The version of the myGraph class that represents graphs using an adjacency list representation, would have the following data members:
protected String[] names; // 1-d array to store the vertices protected LinkList[] Edges; // 1-d array of linked lists to store adjacencies between vertices protected int numVertices; protected int numEdges;Here LinkList is referring to the linked list class defined by Lafore. Recall that in the adjacency list representation, the linked list stored at slot i contains all the neighbors of vertex i. Assume that names (rather than indices) of the neighbors are stored in each of the Link objects, in each of the linked lists. Further assume that if X is a Link object, then you can access the name in this object by simply using X.name. Also, assume that there is a function called deleteFirst in the LinkList class that deletes the first Link from the linked list and returns that Link.
(a) [30 points] Write the member function of the myGraph class, called deleteVertex. To help you get started, below I provide part of the code; you will have to supply the rest.
public void deleteVertex(String vertex)
{
int i = getIndex(vertex);
if(i == -1)
{
System.out.print("deleteVertex: ");
System.out.print(vertex);
System.out.println(" failed -- it does not exist.");
return;
}
// Move the last vertex up to fill the hole made by vertex i
names[i] = names[numVertices-1];
names[numVertices-1] = null;
// MISSING CODE: You might want to use the following algorithm.
// Repeatedly delete the first neighbor of vertex i from i's adjacency
// list. For each deleted neighbor, X, delete i from X's adjacency
// list
// Move the adjacency list of the last vertex up to fill the hole
// made by vertex i
Edges[i] = Edges[numVertices-1];
Edges[numVertices-1] = null;
numVertices--;
}
(b) [10 points]
What is the worst case running time of the deleteVertex function as a
function of n, the number of vertices in the graph.
Express your answer in Big Oh notation.
(a) [25 points] Suppose that we modified the code for recursiveMergeSort as follows.
void recuriveMergeSort(int[] list, int first, int last)
{
if(last - first >= 2) // this is the only modification
{
int mid = (first + last)/2;
recursiveMergeSort(list, first, mid);
recursiveMergeSort(list, mid+1, last);
merge(list, first, mid, last);
}
}
In the above function, arrays of size 1 and arrays of size 2 are being treated
as "base cases" and not being sorted.
With this change, it is no longer guaranteed that the merge sort function
will actually sort.
For example, if list is an array of size 2, with
list[0] = 8 and list[1] = 3, and we send in
list, 0, and 1 as arguments to the above function, then the array
will come back unsorted.
Show the execution of recursiveMergeSort on the array given below:
list = 18 3 11 4 7 12 1 15.In addition to list, we send in 0 as the value of first and 7 as the value of last. To get partial credit, please show all your work. Specifically, show how the array list will look just as we enter each call to recursiveMergeSort.
Note: We are not changing the merge function at all.
(b) [15 points] On pages 337-339 in the textbook, Lafore provides a version of QuickSort. Looking at the code for recQuickSort you will see that in the recursive case, the first statement is:
long pivot = theArray[right];Why is the pivot chosen in this manner? What if we replaced this statement by
long pivot = theArray[left];Would Lafore's code still work? If it does, then explain why Lafore picks the pivot in this manner. If it does not, then explain how Lafore's code breaks, by showing an example on which it breaks.
Here is a simple recursive function to compute the value of a^n (the nth power of a). I assume here that a is an integer and n is a non-negative integer.
int power(int a, int n)
{
if (n == 0)
return 1;
else
return a * power(a, n-1);
}
(a) [5 points] When called with n equal to 50, how many multiplications does the above function perform?
(b) [20 points] It is possible to significantly improve the running time of this function, by using the following idea. If n is even, then a^n = square(a^(n/2)). For example, a^12 = square(a^6). This means that once a^(n/2) has been computed, it takes just one more multiplication to square it and compute a^n. Similarly, if n is odd, then a^n = a*square(a^((n-1)/2)). For example, a^15 = a*square(a^7). Use this idea to write a new recursive version of the function power. Note that the above equations expresses a^n in terms of smaller powers of a and this is exactly what you need to be able to write a recursive function.
(c) [10 points] When called with n equal to 50, how many multiplications does the new function perform? To get partial credit make sure that you show all your work.
(d) [5 points]
Express the running time of the new function as a function of
n, in Big Oh notation.
For the following edge-weighted graph, show the execution of the heap-based implementation of Dijkstra's Shortest Path Algorithm.
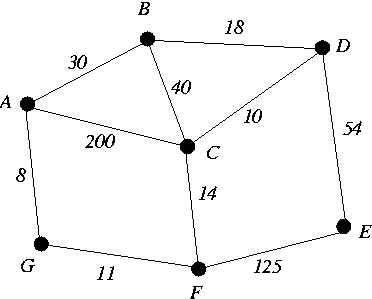
After each execution of the main loop, show the following items:
- which vertices belong to S and which do not;
- the d-values of all the vertices;
- the min-heap containing vertices in V - S and organized by the d-values of these vertices;
- the shortest path tree.
To get you started, here is the situation initially.
d-values min-heap shortest path tree
A B C D E F G X B 0 A
0* X X X X X X / \
C X X D
/ \ /
E X X F X G
In the above, X represents infinity.
So on the left, you see the table of initial d-values.
The * next to the 0 represents the fact that vertex A is in
S.
Note that since the d-values of all vertices in the min-heap are infinity,
any arrangement of these vertices in the heap would be fine.
I just arbitrarily picked a particular arrangement.
For each node in the min-heap, I show the name of the node and its
d-value.
Also, note that initially
the shortest path tree just consists of A.
This will be the root of the tree and as the main loop executes, other
vertices will attach themselves to the tree.
Recall that in our discussion in class, each node in a binary search tree is an object belonging to the following class:
public class Node{
public int key;
public Node leftChild;
public Node rightChild;
public Node(int k)
{
key = k; leftChild = null; rightChild = null;
}
public Node(int k, Node l, Node r)
{
key = k; leftChild = l; rightChild = r;
}
}
(a) [20 points] Write a boolean function called isBinarySearchTree that takes a Node object, say X, and determines if the binary tree rooted at X is a binary search tree or not. This is most easily done by writing a recursive function using the following idea: the tree rooted at X is a binary search tree if (i) the left subtree of X is a binary search tree, (ii) the right subtree of X is a binary search tree, (iii) the left child of X has key <= the key at X and (iv) the right child of X has key > the key at X.
The function header should be
boolean isBinarySearchTree(Node X)
(b) [20 points] Show the binary search tree you get by starting from the empty binary search tree and inserting
7, 11, 2, 9, 4, 22, 14, 17, 1, 3,in that order. Call this tree T. Then show the sequence of binary search trees you get by starting with T and deleting 7, 11, and 2, in that order.
Note: You will have to show a total of 4 binary search trees.