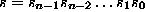 has an equivalent decimal value
has an equivalent decimal value  defined as:
defined as:
Introduction
This project builds on Project 1. There are two main differences between this project and Project 1.
Overview
As in Project 1, you will have to write two separate programs: buildDict and spellCheck. As in Project 1, the program buildDict builds a dictionary of words, while the program spellCheck uses this dictionary of words to determine which words in a given document are misspelled. The program buildDict builds a dictionary by extracting words from a document known to be free of spelling errors. However, in this project, buildDict also keeps track of the frequency of occurrence of each word that it extracts from the document. When buildDict completes extracting all the words from the document, it writes the extracted words onto a text file called words.dat. In particular, buildDict starts by writing the 500 most frequent words (in any order) into words.dat and then writes the remaining words into words.dat in alphabetical order. The spellCheck program reads words.dat and creates not one, but two dictionaries: a primary dictionary containing the 500 most frequent words and a secondary dictionary containing the remaining words. The primary dictionary will be stored in a hash table data structure while the secondary dictionary will be stored as before in a sorted Vector of string objects. A hash table is used for the primary dictionary because it provides almost instantaneous search capabilities. For each word in the document that is being checked for spelling errors, the program spellCheck first consults the primary dictionary and if the word is not found there, it consults the secondary dictionary. The motivation for this two-level organization of the dictionary is that many empirical studies have found that 80% of the words in an average document come from a list of about 500 words!
Building a Dictionary
The rules that define what a word is are as described in the Project 1 handout, with one change. Now I also want you to throw out capitalized words that do not start a sentence. That is, such strings should no longer be considered valid words and should not be inserted into the dictionary. A word is said to be capitalized, if its first letter is in upper case and the rest of the letters are in lower case. A word is said to begin a sentence, if the non-whitespace character immediately preceding the first letter of the word is a period. The reason for throwing out capitalized words that do not begin a sentence is that such words are likely to be proper nouns. It is possible that throwing out words as described above may not remove all proper nouns and may in fact remove some words that are not proper nouns. For this project buildDict needs to keep track of the frequency of occurrence of the words it is extracting from the available texts. This means that the wordList class needs to be modified to keep track of frequency information. Call the modified wordList class, fwList class (short for "frequency and word list"). You can decide what specific data members and member functions you need to add to the fwList class, but here are a few of my recommendations.
In addition to the texts of the three novels you used in Project 1, you should use the following three new novels also to build a dictionary. Note that these three files (especially, war.txt, which contains Leo Tolstoy's "War and Peace") are all much larger than the ones you used in Project 1.
The spellCheck program
After the buildDict program completes its task and creates a dictionary file words.dat, the spellCheck program is ready to take over. This program starts by reading the first 500 words from the file words.dat and stores these in a hash table. This is the primary dictionary. The hash table data structure will be described in the next section. It then reads the remaining words from words.dat and stores them in a list sorted in alphabetical order. This is the secondary dictionary. For the secondary dictionary, the spellCheck program can continue to use the wordList class. Then, as in Project 1, spellCheck starts extracting and spell checking words from the user document. For each extracted word spellCheck searches the primary dictionary first. If the word is not found in the primary dictionary, spellCheck searches in the secondary dictionary. Any word not found in both dictionaries gets identified as a misspelled word. Like in Project 1, spellCheck responds to a misspelled word by providing the following prompt:
Do you want to replace (R), replace all (P), ignore (I), ignore all (N), or exit (E)?
If the user responds with an R or a P, then the program responds by producing a list of at most 10 suggested replacement words that are labeled 0 through 9, followed by an option that allows the user to input their own replacement word. So for example, if spellCheck encounters the word ont it might respond as follows:
(0) ant (1) one (2) on (3) opt (4) out (5) Use my replacementNote that the list of suggested replacements may not always contain 10 words, 10 is just the maximum number of replacement words produced by the program. Also note that sometimes, the program may find no replacement words and in this case the user will just see the prompt
(0) Use my replacementThe user responds by typing a number corresponding to the option they want. If, in the above example the user types number between 0 and 4 (inclusive) then the program just uses the corresponding replacement word from the list. Otherwise, if the user types 5, then the program needs to ask the user for a replacement word and it uses whatever the user types in response.
In the next two sections of the handout, I'll describe what hash tables are and how to generate possible replacement words.
What is a hash table?
The idea of a hash table is simple. Let U be the set of all possible strings of lower case letters. Let h: U -> [0,..,M-1] be a function that maps each string in U to a number in the range 0 through M-1. Then any subset S of strings can be stored in a apvector called table of size M by storing a string s in S in slot table[h(s)]. To determine whether a given string s' in U is also in S, we simply compute h(s') and determine if table[h(s')] contains s'. The only problem with this method is that there can be collisions between strings. For example suppose that for two distinct strings s and s' in S, h(s) and h(s') are both equal to some integer k. This means that both s and s' have to be stored in slot table[k]. To handle such a situation, table should be defined not as a apvector of string objects, but as a apvector of string pointers. Then all strings that hash to a single slot, say table[k], can be stored in a singly linked whose head is being pointed to by table[k]. This approach to resolving collisions is called hashing with chaining. The only aspect of a hash table left to discuss is the hash function h itself.
Any string of lower case letters can be thought of as a number in base-26 by thinking of each
letter as the number obtained by subtracting 97 (the ASCII value of 'a') from the ASCII
value of the letter.
For example, the string next can be thought of as the following base-26 number: 13 4 23 19.
Thus a string has an equivalent decimal value defined as:
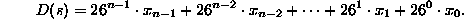
where 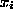 equals the ASCII value of
equals the ASCII value of 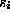 minus 97 for each i,
minus 97 for each i, 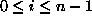 .
Now for any string s define the hash function
h(s) as h(s) = D(s) mod M.
Thus the function h maps any string onto the range 0 though
M-1.
You will have to watch of for possible integer overflow while computing
D(s).
The only thing left to decide is the value of M.
It is common practice to use a hash table whose size is approximately 10 times
the number of items being stored in it.
It is also common practice to choose the size of the hash table to be a prime number.
These two considerations led me to pick 5003 (the smallest prime larger than 5000) as
the value for M.
You should build a hashTable class that contains the definition
of a hash table (as described above) along with the insert
and search functions and any constructors and destructors that
you think are necessary (or useful).
.
Now for any string s define the hash function
h(s) as h(s) = D(s) mod M.
Thus the function h maps any string onto the range 0 though
M-1.
You will have to watch of for possible integer overflow while computing
D(s).
The only thing left to decide is the value of M.
It is common practice to use a hash table whose size is approximately 10 times
the number of items being stored in it.
It is also common practice to choose the size of the hash table to be a prime number.
These two considerations led me to pick 5003 (the smallest prime larger than 5000) as
the value for M.
You should build a hashTable class that contains the definition
of a hash table (as described above) along with the insert
and search functions and any constructors and destructors that
you think are necessary (or useful).
How to generate replacements?
We generate possible replacements for misspelled words by assuming that the most likely errors a user makes while typing are
apvectorkNeighborhood(const string & w, int k)
This function returns all words in the dictionary that are within k hops of w. This function uses the queue data structure will be discussed in class.
What to submit:
For the program buildDict, you need to submit:
fwList.h, fwList.cxx, buildDict.cxxFor the program spellCheck, you need to submit:
wordList.h, wordList.cxx, map.h. map.cxx, hashTable.h, hashTable.cxx, spellCheck.cxxYou should also submit a README file that tells us what level the program is running at and also what bugs there are, if any, in the program.
A final word:
While I have specified quite a few details, I have left enough unspecified so as to leave you with a few design decisions to make. These decisions will affect the efficiency, robustness, and readability of your program. So make your choices with care.
This project is more complicated than Project 1 along many dimensions. I suspect it will take most of you all of three weeks; so please do not wait for two more weeks to start!
In general the graders of your program will look for several things besides the correctness of your program. The overall organization of your program, the partitioning of various tasks into functions, and program documentation will be taken into account while grading.