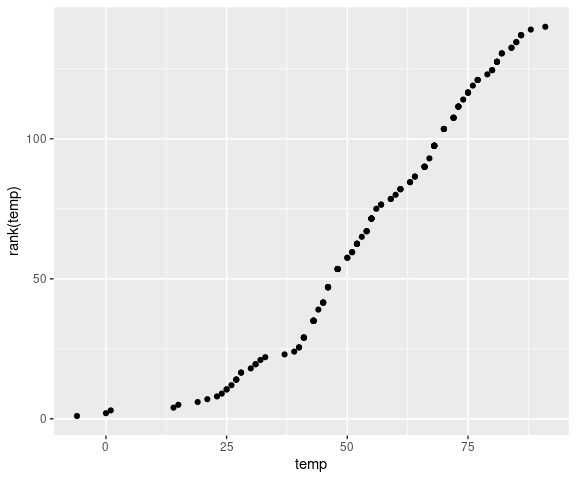
Using ranks or percentiles this visualization in principle scales to much larger data sets:
ggplot(diamonds) +
geom_point(aes(x = price, y = 100 * rank(price) / length(price)))
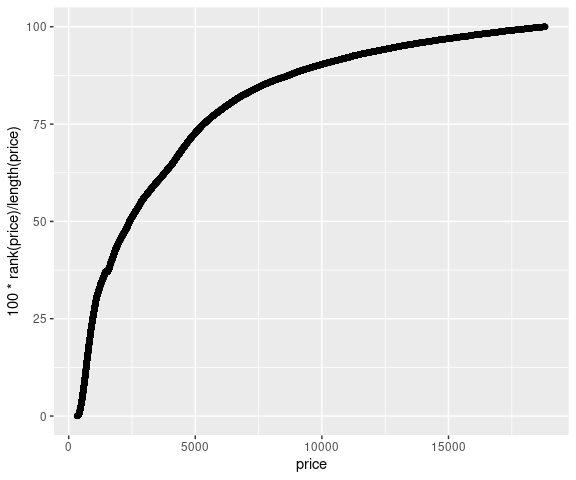
With a data set of this size there is little visual difference between a dot plot and a plot that interpolates the points:
ggplot(diamonds) +
geom_line(aes(x = price, y = 100 * rank(price) / length(price)))
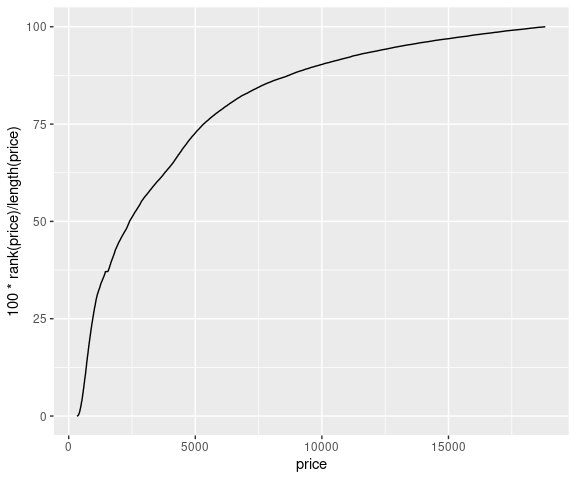
Both the dot plot and the interpolated verson use a lot of resources for computing and storing the plot with diminishing visual returns.
A more effective approach for larger data sets is to fix a set of percentages and plot against the corresponding percentiles:
p <- seq(0, 1, length.out = 100)
dm <- data.frame(pct = 100 * p, price = quantile(diamonds$price, p))
ggplot(dm) + geom_line(aes(x = price, y = pct))
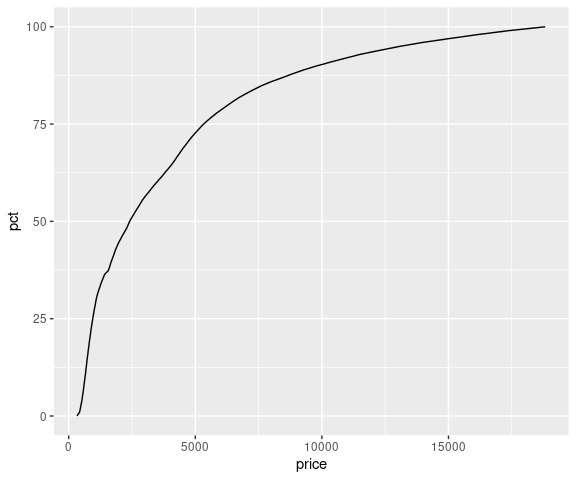
A similar result can be obtained with stat_ecdf.
Some Variations
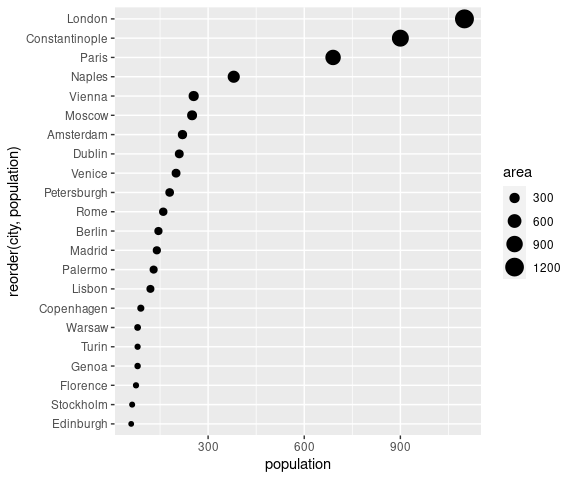
The size of the dots can be used to encode an additional numeric variable.
We can compute the approximate area for the cities in the Playfair data frame as pi * (diameter / 2) ^ 2:
library(dplyr)
PlayfairA <- mutate(Playfair, area = pi * (diameter / 2) ^ 2)
ggplot(PlayfairA) +
geom_point(aes(x = population, y = reorder(city, population),
size = area)) +
scale_size_area()
For the Barley data we have two measures per year. It can be useful to
- place both measures for a site/variety combination on one line, and
- identify the year using color:
barley <- mutate(barley, sitevar = paste(site, variety, sep = ", "))
ggplot(barley) +
geom_point(aes(x = yield, y = sitevar, color = year))
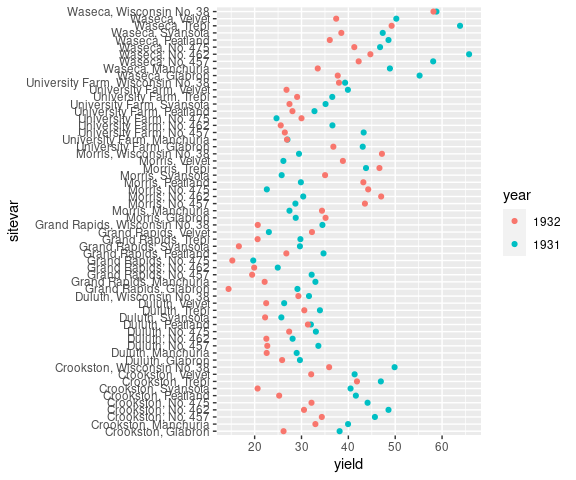
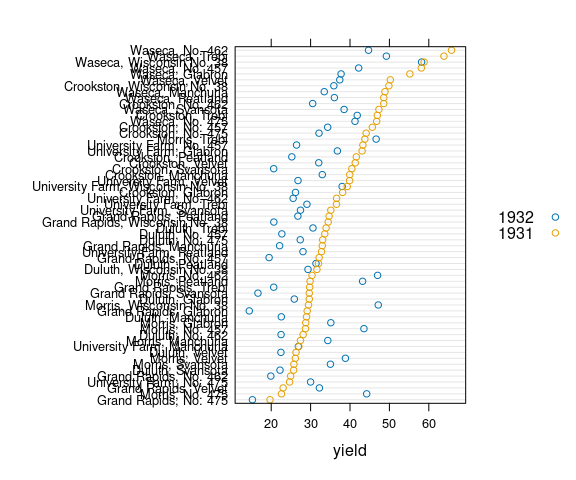
Reordering the lines based on the yield in 1931 may be useful.
First step: Isolate 1931 yields:
b31 <- filter(barley, year == 1931)
b31 <- select(b31, yield31 = yield, sitevar)
head(b31)
## yield31 sitevar
## 1 27.00000 University Farm, Manchuria
## 2 48.86667 Waseca, Manchuria
## 3 27.43334 Morris, Manchuria
## 4 39.93333 Crookston, Manchuria
## 5 32.96667 Grand Rapids, Manchuria
## 6 28.96667 Duluth, Manchuria
Second step: Use left_join to merge the 1931 yields with the barley data frame:
barley31 <- left_join(barley, b31)
head(barley31)
## yield variety year site sitevar yield31
## 1 27.00000 Manchuria 1931 University Farm University Farm, Manchuria 27.00000
## 2 48.86667 Manchuria 1931 Waseca Waseca, Manchuria 48.86667
## 3 27.43334 Manchuria 1931 Morris Morris, Manchuria 27.43334
## 4 39.93333 Manchuria 1931 Crookston Crookston, Manchuria 39.93333
## 5 32.96667 Manchuria 1931 Grand Rapids Grand Rapids, Manchuria 32.96667
## 6 28.96667 Manchuria 1931 Duluth Duluth, Manchuria 28.96667
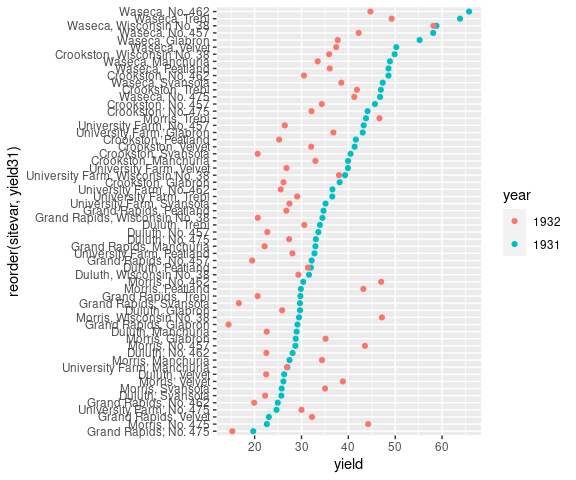
Now plot the data:
ggplot(barley31) +
geom_point(aes(x = yield, y = reorder(sitevar, yield31), color = year))
Base and Lattice Graphics
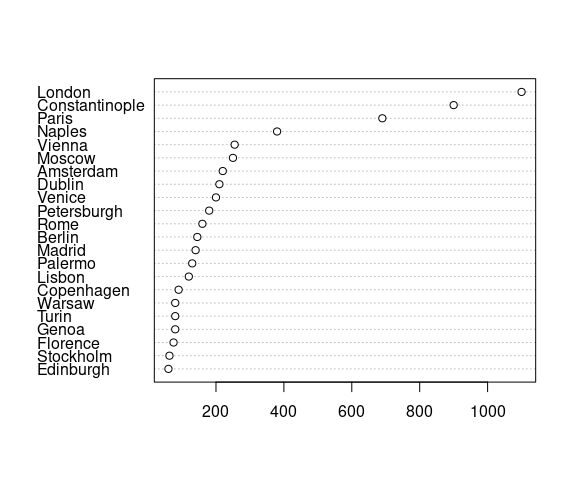
Base graphics provides the dotchart function:
dotchart(Playfair$population, labels = Playfair$city)
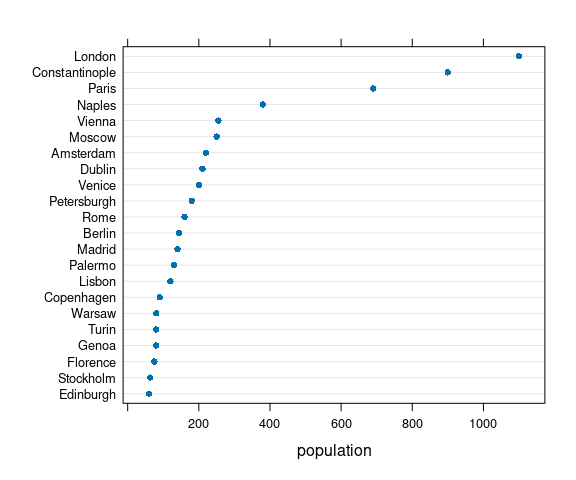
The lattice package provides dotplot:
library(lattice)
dotplot(reorder(city, population) ~ population, data = Playfair)
Most lattice plots support a group argument that is usually mapped to color:
dotplot(reorder(sitevar, yield31) ~ yield,
group = year, data = barley31, auto.key = TRUE)
Bar Charts
Basics
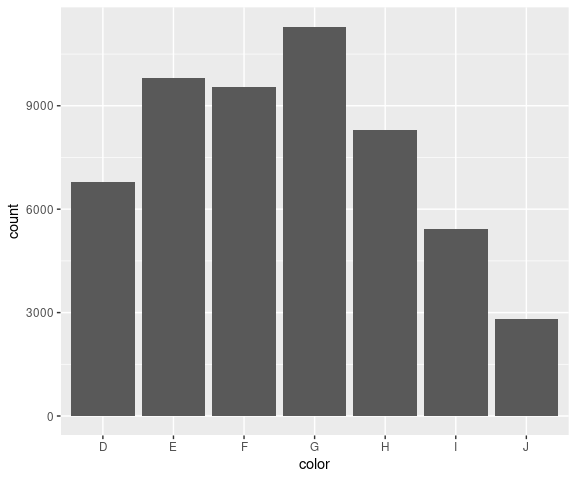
Bar charts are most commonly used to show frequencies for categorical data. They are also usually drawn verically:
ggplot(diamonds) + geom_bar(aes(x = color))
It is possible to persuade geom_bar to encode the value of a numeric variable as bar height by
- assigning the variable to the
y aesthetic, and
- specifying
stat = "identity".
The default stat is to bin the data, as for a histogram, and to use the bin counts as the y aesthetic.
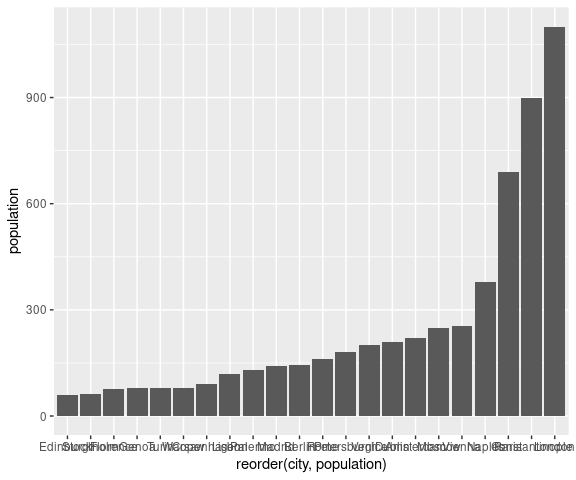
ggplot(Playfair) +
geom_bar(aes(y = population, x = reorder(city, population)),
stat = "identity")
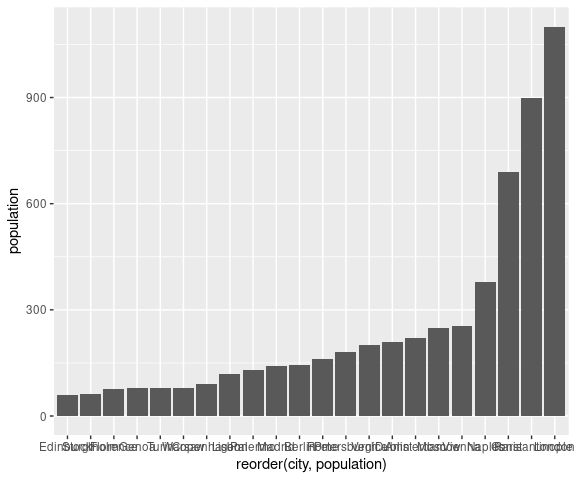
Slightly simpler is to use geom_col:
ggplot(Playfair) +
geom_col(aes(y = population, x = reorder(city, population)))
To make labels readable we can flip the plot:
ggplot(Playfair) +
geom_col(aes(y = population, x = reorder(city, population))) +
coord_flip()
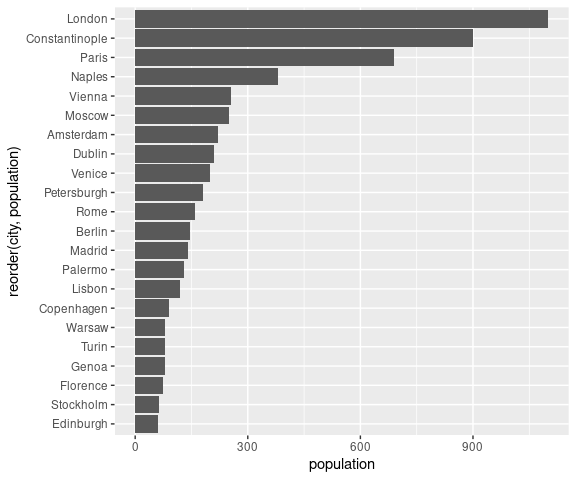
[ Switching x and y doesn’t do what you want.]
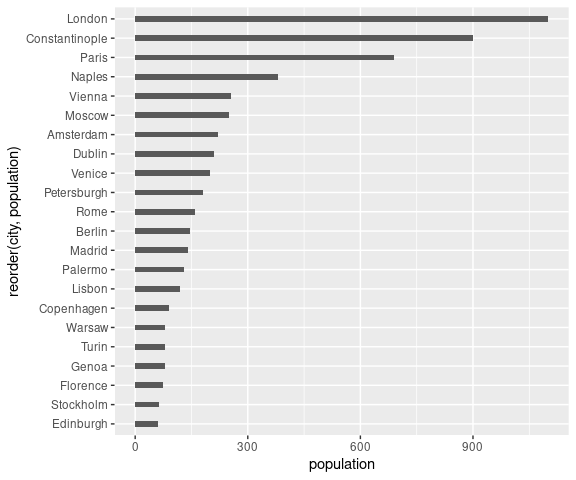
Reducing the bar width may be helpful:
ggplot(Playfair) +
geom_col(aes(y = population, x = reorder(city, population)),
width = 0.3) +
coord_flip()
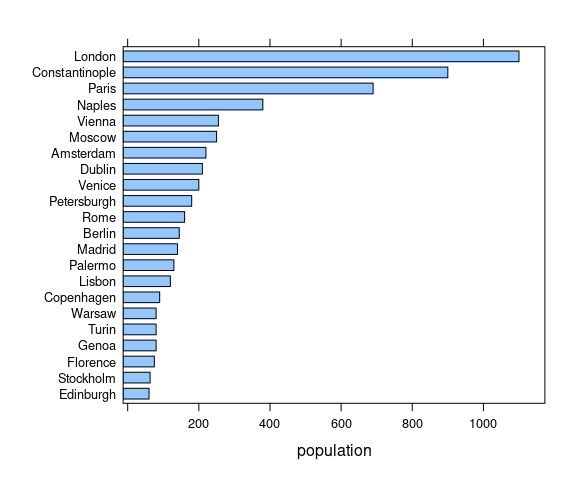
Creating this basic bar chart in lattice is easier:
barchart(reorder(city, population) ~ population, data = Playfair)
Base graphics also provide a bar chart with the barplot function.
opar <- par(mar = c(5, 5, 4, 2) + 0.1)
with(Playfair,
barplot(population, horiz = TRUE, names.arg = city,
las = 1, cex.names = 0.7, cex.axis = 0.7))
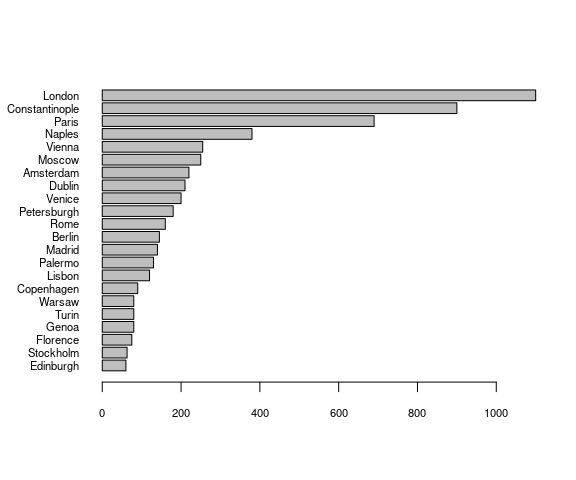
par(opar)
Comparisons and the Zero Baseline Issue
Bar charts seem to be used much more than dot plots in the popular media.
But they are less widely applicable, and have one dangerous feature, sometimes called the zero baseline issue.
Because of the way our perception works, when we look at a bar chart we focus on the length of the bar, the distance from the base line, even when the baseline is not meaningful.
Look at these views of tempreatures in the subset of cities where temperatures are between 60 and 70 degrees.
library(gridExtra)
c6070 <- filter(citytemps, temp >= 60 & temp <= 70)
p1 <- barchart(city ~ temp, c6070)
p2 <- dotplot(city ~ temp, c6070)
grid.arrange(p1, p2, nrow = 1)
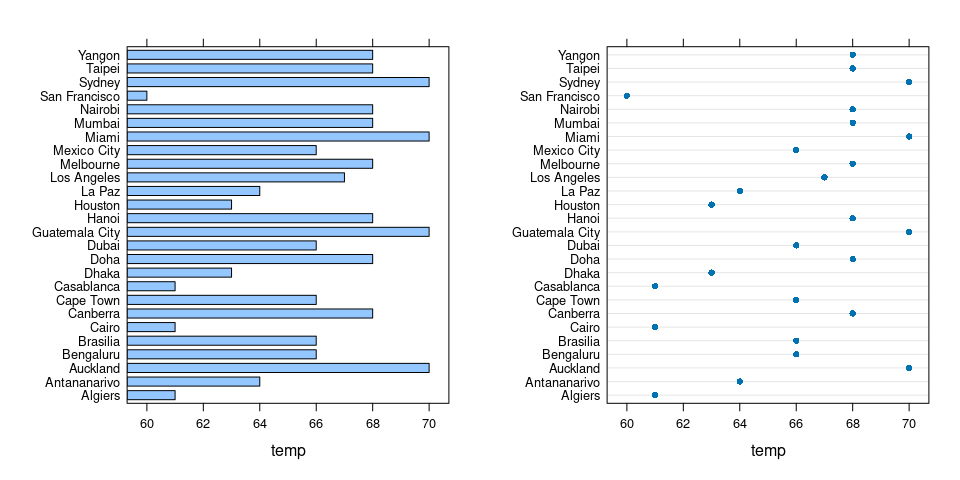
Take the Dhaka-Casablanca pair and the Dubai-Guatemala City pair.
With a subset like this the focus is on the difference, not the ratio: in this context these temperatures are interval data.
As another example, take the cities in the Playfair data with population between 100 and 500 thousand:
P15 <- filter(Playfair, population >= 100 & population <= 500)
p1 <- dotplot(city ~ population, data = P15)
p2 <- barchart(city ~ population, data = P15)
grid.arrange(p1, p2, nrow = 1)
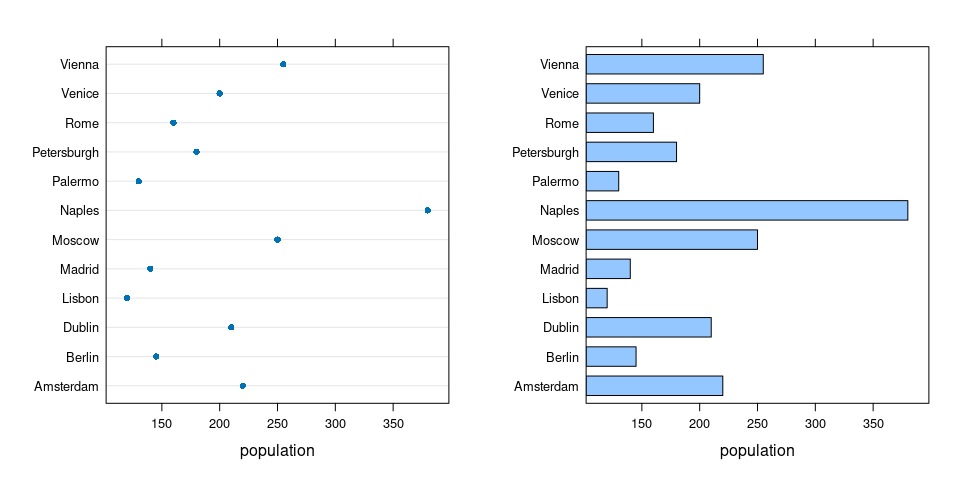
Someone choosing to look at a restricted range like this is most likely focusing on the differences in population, not the ratio.
The ratio comparisons emphasized by the bar chart are not meaningful.
Setting the origin to zero rescues the bar chart:
P15 <- filter(Playfair, population >= 100 & population <= 500)
p1 <- dotplot(city ~ population, data = P15, origin = 0)
p2 <- barchart(city ~ population, data = P15, origin = 0)
grid.arrange(p1, p2, nrow = 1)
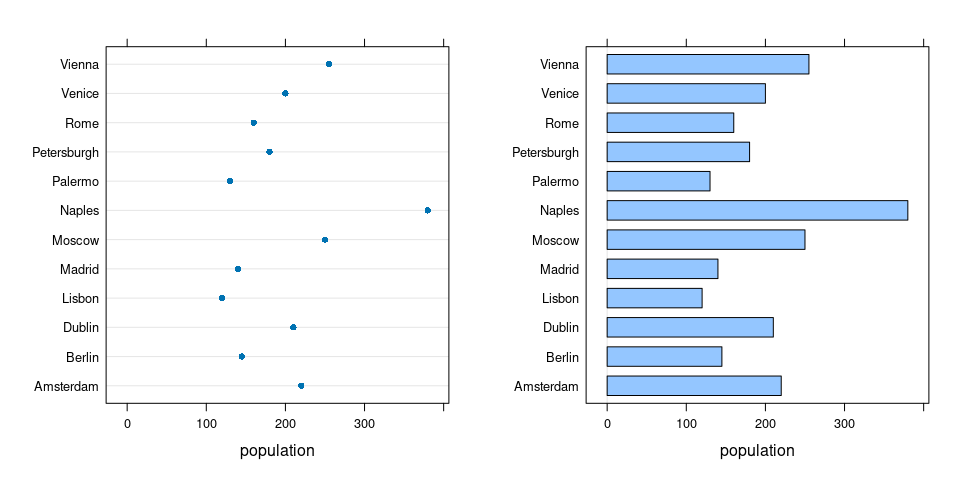
Either chart allows a ratio comparison or a difference comparison.
- The ratio comparison is a little easier with a bar chart.
- The difference comparison is harder because of the distraction created by the bars.
- For quantity measurements ratios are usually at least meaningful even if they might not be the primary focus
Some notes:
- When using bar charts for positive numbers where ratios are meaningful the baseline should always be zero.
- The only exception is when there is a natural non-zero baseline value, such as 32 degrees Fahrenheit (i.e. 0 degrees Celcius) for temperatures.
- You may need to intervene with your software’s defaults to make this happen.
- Bar charts always push the viewer to ratio comparisons, whether they are meaningful or not.
- Using a non-zero baseline can therefore mislead the viewer.
- Some news organizations seem particularly prone to taking advantage of/falling prey to this issue.
- I used
lattice in these examples because it is hard to get geom_bar or `geom_col~ to use a non-zero base line (which is a good thing!).
- You can create a bar chart with a non-zero baseline using
geom_segment.
Data With Both Positive and Negative Values
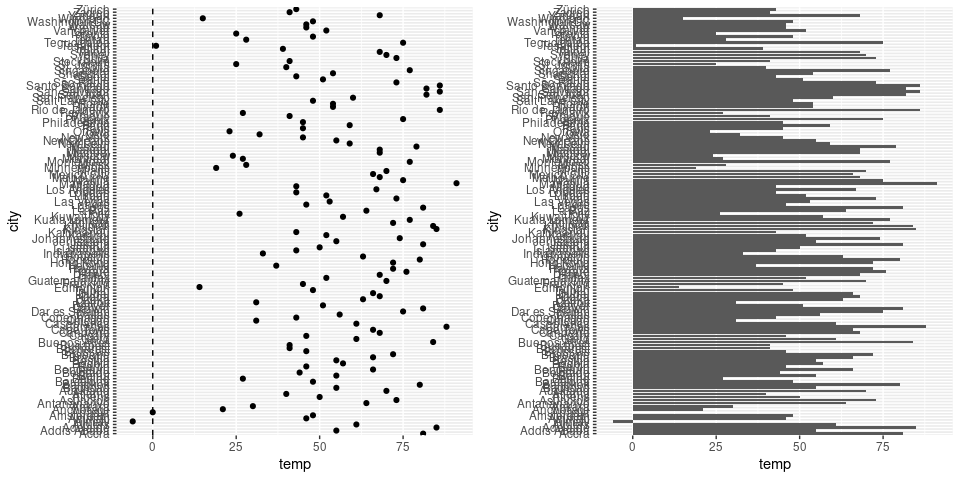
Bar charts can be used for data containing both positive and negative values:
p1 <- ggplot(citytemps) +
geom_point(aes(y = city, x = temp - 32)) +
geom_vline(xintercept = 0, lty = 2)
p2 <- ggplot(citytemps) +
geom_col(aes(x = city, y = temp - 32)) +
coord_flip()
grid.arrange(p1, p2, nrow = 1)
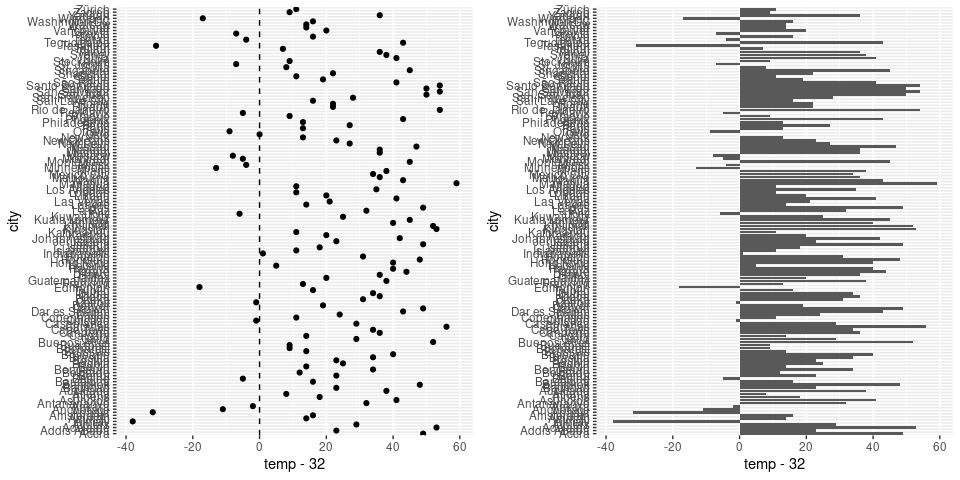
- This puts a strong emphasis on the base line
- This can be useful if the baseline is meaningful, such as
- Zero degrees Fahrenheit is not meaningful:
p1 <- ggplot(citytemps) +
geom_point(aes(y = city, x = temp)) +
geom_vline(xintercept = 0, lty = 2)
p2 <- ggplot(citytemps) +
geom_col(aes(x = city, y = temp)) +
coord_flip()
grid.arrange(p1, p2, nrow = 1)
Group Summaries
Dot plots, and sometimes bar charts, can be very useful for showing group summaries. Two approaches for computing summaries:
Use the tapply, by, and aggregate functions from base R.
Use tools in the tidyverse, in particular from the dplyr package.
I will use the dplyr approach. This uses group_by to create a grouped table, followed by summarize.
Here is how to compute the agerage yield values for each variety in the barley data:
barley_by_variety <- group_by(barley, variety)
barley_variety_means <- summarize(barley_by_variety, avg_yield = mean(yield))
head(barley_variety_means)
## # A tibble: 6 × 2
## variety avg_yield
## <fct> <dbl>
## 1 Svansota 30.4
## 2 No. 462 35.4
## 3 Manchuria 31.5
## 4 No. 475 31.8
## 5 Velvet 33.1
## 6 Peatland 34.2
ggplot(barley_variety_means) +
geom_point(aes(x = avg_yield, y = as.character(variety)))
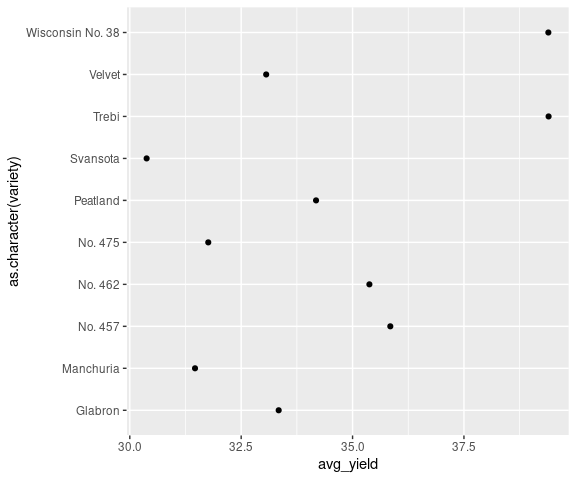
The ordering of the variety factor created by the two approaches is a little different.
An alternate way of specifying the dplyr computation uses the pipe operator |>:
barley |>
group_by(variety) |>
summarize(avg_yield = mean(yield))
In this approach the result on the left of |> is passed implicitly as the first argument to the function called on the right.
Some like this approach a lot; others do not. I do not care for it.
Variations in Appearence
Base and lattice dot plots use only hirizontal grid lines. This corresponds to the version introduced by W. S. Cleveland.
Lattice and ggplot allow features such as this to be customized using themes.
ggplot2 provides a number of alternate themses; the ggthemes package provides more.
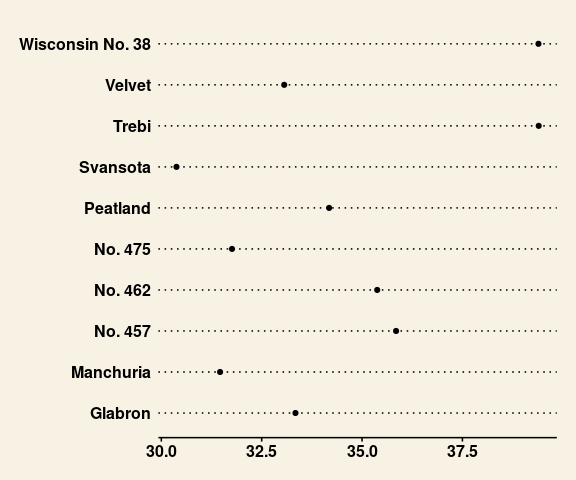
The Wall Street Journal theme ggthmes::theme_wsj produces
ggplot(barley_variety_means) +
geom_point(aes(x = avg_yield, y = as.character(variety))) +
ggthemes::theme_wsj()
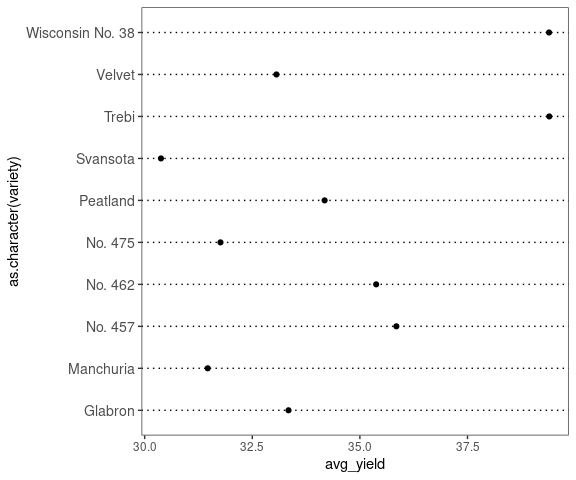
A theme to closely match the style used in Cleveland’s 1993 book Visualizing Data and used by the base and lattice functions can be defined as
theme_dotplotx <- function() {
theme( ## remove the vertical grid lines
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
## explicitly set the horizontal lines (or they will disappear too)
panel.grid.major.y = element_line(color = "black", linetype = 3),
axis.text.y = element_text(size = rel(1.2)),
## use a white backgrounsd
panel.background = element_rect(fill = "white", colour = NA),
panel.border = element_rect(fill = NA, colour = "grey20"))
}
This produces
ggplot(barley_variety_means) +
geom_point(aes(x = avg_yield, y = as.character(variety))) +
theme_dotplotx()
LS0tCnRpdGxlOiAiRG90IFBsb3RzIGFuZCBCYXIgQ2hhcnRzIgpvdXRwdXQ6CiAgaHRtbF9kb2N1bWVudDoKICAgIHRvYzogeWVzCiAgICBjb2RlX2Rvd25sb2FkOiB0cnVlCi0tLQoKYGBge3IgZ2xvYmFsX29wdGlvbnMsIGluY2x1ZGUgPSBGQUxTRX0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGNvbGxhcHNlID0gVFJVRSkKYGBgCgpgYGB7ciwgaW5jbHVkZSA9IEZBTFNFfQpzb3VyY2UoImRhdGFzZXRzLlIiKQpgYGAKCiMjIENvbnNpZGVyYXRpb25zIHRvIEtlZXAgaW4gTWluZAoKQXMgd2UgbG9vayBhdCB2aXN1YWxpemF0aW9ucywgYSByZW1pbmRlciBvZiBzb21lIGNvbnNpZGVyYXRpb25zOgoKICAqIFRhc2sgbGV2ZWxzIGZvciB2aXN1YWxpemF0aW9uLCBmcm9tIGhpZ2hlc3QgdG8gbG93ZXN0IGxldmVsOgoKICAgICAgKiAqKkFuYWx5emUqKjogSWRlbnRpZnkgcGF0dGVybnMsIGRpc3RyaWJ1dGlvbnMsIHByZXNlbmNlIG9mIG91dGxpZXJzCiAgICAgICAgb3IgY2x1c3RlcnMsIG90aGVyIGludGVyZXN0aW5nIGZlYXR1cmVzLgoKICAgICAgKiAqKlNlYXJjaCoqOiBMb29rIHVwIGFzcGVjdHMgb2YgYSBmZWF0dXJlIGtub3duIGluIGFkdmFuY2Ugb3IKICAgICAgICByZXZlYWxlZCBieSB0aGUgdmlzdWFsaWF0aW9uLgoKICAgICAgKiAqKlF1ZXJ5Kio6IElkZW50aWZ5LCBjb21wYXJlIGZlYXR1cmVzIG9mIGluZGl2aWR1YWwgaXRlbXMuCgogICAgRWFjaCBoaWdoZXIgbGV2ZWwgYnVpbGRzIG9uIHRoZSBsZXZlbHMgYmVsb3cuCgoqIFNjYWxhYmlsaXR5OgoKICAgICogSG93IHdlbGwgZG8gdGhlc2UgdmlzdWFsaXphdGlvbnMgd29yayBmb3IgbGFyZ2VyIGRhdGEgc2V0cz8KCiAgICAqIEFyZSB0aGVyZSB2YXJpYXRpb25zIHRoYXQgY2FuIGhlbHAgZm9yIGxhcmdlciBkYXRhIHNldHM/CgoKIyMgRG90IFBsb3RzCgojIyMgQmFzaWNzCgpPbmUgb2YgdGhlIHNpbXBsZXN0IHZpc3VhbGl6YXRpb25zIG9mIGEgc2luZ2xlIG51bWVyaWNhbCB2YXJpYWJsZSB3aXRoCmEgbW9kZXN0IG51bWJlciBvZiBvYnNlcnZhdGlvbnMgYW5kIGxhYmxlcyBmb3IgdGhlIG9ic2VydmF0aW9ucyBpcyBhCl9kb3QgcGxvdF8sIG9yIF9DbGV2ZWxhbmQgZG90IHBsb3RfOgoKCmBgYHtyfQpsaWJyYXJ5KGdncGxvdDIpCmdncGxvdChQbGF5ZmFpcikgKwogICAgZ2VvbV9wb2ludChhZXMoeCA9IHBvcHVsYXRpb24sIHkgPSBjaXR5KSkKYGBgCgpUaGlzIHZpc3VhbGl6YXRpb24KCiogc2hvd3MgdGhlIG92ZXJhbGwgZGlzdHJpYnV0aW9uIG9mIHRoZSBkYXRhLCBhbmQKKiBtYWtlcyBpdCBlYXN5IHRvIGxvY2F0ZSB0aGUgcG9wdWxhdGlvbiBvZiBhIHBhcnRpY3VsYXIgY2l0eS4KCkEgdXNlZnVsIHZhcmlhdGlvbiBpcyB0byBvcmRlciB0aGUgdmVydGljYWwgcG9zaXRpb24gYnkgcmFuazoKYGBge3J9CmdncGxvdChQbGF5ZmFpcikgKwogICAgZ2VvbV9wb2ludChhZXMoeCA9IHBvcHVsYXRpb24sIHkgPSByZW9yZGVyKGNpdHksIHBvcHVsYXRpb24pKSkKYGBgCgoqICBsb2NhdGluZyBhIHBhcnRpY3VsYXIgY2l0eSBpcyBhIGxpdHRsZSBtb3JlIGRpZmZpY3VsdDsgYnV0CiogIHRoZSBzaGFwZSBvZiB0aGUgZGlzdHJpYnV0aW9uIGlzIG1vcmUgYXBwYXJlbnQKKiAgYXBwcm94aW1hdGUgbWVkaWFuIGFuZCBxdWFydGlsZXMgY2FuIGJlIHJlYWQgb2ZmCgpUaGlzIHZpc3VhbGl6YXRpb24gaXMgb2Z0ZW4gdmVyeSB1c2VmdWwgZm9yIGdyb3VwIHN1bW1hcmllcy4KCgojIyMgTGFyZ2VyIERhdGEgU2V0cwoKVXNpbmcgbGFiZWxzIGNhbiBiZWNvbWUgaW1wcmFjdGljYWwgZm9yIGxhcmdlciBudW1iZXJzIG9mIG9ic2VydmF0aW9uczoKCmBgYHtyfQpnZ3Bsb3QoY2l0eXRlbXBzKSArIGdlb21fcG9pbnQoYWVzKHggPSB0ZW1wLCB5ID0gcmVvcmRlcihjaXR5LCB0ZW1wKSkpCmBgYAoKSW5zdGVhZCB3ZSBjYW4gdXNlIHJhbmtzOgoKYGBge3J9CmdncGxvdChjaXR5dGVtcHMpICsgZ2VvbV9wb2ludChhZXMoeCA9IHRlbXAsIHkgPSByYW5rKHRlbXApKSkKYGBgCgpVc2luZyByYW5rcyBvciBwZXJjZW50aWxlcyB0aGlzIHZpc3VhbGl6YXRpb24gaW4gcHJpbmNpcGxlIHNjYWxlcyB0bwptdWNoIGxhcmdlciBkYXRhIHNldHM6CgpgYGB7cn0KZ2dwbG90KGRpYW1vbmRzKSArCiAgICBnZW9tX3BvaW50KGFlcyh4ID0gcHJpY2UsIHkgPSAxMDAgKiByYW5rKHByaWNlKSAvIGxlbmd0aChwcmljZSkpKQpgYGAKCldpdGggYSBkYXRhIHNldCBvZiB0aGlzIHNpemUgdGhlcmUgaXMgbGl0dGxlIHZpc3VhbCBkaWZmZXJlbmNlIGJldHdlZW4KYSBkb3QgcGxvdCBhbmQgYSBwbG90IHRoYXQgaW50ZXJwb2xhdGVzIHRoZSBwb2ludHM6CgpgYGB7cn0KZ2dwbG90KGRpYW1vbmRzKSArCiAgICBnZW9tX2xpbmUoYWVzKHggPSBwcmljZSwgeSA9IDEwMCAqIHJhbmsocHJpY2UpIC8gbGVuZ3RoKHByaWNlKSkpCmBgYAoKQm90aCB0aGUgZG90IHBsb3QgYW5kIHRoZSBpbnRlcnBvbGF0ZWQgdmVyc29uIHVzZSBhIGxvdCBvZiByZXNvdXJjZXMKZm9yIGNvbXB1dGluZyBhbmQgc3RvcmluZyB0aGUgcGxvdCB3aXRoIGRpbWluaXNoaW5nIHZpc3VhbCByZXR1cm5zLgoKQSBtb3JlIGVmZmVjdGl2ZSBhcHByb2FjaCBmb3IgbGFyZ2VyIGRhdGEgc2V0cyBpcyB0byBmaXggYSBzZXQgb2YKcGVyY2VudGFnZXMgYW5kIHBsb3QgYWdhaW5zdCB0aGUgY29ycmVzcG9uZGluZyBwZXJjZW50aWxlczoKCmBgYHtyfQpwIDwtIHNlcSgwLCAxLCBsZW5ndGgub3V0ID0gMTAwKQpkbSA8LSBkYXRhLmZyYW1lKHBjdCA9IDEwMCAqIHAsIHByaWNlID0gcXVhbnRpbGUoZGlhbW9uZHMkcHJpY2UsIHApKQpnZ3Bsb3QoZG0pICsgZ2VvbV9saW5lKGFlcyh4ID0gcHJpY2UsIHkgPSBwY3QpKQpgYGAKCkEgc2ltaWxhciByZXN1bHQgY2FuIGJlIG9idGFpbmVkIHdpdGggYHN0YXRfZWNkZmAuCgoKIyMjIFNvbWUgVmFyaWF0aW9ucwoKVGhlIHNpemUgb2YgdGhlIGRvdHMgY2FuIGJlIHVzZWQgdG8gZW5jb2RlIGFuIGFkZGl0aW9uYWwgbnVtZXJpYwp2YXJpYWJsZS4KCldlIGNhbiBjb21wdXRlIHRoZSBhcHByb3hpbWF0ZSBhcmVhIGZvciB0aGUgY2l0aWVzIGluIHRoZSBgUGxheWZhaXJgCmRhdGEgZnJhbWUgYXMgYHBpICogKGRpYW1ldGVyIC8gMikgXiAyYDoKCmBgYHtyLCBtZXNzYWdlID0gRkFMU0V9CmxpYnJhcnkoZHBseXIpClBsYXlmYWlyQSA8LSBtdXRhdGUoUGxheWZhaXIsIGFyZWEgPSBwaSAqIChkaWFtZXRlciAvIDIpIF4gMikKZ2dwbG90KFBsYXlmYWlyQSkgKwogICAgZ2VvbV9wb2ludChhZXMoeCA9IHBvcHVsYXRpb24sIHkgPSByZW9yZGVyKGNpdHksIHBvcHVsYXRpb24pLAogICAgICAgICAgICAgICAgICAgc2l6ZSA9IGFyZWEpKSArCiAgICBzY2FsZV9zaXplX2FyZWEoKQpgYGAKCkZvciB0aGUgQmFybGV5IGRhdGEgd2UgaGF2ZSB0d28gbWVhc3VyZXMgcGVyIHllYXIuIEl0IGNhbiBiZSB1c2VmdWwgdG8KCiogcGxhY2UgYm90aCBtZWFzdXJlcyBmb3IgYSBzaXRlL3ZhcmlldHkgY29tYmluYXRpb24gb24gb25lIGxpbmUsIGFuZAoqIGlkZW50aWZ5IHRoZSB5ZWFyIHVzaW5nIGNvbG9yOgoKYGBge3IsIG1lc3NhZ2UgPSBGQUxTRX0KYmFybGV5IDwtIG11dGF0ZShiYXJsZXksIHNpdGV2YXIgPSBwYXN0ZShzaXRlLCB2YXJpZXR5LCBzZXAgPSAiLCAiKSkKZ2dwbG90KGJhcmxleSkgKwogICAgZ2VvbV9wb2ludChhZXMoeCA9IHlpZWxkLCB5ID0gc2l0ZXZhciwgY29sb3IgPSB5ZWFyKSkKYGBgCgpSZW9yZGVyaW5nIHRoZSBsaW5lcyBiYXNlZCBvbiB0aGUgeWllbGQgaW4gMTkzMSBtYXkgYmUgdXNlZnVsLgoKRmlyc3Qgc3RlcDogSXNvbGF0ZSAxOTMxIHlpZWxkczoKYGBge3J9CmIzMSA8LSBmaWx0ZXIoYmFybGV5LCB5ZWFyID09IDE5MzEpCmIzMSA8LSBzZWxlY3QoYjMxLCB5aWVsZDMxID0geWllbGQsIHNpdGV2YXIpCmhlYWQoYjMxKQpgYGAKClNlY29uZCBzdGVwOiBVc2UgYGxlZnRfam9pbmAgdG8gbWVyZ2UgdGhlIDE5MzEgeWllbGRzIHdpdGggdGhlIGJhcmxleQpkYXRhIGZyYW1lOgpgYGB7cn0KYmFybGV5MzEgPC0gbGVmdF9qb2luKGJhcmxleSwgYjMxKQpoZWFkKGJhcmxleTMxKQpgYGAKCk5vdyBwbG90IHRoZSBkYXRhOgpgYGB7cn0KZ2dwbG90KGJhcmxleTMxKSArCiAgICBnZW9tX3BvaW50KGFlcyh4ID0geWllbGQsIHkgPSByZW9yZGVyKHNpdGV2YXIsIHlpZWxkMzEpLCBjb2xvciA9IHllYXIpKQpgYGAKCiMjIyBCYXNlIGFuZCBMYXR0aWNlIEdyYXBoaWNzCkJhc2UgZ3JhcGhpY3MgcHJvdmlkZXMgdGhlIGBkb3RjaGFydGAgZnVuY3Rpb246CmBgYHtyfQpkb3RjaGFydChQbGF5ZmFpciRwb3B1bGF0aW9uLCBsYWJlbHMgPSBQbGF5ZmFpciRjaXR5KQpgYGAKClRoZSBgbGF0dGljZWAgcGFja2FnZSBwcm92aWRlcyBgZG90cGxvdGA6CmBgYHtyfQpsaWJyYXJ5KGxhdHRpY2UpCmRvdHBsb3QocmVvcmRlcihjaXR5LCBwb3B1bGF0aW9uKSB+IHBvcHVsYXRpb24sIGRhdGEgPSBQbGF5ZmFpcikKYGBgCgpNb3N0IGxhdHRpY2UgcGxvdHMgc3VwcG9ydCBhIGBncm91cGAgYXJndW1lbnQgdGhhdCBpcyB1c3VhbGx5IG1hcHBlZAp0byBjb2xvcjoKCmBgYHtyfQpkb3RwbG90KHJlb3JkZXIoc2l0ZXZhciwgeWllbGQzMSkgfiB5aWVsZCwKICAgICAgICBncm91cCA9IHllYXIsIGRhdGEgPSBiYXJsZXkzMSwgYXV0by5rZXkgPSBUUlVFKQpgYGAKCgojIyBCYXIgQ2hhcnRzCgojIyMgQmFzaWNzCgpCYXIgY2hhcnRzIGFyZSBtb3N0IGNvbW1vbmx5IHVzZWQgdG8gc2hvdyBmcmVxdWVuY2llcyBmb3IgY2F0ZWdvcmljYWwKZGF0YS4gVGhleSBhcmUgYWxzbyB1c3VhbGx5IGRyYXduIHZlcmljYWxseToKCmBgYHtyfQpnZ3Bsb3QoZGlhbW9uZHMpICsgZ2VvbV9iYXIoYWVzKHggPSBjb2xvcikpCmBgYAoKSXQgaXMgcG9zc2libGUgdG8gcGVyc3VhZGUgYGdlb21fYmFyYCB0byBlbmNvZGUgdGhlIHZhbHVlIG9mIGEgbnVtZXJpYwp2YXJpYWJsZSBhcyBiYXIgaGVpZ2h0IGJ5CgoqIGFzc2lnbmluZyB0aGUgdmFyaWFibGUgdG8gdGhlIGB5YCBhZXN0aGV0aWMsIGFuZAoqIHNwZWNpZnlpbmcgYHN0YXQgPSAiaWRlbnRpdHkiYC4KClRoZSBkZWZhdWx0IGBzdGF0YCBpcyB0byBiaW4gdGhlIGRhdGEsIGFzIGZvciBhIGhpc3RvZ3JhbSwgYW5kIHRvIHVzZQp0aGUgYmluIGNvdW50cyBhcyB0aGUgYHlgIGFlc3RoZXRpYy4KCmBgYHtyfQpnZ3Bsb3QoUGxheWZhaXIpICsKICAgIGdlb21fYmFyKGFlcyh5ID0gcG9wdWxhdGlvbiwgeCA9IHJlb3JkZXIoY2l0eSwgcG9wdWxhdGlvbikpLAogICAgICAgICAgICAgc3RhdCA9ICJpZGVudGl0eSIpCmBgYAoKU2xpZ2h0bHkgc2ltcGxlciBpcyB0byB1c2UgYGdlb21fY29sYDoKCmBgYHtyfQpnZ3Bsb3QoUGxheWZhaXIpICsKICAgIGdlb21fY29sKGFlcyh5ID0gcG9wdWxhdGlvbiwgeCA9IHJlb3JkZXIoY2l0eSwgcG9wdWxhdGlvbikpKQpgYGAKClRvIG1ha2UgbGFiZWxzIHJlYWRhYmxlIHdlIGNhbiBmbGlwIHRoZSBwbG90OgpgYGB7cn0KZ2dwbG90KFBsYXlmYWlyKSArCiAgICBnZW9tX2NvbChhZXMoeSA9IHBvcHVsYXRpb24sIHggPSByZW9yZGVyKGNpdHksIHBvcHVsYXRpb24pKSkgKwogICAgY29vcmRfZmxpcCgpCmBgYAoKWyBTd2l0Y2hpbmcgYHhgIGFuZCBgeWAgZG9lc24ndCBkbyB3aGF0IHlvdSB3YW50Ll0KCgpSZWR1Y2luZyB0aGUgYmFyIHdpZHRoIG1heSBiZSBoZWxwZnVsOgpgYGB7cn0KZ2dwbG90KFBsYXlmYWlyKSArCiAgICBnZW9tX2NvbChhZXMoeSA9IHBvcHVsYXRpb24sIHggPSByZW9yZGVyKGNpdHksIHBvcHVsYXRpb24pKSwKICAgICAgICAgICAgIHdpZHRoID0gMC4zKSArCiAgICBjb29yZF9mbGlwKCkKYGBgCgpDcmVhdGluZyB0aGlzIGJhc2ljIGJhciBjaGFydCBpbiBgbGF0dGljZWAgaXMgZWFzaWVyOgpgYGB7cn0KYmFyY2hhcnQocmVvcmRlcihjaXR5LCBwb3B1bGF0aW9uKSB+IHBvcHVsYXRpb24sIGRhdGEgPSBQbGF5ZmFpcikKYGBgCgpCYXNlIGdyYXBoaWNzIGFsc28gcHJvdmlkZSBhIGJhciBjaGFydCB3aXRoIHRoZSBgYmFycGxvdGAgZnVuY3Rpb24uCmBgYHtyfQpvcGFyIDwtIHBhcihtYXIgPSBjKDUsIDUsIDQsIDIpICsgMC4xKQp3aXRoKFBsYXlmYWlyLAogICAgIGJhcnBsb3QocG9wdWxhdGlvbiwgaG9yaXogPSBUUlVFLCBuYW1lcy5hcmcgPSBjaXR5LAogICAgICAgICAgICAgbGFzID0gMSwgY2V4Lm5hbWVzID0gMC43LCBjZXguYXhpcyA9IDAuNykpCnBhcihvcGFyKQpgYGAKCgojIyMgQ29tcGFyaXNvbnMgYW5kIHRoZSBaZXJvIEJhc2VsaW5lIElzc3VlCgpCYXIgY2hhcnRzIHNlZW0gdG8gYmUgdXNlZCBtdWNoIG1vcmUgdGhhbiBkb3QgcGxvdHMgaW4gdGhlIHBvcHVsYXIKbWVkaWEuCgpCdXQgdGhleSBhcmUgbGVzcyB3aWRlbHkgYXBwbGljYWJsZSwgYW5kIGhhdmUgb25lIGRhbmdlcm91cwpmZWF0dXJlLCBzb21ldGltZXMgY2FsbGVkIHRoZSBfemVybyBiYXNlbGluZSBpc3N1ZV8uCgpCZWNhdXNlIG9mIHRoZSB3YXkgb3VyIHBlcmNlcHRpb24gd29ya3MsIHdoZW4gd2UgbG9vayBhdCBhIGJhciBjaGFydAp3ZSBmb2N1cyBvbiB0aGUgbGVuZ3RoIG9mIHRoZSBiYXIsIHRoZSBkaXN0YW5jZSBmcm9tIHRoZSBiYXNlIGxpbmUsCmV2ZW4gd2hlbiB0aGUgYmFzZWxpbmUgaXMgbm90IG1lYW5pbmdmdWwuCgpMb29rIGF0IHRoZXNlIHZpZXdzIG9mIHRlbXByZWF0dXJlcyBpbiB0aGUgc3Vic2V0IG9mIGNpdGllcyB3aGVyZQp0ZW1wZXJhdHVyZXMgYXJlIGJldHdlZW4gNjAgYW5kIDcwIGRlZ3JlZXMuCgpgYGB7ciwgZmlnLndpZHRoID0gMTAsIG1lc3NhZ2UgPSBGQUxTRX0KbGlicmFyeShncmlkRXh0cmEpCmM2MDcwIDwtIGZpbHRlcihjaXR5dGVtcHMsIHRlbXAgPj0gNjAgJiB0ZW1wIDw9IDcwKQpwMSA8LSBiYXJjaGFydChjaXR5IH4gdGVtcCwgYzYwNzApCnAyIDwtIGRvdHBsb3QoY2l0eSB+IHRlbXAsIGM2MDcwKQpncmlkLmFycmFuZ2UocDEsIHAyLCBucm93ID0gMSkKYGBgCgpgYGB7ciwgaW5jbHVkZSA9IEZBTFNFfQojIyBzYW5pdHkgY2hlY2sKbG9jYWwoewogICAgZCA8LSBhcy5saXN0KGNpdHl0ZW1wcyR0ZW1wKQogICAgbmFtZXMoZCkgPC0gY2l0eXRlbXBzJGNpdHkKICAgIHN0b3BpZm5vdChkJENhc2FibGFuY2EgPT0gNjEsIGQkRGhha2EgPT0gNjMsCiAgICAgICAgICAgICAgZCREdWJhaSA9PSA2OCwgZCQiR3VhdGVtYWxhIENpdHkiID09IDcwKQp9KQpgYGAKClRha2UgdGhlIERoYWthLUNhc2FibGFuY2EgcGFpciBhbmQgdGhlIER1YmFpLUd1YXRlbWFsYSBDaXR5IHBhaXIuCgoqIFRoZWlyIHRlbXBlcmF0dXJlIGRpZmZlcmVuY2VzIGFyZSB0aGUgc2FtZS4KCiogVGhlIGJhciBjaGFydCBtYWtlcyB0aGUgRGhha2EtQ2FzYWJsYW5jYSBjb250cmFzdCBsb29rIG11Y2ggbW9yZQogIGV4dHJlbWUgdGhhbiB0aGUgRHViYWktR3VhdGVtYWxhIENpdHkgY29udHJhc3QuCgpXaXRoIGEgc3Vic2V0IGxpa2UgdGhpcyB0aGUgZm9jdXMgaXMgb24gdGhlIGRpZmZlcmVuY2UsIG5vdCB0aGUKcmF0aW86IGluIHRoaXMgY29udGV4dCB0aGVzZSB0ZW1wZXJhdHVyZXMgYXJlIF9pbnRlcnZhbCBkYXRhXy4KCkFzIGFub3RoZXIgZXhhbXBsZSwgdGFrZSB0aGUgY2l0aWVzIGluIHRoZSBgUGxheWZhaXJgIGRhdGEgd2l0aApwb3B1bGF0aW9uIGJldHdlZW4gMTAwIGFuZCA1MDAgdGhvdXNhbmQ6CgpgYGB7ciwgZmlnLndpZHRoID0gMTB9ClAxNSA8LSBmaWx0ZXIoUGxheWZhaXIsIHBvcHVsYXRpb24gPj0gMTAwICYgcG9wdWxhdGlvbiA8PSA1MDApCnAxIDwtIGRvdHBsb3QoY2l0eSB+IHBvcHVsYXRpb24sIGRhdGEgPSBQMTUpCnAyIDwtIGJhcmNoYXJ0KGNpdHkgfiBwb3B1bGF0aW9uLCBkYXRhID0gUDE1KQpncmlkLmFycmFuZ2UocDEsIHAyLCBucm93ID0gMSkKYGBgCgpTb21lb25lIGNob29zaW5nIHRvIGxvb2sgYXQgYSByZXN0cmljdGVkIHJhbmdlIGxpa2UgdGhpcyBpcyBtb3N0Cmxpa2VseSBmb2N1c2luZyBvbiB0aGUgZGlmZmVyZW5jZXMgaW4gcG9wdWxhdGlvbiwgbm90IHRoZSByYXRpby4KClRoZSByYXRpbyBjb21wYXJpc29ucyBlbXBoYXNpemVkIGJ5IHRoZSBiYXIgY2hhcnQgYXJlIG5vdCBtZWFuaW5nZnVsLgoKU2V0dGluZyB0aGUgb3JpZ2luIHRvIHplcm8gcmVzY3VlcyB0aGUgYmFyIGNoYXJ0OgoKYGBge3IsIGZpZy53aWR0aCA9IDEwfQpQMTUgPC0gZmlsdGVyKFBsYXlmYWlyLCBwb3B1bGF0aW9uID49IDEwMCAmIHBvcHVsYXRpb24gPD0gNTAwKQpwMSA8LSBkb3RwbG90KGNpdHkgfiBwb3B1bGF0aW9uLCBkYXRhID0gUDE1LCBvcmlnaW4gPSAwKQpwMiA8LSBiYXJjaGFydChjaXR5IH4gcG9wdWxhdGlvbiwgZGF0YSA9IFAxNSwgb3JpZ2luID0gMCkKZ3JpZC5hcnJhbmdlKHAxLCBwMiwgbnJvdyA9IDEpCmBgYAoKRWl0aGVyIGNoYXJ0IGFsbG93cyBhIHJhdGlvIGNvbXBhcmlzb24gb3IgYSBkaWZmZXJlbmNlIGNvbXBhcmlzb24uCgoqIFRoZSByYXRpbyBjb21wYXJpc29uIGlzIGEgbGl0dGxlIGVhc2llciB3aXRoIGEgYmFyIGNoYXJ0LgoqIFRoZSBkaWZmZXJlbmNlIGNvbXBhcmlzb24gaXMgaGFyZGVyIGJlY2F1c2Ugb2YgdGhlIGRpc3RyYWN0aW9uCiAgY3JlYXRlZCBieSB0aGUgYmFycy4KKiBGb3IgcXVhbnRpdHkgbWVhc3VyZW1lbnRzIHJhdGlvcyBhcmUgdXN1YWxseSBhdCBsZWFzdCBtZWFuaW5nZnVsCiAgZXZlbiBpZiB0aGV5IG1pZ2h0IG5vdCBiZSB0aGUgcHJpbWFyeSBmb2N1cwoKU29tZSBub3RlczoKCiogV2hlbiB1c2luZyBiYXIgY2hhcnRzIGZvciBwb3NpdGl2ZSBudW1iZXJzIHdoZXJlIHJhdGlvcyBhcmUKICBtZWFuaW5nZnVsIHRoZSBiYXNlbGluZSBzaG91bGQgX2Fsd2F5c18gYmUgemVyby4KKiBUaGUgb25seSBleGNlcHRpb24gaXMgd2hlbiB0aGVyZSBpcyBhIG5hdHVyYWwgbm9uLXplcm8gYmFzZWxpbmUgdmFsdWUsCiAgc3VjaCBhcyAzMiBkZWdyZWVzIEZhaHJlbmhlaXQgKGkuZS4gMCBkZWdyZWVzIENlbGNpdXMpIGZvciB0ZW1wZXJhdHVyZXMuCiogWW91IG1heSBuZWVkIHRvIGludGVydmVuZSB3aXRoIHlvdXIgc29mdHdhcmUncyBkZWZhdWx0cyB0byBtYWtlIHRoaXMKICBoYXBwZW4uCiogQmFyIGNoYXJ0cyBhbHdheXMgcHVzaCB0aGUgdmlld2VyIHRvIHJhdGlvIGNvbXBhcmlzb25zLCB3aGV0aGVyCiAgdGhleSBhcmUgbWVhbmluZ2Z1bCBvciBub3QuCiogVXNpbmcgYSBub24temVybyBiYXNlbGluZSBjYW4gdGhlcmVmb3JlCiAgW21pc2xlYWQgdGhlIHZpZXdlcl0oaHR0cHM6Ly93d3cuc3Rvcnl0ZWxsaW5nd2l0aGRhdGEuY29tL2Jsb2cvMjAxMi8wOS9iYXItY2hhcnRzLW11c3QtaGF2ZS16ZXJvLWJhc2VsaW5lKS4KKiBTb21lIG5ld3Mgb3JnYW5pemF0aW9ucyBzZWVtIHBhcnRpY3VsYXJseSBwcm9uZSB0byB0YWtpbmcgYWR2YW50YWdlCiAgb2YvZmFsbGluZyBwcmV5IHRvIHRoaXMgaXNzdWUuCiogSSB1c2VkIGBsYXR0aWNlYCBpbiB0aGVzZSBleGFtcGxlcyBiZWNhdXNlIGl0IGlzIGhhcmQgdG8gZ2V0CiAgYGdlb21fYmFyYCBvciBgZ2VvbV9jb2x+IHRvIHVzZSBhIG5vbi16ZXJvIGJhc2UgbGluZSAod2hpY2ggaXMgYSBnb29kIHRoaW5nISkuCiogWW91IF9jYW5fIGNyZWF0ZSBhIGJhciBjaGFydCB3aXRoIGEgbm9uLXplcm8gYmFzZWxpbmUgdXNpbmcKICBgZ2VvbV9zZWdtZW50YC4KCgojIyMgRGF0YSBXaXRoIEJvdGggUG9zaXRpdmUgYW5kIE5lZ2F0aXZlIFZhbHVlcyAKQmFyIGNoYXJ0cyBjYW4gYmUgdXNlZCBmb3IgZGF0YSBjb250YWluaW5nIGJvdGggcG9zaXRpdmUgYW5kIG5lZ2F0aXZlCnZhbHVlczoKCmBgYHtyLCBmaWcud2lkdGggPSAxMCwgZXZhbCA9IEZBTFNFLCBpbmNsdWRlID0gRkFMU0V9CnAxIDwtIGRvdHBsb3QoY2l0eSB+IHRlbXAgLSAzMiwgZGF0YSA9IGNpdHl0ZW1wcywgb3JpZ2luID0gMCwKICAgICAgICAgICAgICBwYW5lbCA9IGZ1bmN0aW9uKHgsIHkpIHsKICAgICAgICAgICAgICAgICAgcGFuZWwueHlwbG90KHgsIHkpCiAgICAgICAgICAgICAgICAgIHBhbmVsLmFibGluZSh2ID0gMCwgbHR5ID0gMikKICAgICAgICAgICAgICB9KQpwMiA8LSBiYXJjaGFydChjaXR5IH4gdGVtcCAtIDMyLCBkYXRhID0gY2l0eXRlbXBzLCBvcmlnaW4gPSAwKQpgYGAKYGBge3IsIGZpZy53aWR0aCA9IDEwLCB3YXJuaW5nID0gRkFMU0V9CnAxIDwtIGdncGxvdChjaXR5dGVtcHMpICsKICAgIGdlb21fcG9pbnQoYWVzKHkgPSBjaXR5LCB4ID0gdGVtcCAtIDMyKSkgKwogICAgZ2VvbV92bGluZSh4aW50ZXJjZXB0ID0gMCwgbHR5ID0gMikKcDIgPC0gZ2dwbG90KGNpdHl0ZW1wcykgKwogICAgZ2VvbV9jb2woYWVzKHggPSBjaXR5LCB5ID0gdGVtcCAtIDMyKSkgKwogICAgY29vcmRfZmxpcCgpCmdyaWQuYXJyYW5nZShwMSwgcDIsIG5yb3cgPSAxKQpgYGAKCiogVGhpcyBwdXRzIGEgc3Ryb25nIGVtcGhhc2lzIG9uIHRoZSBiYXNlIGxpbmUKKiBUaGlzIGNhbiBiZSB1c2VmdWwgaWYgdGhlIGJhc2VsaW5lIGlzIG1lYW5pbmdmdWwsIHN1Y2ggYXMKICAgICogW2FuIGF2ZXJhZ2UgbGV2ZWxdKGh0dHBzOi8vd3d3Lm5jZWkubm9hYS5nb3YvYWNjZXNzL21vbml0b3JpbmcvY2xpbWF0ZS1hdC1hLWdsYW5jZS90aW1lLXNlcmllcy9nbG9iYWwpCiAgICAqIHplcm8gZGVncmVlcyBDZWxjaXVzCiogWmVybyBkZWdyZWVzIEZhaHJlbmhlaXQgaXMgbm90IG1lYW5pbmdmdWw6CgpgYGB7ciwgZmlnLndpZHRoID0gMTAsIGV2YWwgPSBGQUxTRSwgaW5jbHVkZSA9IEZBTFNFfQpwMSA8LSBkb3RwbG90KGNpdHkgfiB0ZW1wLCBkYXRhID0gY2l0eXRlbXBzLCBvcmlnaW4gPSAwLAogICAgICAgICAgICAgIHBhbmVsID0gZnVuY3Rpb24oeCwgeSkgewogICAgICAgICAgICAgICAgICBwYW5lbC54eXBsb3QoeCwgeSkKICAgICAgICAgICAgICAgICAgcGFuZWwuYWJsaW5lKHYgPSAwLCBsdHkgPSAyKQogICAgICAgICAgICAgIH0pCnAyIDwtIGJhcmNoYXJ0KGNpdHkgfiB0ZW1wLCBkYXRhID0gY2l0eXRlbXBzLCBvcmlnaW4gPSAwKQpgYGAKYGBge3IsIGZpZy53aWR0aCA9IDEwLCB3YXJuaW5nID0gRkFMU0V9CnAxIDwtIGdncGxvdChjaXR5dGVtcHMpICsKICAgIGdlb21fcG9pbnQoYWVzKHkgPSBjaXR5LCB4ID0gdGVtcCkpICsKICAgIGdlb21fdmxpbmUoeGludGVyY2VwdCA9IDAsIGx0eSA9IDIpCnAyIDwtIGdncGxvdChjaXR5dGVtcHMpICsKICAgIGdlb21fY29sKGFlcyh4ID0gY2l0eSwgeSA9IHRlbXApKSArCiAgICBjb29yZF9mbGlwKCkKZ3JpZC5hcnJhbmdlKHAxLCBwMiwgbnJvdyA9IDEpCmBgYAoKIyMgYGdncGxvdGAgRG9jdW1lbnRhdGlvbgoKKiBUaGUgYGdncGxvdDJgIHBhY2thZ2UgaW5jbHVkZXMgaGVscCBwYWdlcywgYnV0IHRoZSB2YXJpYW50cwogIGF2YWlsYWJsZSBhdCA8aHR0cHM6Ly9nZ3Bsb3QyLnRpZHl2ZXJzZS5vcmcvPiBhcmUgYSBiaXQgbW9yZSBhY2Nlc3NpYmxlLgoqIFRoZSBkZWZpbml0aXZlIGd1aWRlIGlzIEhhZGxleSBXaWNraGFtJ3MgYm9vay4KKiBTb21lIHVzZWZ1bCByZWNpcGVzIGFyZSBhdmFpbGFibGUgaWF0CiAgPGh0dHA6Ly93d3cuY29va2Jvb2stci5jb20vR3JhcGhzLz4uCiogQSBtb3JlIGV4dGVuc2l2ZSBjb2xsZWN0aW9uIGlzIGF2YWlsYWJsZSBpbiBXaW5zdG9uIENoYW5nJ3MgKDIwMTgpCiAgX1IgR3JhcGhpY3MgQ29va2Jvb2tfLgoqIFtfUiBmb3IgRGF0YSBTY2llbmNlX10oaHR0cHM6Ly9yNGRzLmhhZGxleS5uei8pIGFsc28gY29udGFpbnMKICBtYXRlcmlhbCBvbiBgZ2dwbG90MmAuCgoKIyMgR3JvdXAgU3VtbWFyaWVzCgpEb3QgcGxvdHMsIGFuZCBzb21ldGltZXMgYmFyIGNoYXJ0cywgY2FuIGJlIHZlcnkgdXNlZnVsIGZvciBzaG93aW5nCmdyb3VwIHN1bW1hcmllcy4gIFR3byBhcHByb2FjaGVzIGZvciBjb21wdXRpbmcgc3VtbWFyaWVzOgoKKiBVc2UgdGhlIGB0YXBwbHlgLCBgYnlgLCBhbmQgYGFnZ3JlZ2F0ZWAgZnVuY3Rpb25zIGZyb20gYmFzZSBSLgoKKiBVc2UgdG9vbHMgaW4gdGhlIGB0aWR5dmVyc2VgLCBpbiBwYXJ0aWN1bGFyIGZyb20gdGhlIGBkcGx5cmAKICBwYWNrYWdlLgoKSSB3aWxsIHVzZSB0aGUgYGRwbHlyYCBhcHByb2FjaC4gVGhpcyB1c2VzIGBncm91cF9ieWAgdG8gY3JlYXRlIGEKX2dyb3VwZWQgdGFibGVfLCBmb2xsb3dlZCBieSBgc3VtbWFyaXplYC4KCkhlcmUgaXMgaG93IHRvIGNvbXB1dGUgdGhlIGFnZXJhZ2UgYHlpZWxkYCB2YWx1ZXMgZm9yIGVhY2ggYHZhcmlldHlgCmluIHRoZSBgYmFybGV5YCBkYXRhOgoKYGBge3J9CmJhcmxleV9ieV92YXJpZXR5IDwtIGdyb3VwX2J5KGJhcmxleSwgdmFyaWV0eSkKYmFybGV5X3ZhcmlldHlfbWVhbnMgPC0gc3VtbWFyaXplKGJhcmxleV9ieV92YXJpZXR5LCBhdmdfeWllbGQgPSBtZWFuKHlpZWxkKSkKaGVhZChiYXJsZXlfdmFyaWV0eV9tZWFucykKZ2dwbG90KGJhcmxleV92YXJpZXR5X21lYW5zKSArCiAgICBnZW9tX3BvaW50KGFlcyh4ID0gYXZnX3lpZWxkLCB5ID0gYXMuY2hhcmFjdGVyKHZhcmlldHkpKSkKYGBgCgpUaGUgb3JkZXJpbmcgb2YgdGhlIGB2YXJpZXR5YCBmYWN0b3IgY3JlYXRlZCBieSB0aGUgdHdvIGFwcHJvYWNoZXMgaXMKYSBsaXR0bGUgZGlmZmVyZW50LgoKQW4gYWx0ZXJuYXRlIHdheSBvZiBzcGVjaWZ5aW5nIHRoZSBgZHBseXJgIGNvbXB1dGF0aW9uIHVzZXMgdGhlIF9waXBlCm9wZXJhdG9yXyBgfD5gOgoKYGBge3IsIGV2YWwgPSBGQUxTRX0KYmFybGV5IHw+CiAgICBncm91cF9ieSh2YXJpZXR5KSB8PgogICAgc3VtbWFyaXplKGF2Z195aWVsZCA9IG1lYW4oeWllbGQpKQpgYGAKCkluIHRoaXMgYXBwcm9hY2ggdGhlIHJlc3VsdCBvbiB0aGUgbGVmdCBvZiBgfD5gIGlzIHBhc3NlZCBpbXBsaWNpdGx5CmFzIHRoZSBmaXJzdCBhcmd1bWVudCB0byB0aGUgZnVuY3Rpb24gY2FsbGVkIG9uIHRoZSByaWdodC4KClNvbWUgbGlrZSB0aGlzIGFwcHJvYWNoIGEgbG90OyBvdGhlcnMgZG8gbm90LiBJIGRvIG5vdCBjYXJlIGZvciBpdC4KCgoKIyMgVmFyaWF0aW9ucyBpbiBBcHBlYXJlbmNlCgpCYXNlIGFuZCBsYXR0aWNlIGRvdCBwbG90cyB1c2Ugb25seSBoaXJpem9udGFsIGdyaWQgbGluZXMuIFRoaXMKY29ycmVzcG9uZHMgdG8gdGhlIHZlcnNpb24gaW50cm9kdWNlZCBieSBXLiBTLiBDbGV2ZWxhbmQuCgpMYXR0aWNlIGFuZCBnZ3Bsb3QgYWxsb3cgZmVhdHVyZXMgc3VjaCBhcyB0aGlzIHRvIGJlIGN1c3RvbWl6ZWQgdXNpbmcKX3RoZW1lc18uCgpgZ2dwbG90MmAgcHJvdmlkZXMgYSBudW1iZXIgb2YgYWx0ZXJuYXRlIHRoZW1zZXM7IHRoZSBgZ2d0aGVtZXNgCnBhY2thZ2UgcHJvdmlkZXMgbW9yZS4KClRoZSBfV2FsbCBTdHJlZXQgSm91cm5hbF8gdGhlbWUgYGdndGhtZXM6OnRoZW1lX3dzamAgcHJvZHVjZXMKCmBgYHtyfQpnZ3Bsb3QoYmFybGV5X3ZhcmlldHlfbWVhbnMpICsKICAgIGdlb21fcG9pbnQoYWVzKHggPSBhdmdfeWllbGQsIHkgPSBhcy5jaGFyYWN0ZXIodmFyaWV0eSkpKSArCiAgICBnZ3RoZW1lczo6dGhlbWVfd3NqKCkKYGBgCgpBIHRoZW1lIHRvIGNsb3NlbHkgbWF0Y2ggdGhlIHN0eWxlIHVzZWQgaW4gQ2xldmVsYW5kJ3MgMTk5MyBib29rCl9WaXN1YWxpemluZyBEYXRhXyBhbmQgdXNlZCBieSB0aGUgYmFzZSBhbmQgbGF0dGljZSBmdW5jdGlvbnMgY2FuIGJlCmRlZmluZWQgYXMKCmBgYHtyfQp0aGVtZV9kb3RwbG90eCA8LSBmdW5jdGlvbigpIHsKICAgIHRoZW1lKCAjIyByZW1vdmUgdGhlIHZlcnRpY2FsIGdyaWQgbGluZXMKICAgICAgICBwYW5lbC5ncmlkLm1ham9yLnggPSBlbGVtZW50X2JsYW5rKCksCiAgICAgICAgcGFuZWwuZ3JpZC5taW5vci54ID0gZWxlbWVudF9ibGFuaygpLAogICAgICAgICMjIGV4cGxpY2l0bHkgc2V0IHRoZSBob3Jpem9udGFsIGxpbmVzIChvciB0aGV5IHdpbGwgZGlzYXBwZWFyIHRvbykKICAgICAgICBwYW5lbC5ncmlkLm1ham9yLnkgPSBlbGVtZW50X2xpbmUoY29sb3IgPSAiYmxhY2siLCBsaW5ldHlwZSA9IDMpLAogICAgICAgIGF4aXMudGV4dC55ID0gZWxlbWVudF90ZXh0KHNpemUgPSByZWwoMS4yKSksCiAgICAgICAgIyMgdXNlIGEgd2hpdGUgYmFja2dyb3Vuc2QKICAgICAgICBwYW5lbC5iYWNrZ3JvdW5kID0gZWxlbWVudF9yZWN0KGZpbGwgPSAid2hpdGUiLCBjb2xvdXIgPSBOQSksCiAgICAgICAgcGFuZWwuYm9yZGVyID0gZWxlbWVudF9yZWN0KGZpbGwgPSBOQSwgY29sb3VyID0gImdyZXkyMCIpKQp9CmBgYAoKVGhpcyBwcm9kdWNlcwoKYGBge3J9CmdncGxvdChiYXJsZXlfdmFyaWV0eV9tZWFucykgKwogICAgZ2VvbV9wb2ludChhZXMoeCA9IGF2Z195aWVsZCwgeSA9IGFzLmNoYXJhY3Rlcih2YXJpZXR5KSkpICsKICAgIHRoZW1lX2RvdHBsb3R4KCkKYGBgCgoKPCEtLQpodHRwOi8vd3d3Lndpbi12ZWN0b3IuY29tL2Jsb2cvMjAxMy8wMi9yZXZpc2l0aW5nLWNsZXZlbGFuZHMtdGhlLWVsZW1lbnRzLW9mLWdyYXBoaW5nLWRhdGEtaW4tZ2dwbG90Mi8KLS0+CmBgYHtyLCBlY2hvID0gRkFMU0UsIGV2YWwgPSBGQUxTRX0KIyBBIGRvdHBsb3Q6IHByZXR0eSBjbG9zZSBhcHByb3hpbWF0aW9uIHRvIHRoZSBzdHlsZSBpbiBDbGV2ZWxhbmQncyBib29rLgojIFRoZSB0aGVtZSBhcmd1bWVudHMgcmVmZXIgdG8gdGhlIEZJTkFMIHggYW5kIHkgYXhlcywKIyBub3QgdGhlIHByZS1jb29yZF9mbGlwIGF4ZXMuCmdncGxvdChoZGF0YSkgKyBnZW9tX3BvaW50KGFlcyh4ID0gc3RhdGUpLCBzdGF0ID0gImJpbiIpICsKICAgIGNvb3JkX2ZsaXAoKSArCiAgICB0aGVtZSggIyByZW1vdmUgdGhlIHZlcnRpY2FsIGdyaWQgbGluZXMKICAgICAgICBwYW5lbC5ncmlkLm1ham9yLnggPSBlbGVtZW50X2JsYW5rKCksCiAgICAgICAgIyMgZXhwbGljaXRseSBzZXQgdGhlIGhvcml6b250YWwgbGluZXMgKG9yIHRoZXkgd2lsbCBkaXNhcHBlYXIgdG9vKQogICAgICAgIHBhbmVsLmdyaWQubWFqb3IueSA9IGVsZW1lbnRfbGluZShsaW5ldHlwZSA9IDMsIGNvbG9yID0gImRhcmtncmF5IiksCiAgICAgICAgYXhpcy50ZXh0LnkgPSBlbGVtZW50X3RleHQoc2l6ZSA9IHJlbCgwLjgpKSkKCmdncGxvdChQbGF5ZmFpcikgKyBnZW9tX3BvaW50KGFlcyh4ID0gY2l0eSwgeSA9IHBvcHVsYXRpb24pKSArCiAgICBjb29yZF9mbGlwKCkgKwogICAgdGhlbWUoICMgcmVtb3ZlIHRoZSB2ZXJ0aWNhbCBncmlkIGxpbmVzCiAgICAgICAgcGFuZWwuZ3JpZC5tYWpvci54ID0gZWxlbWVudF9ibGFuaygpLAogICAgICAgICMjIGV4cGxpY2l0bHkgc2V0IHRoZSBob3Jpem9udGFsIGxpbmVzIChvciB0aGV5IHdpbGwgZGlzYXBwZWFyIHRvbykKICAgICAgICBwYW5lbC5ncmlkLm1ham9yLnkgPSBlbGVtZW50X2xpbmUobGluZXR5cGUgPSAzLCBjb2xvciA9ICJkYXJrZ3JheSIpLAogICAgICAgIGF4aXMudGV4dC55ID0gZWxlbWVudF90ZXh0KHNpemUgPSByZWwoMC44KSkpCgpnZ3Bsb3QoUGxheWZhaXIpICsgZ2VvbV9wb2ludChhZXMoeSA9IGNpdHksIHggPSBwb3B1bGF0aW9uKSkgKwogICAgdGhlbWUoICMgcmVtb3ZlIHRoZSB2ZXJ0aWNhbCBncmlkIGxpbmVzCiAgICAgICAgcGFuZWwuZ3JpZC5tYWpvci54ID0gZWxlbWVudF9ibGFuaygpLAogICAgICAgICMjIGV4cGxpY2l0bHkgc2V0IHRoZSBob3Jpem9udGFsIGxpbmVzIChvciB0aGV5IHdpbGwgZGlzYXBwZWFyIHRvbykKICAgICAgICBwYW5lbC5ncmlkLm1ham9yLnkgPSBlbGVtZW50X2xpbmUobGluZXR5cGUgPSAzLCBjb2xvciA9ICJkYXJrZ3JheSIpLAogICAgICAgIGF4aXMudGV4dC55ID0gZWxlbWVudF90ZXh0KHNpemUgPSByZWwoMC44KSkpCgpnZ3Bsb3QoUGxheWZhaXIpICsgZ2VvbV9wb2ludChhZXMoeSA9IGNpdHksIHggPSBwb3B1bGF0aW9uKSkgKwogICAgdGhlbWUoICMgcmVtb3ZlIHRoZSB2ZXJ0aWNhbCBncmlkIGxpbmVzCiAgICAgICAgcGFuZWwuZ3JpZC5tYWpvci54ID0gZWxlbWVudF9ibGFuaygpLAogICAgICAgICMjIGV4cGxpY2l0bHkgc2V0IHRoZSBob3Jpem9udGFsIGxpbmVzIChvciB0aGV5IHdpbGwgZGlzYXBwZWFyIHRvbykKICAgICAgICBwYW5lbC5ncmlkLm1ham9yLnkgPSBlbGVtZW50X2xpbmUoY29sb3IgPSAibGlnaHRncmF5IiksCiAgICAgICAgYXhpcy50ZXh0LnkgPSBlbGVtZW50X3RleHQoc2l6ZSA9IHJlbCgwLjgpKSkKCnRoZW1lX2RvdHBsb3R4IDwtIGZ1bmN0aW9uKCkgewogICAgdGhlbWUoICMgcmVtb3ZlIHRoZSB2ZXJ0aWNhbCBncmlkIGxpbmVzCiAgICAgICAgcGFuZWwuZ3JpZC5tYWpvci54ID0gZWxlbWVudF9ibGFuaygpLAogICAgICAgIHBhbmVsLmdyaWQubWlub3IueCA9IGVsZW1lbnRfYmxhbmsoKSwKICAgICAgICAjIyBleHBsaWNpdGx5IHNldCB0aGUgaG9yaXpvbnRhbCBsaW5lcyAob3IgdGhleSB3aWxsIGRpc2FwcGVhciB0b28pCiAgICAgICAgcGFuZWwuZ3JpZC5tYWpvci55ID0gZWxlbWVudF9saW5lKGNvbG9yID0gImxpZ2h0Z3JheSIpLAogICAgICAgIGF4aXMudGV4dC55ID0gZWxlbWVudF90ZXh0KHNpemUgPSByZWwoMC44KSkpCn0KYGBgCg==
