15. Inside a Modern CPU
Part of
CS:2630, Computer Organization Notes
|
Up to this point, we have described the central processing unit as
executing a sequential fetch-execute cycle, in which each instruction
is executed completely before the next instruction is fetched. We
can characterize such a processor as being hardware that executes
an algorithm such as the following:
while (TRUE) do {
... fetch one instruction
... get the operand registers and compute the effective address
... do the ALU operations or access memory as required
... save any results as required
}
|
Starting in the mid 1960s, Control Data Corporation and IBM pioneered
new approaches to the instruction execution cycle that
allowed for much higher performance by overlapping
the fetch of one instruction with the execution of its predecessors.
There were several approaches to doing this in the computers of
the late 1960s, and the Hawk is designed around two of these.
One fo the first successful approaches to speeding the fetch-execute cycle was developed by Control Data. This is known as functional unit parallelism. The Hawk coprocessor architecture is designed for this; to use the terminology introduced by Control Data, each coprocessor is a functional unit. When the Hawk CPU uses the COSET instruction to start a coprocessor operation such as a floating-point add, the coprocessor begins executing the indicated operation, but the CPU is free to fetch and execute other instructions. The only time the CPU waits for a coprocessor operation to finish is when the CPU uses a COSET or COGET instruction to communicate with a busy coprocessor.
The CDC 6600, introduced in 1965, took this to its logical extreme. It had separate functional units for load, store, integer arithmetic, and floating point arithmetic. What you might be tempted to call the central processing unit had just one job, fetching instructions and farming them out to the different functional units, waiting only when one instruction needed a result that was not yet available. The instruction fetch unit on the 6600 did no actual computation, so it was itself considered just another functional unit, and the term CPU was generally applied to the entire set of functional units.
The IBM System/360 Model 91, introduced in 1967, brought pipelined execution to the market, although the IBM 7030 (the Stretch) had explored this idea earlier. Pipelining can be described as the application of ideas from assembly-line mass production to the operation of the CPU. As each instruction flows down the pipeline, different pipeline stages operate on it until it has been completely executed.
By the late 1970s, pipelining dominated the design of
all but the simplest of computers.
Different pipelined machines have had different numbers of pipeline
stages. The first pipelines were short, with only two stages, and such
short pipelines remain common on small low-performance computers.
Pipelined processors have been built with five or more stages, but adding
stages beyond a certain point does not necessarily improve performance.
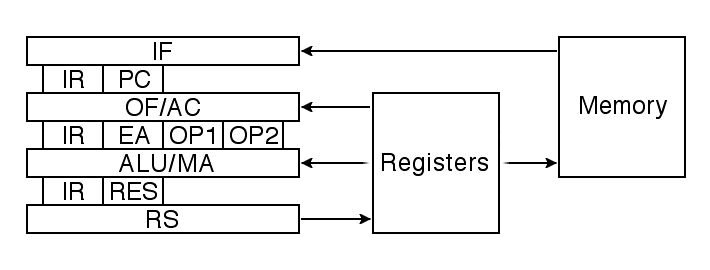
The four stage model illustrated here works well with the Hawk architecture
and is typical of many modern processors.
| IF | Instruction Fetch |
| OF/AC | Operand Fetch / Address Computation |
| ALU/MA | Arithmetic Logic Unit / Memory Access |
| RS | Result Store |
Just as we could express the behavior of a sequential processor in algorithmic terms, we can also express the behavior of a pipelined processor in such terms. The outer loop remains the same, but each iteration of this loop performs part of the computation for several different instructions in parallel. To do this, we need some way to express parallelism. In the following, we express this with the informally defined in parallel block, which initiates the parallel execution of all of the statements within that block:
while (TRUE) do in parallel {
... fetch instruction x
... get operands and compute effective address for instruction x-1
... do ALU operations or access memory for instruction x-2
... save any results as required by instruction x-3
}
|
For the 4-stage pipeline we are using here, there are always four instructions in various stages of execution, one being executed by each stage. It takes four execution cycles to complete each instruction, but one instruction is completed during each cycle. The following figure, called a pipeline diagram, illustrates the execution of a short sequence of instructions on a pipelined processor:
| LOADS R3,R4 | IF | OF/AC | ALU/MA | RS | |||
| ADDSI R4,1 | IF | OF/AC | ALU/MA | RS | |||
| STORES R3,R4 | IF | OF/AC | ALU/MA | RS | |||
| time | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
This diagram shows the execution of a sequence of 3 instructions being executed in 6 clock cycles. During cycle one, a LOADS instruction is fetched. During cycle two, while the effective address of the LOADS instruction is computed by getting the contents of R4, the next instruction, ADDSI fetched. During cycle three, while the load from memory required by the LOADS is being completed, operand R4 is fetched for the ADDSI instruction and the next instruction, STORES is fetched.
In fact, pipelining is more complex than is hinted at by the above explanation. In general, programmers prefer to think in terms of a straightforward fetch-execute cycle, and unfortunately, a simple implementation of pipelining does not always produce the same results as straightforward sequential execution of the same instructions.
Exercises
a) In the pipeline diagram given above, during what time step does the ADDSI update R4 and when does the STORES read R4? How does this effect the result of the program?
Pipelined processors work best if instructions are independent of each other. Consider the problem posed by the simple assignment statement a=b. If we assume that a and b are local variables, this would be done on the Hawk with two instructions, LOAD R3,R2,B followed by STORE R3,R2,A. If our pipelined machine executed these in sequence without any special considerations, we would get a strange result. This can be seen by examining the pipeline diagram.
| LOAD R3,R2,B | IF | OF/AC | ALU/MA | RS | ||
| STORE R3,R2,A | IF | OF/AC | ALU/MA | RS | ||
| time | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
The LOAD instruction is loads its operand from memory in cycle 3
and saves this operand in R3 during cycle 4. Meanwhile, the
STORE instruction gets its operand from R3 during cycle 3
and stores it to memory during cycle 4. As a result, even though the
LOAD instrucition is fetched before the STORE instruciton,
the effect is as if the LOAD was executed second. Pipelined
processors typically deal with such operand dependencies by
detecting the dependency and delaying the execution of the dependent
instruction until the necessary operands are present. The following
pipeline diagram illustrates this.
| LOAD R3,R2,B | IF | OF/AC | ALU/MA | RS | ||||
| STORE R3,R2,A | IF | delay | delay | OF/AC | ALU/MA | RS | ||
| time | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
These delay slots are introduced by interlock logic that detects that one pipeline stage depends on results from another and stalls that stage until the necessary results are available. In this case, the operand fetch stage of the store instruction stalls until the load instruction has completed its results store step.
Pipeline delay slots can destroy the potential performance of a pipelined
processor. To minimize their impact, processor designers developed
several tricks. Result forwarding logic is the most important. This
attempts to make results available sooner. For example, although the
result of the load instruction in our example is not properly in the
destination register at the end of the third cycle, it has been fetched
from memory at that point and it must therefore be
in some internal register of the processor. Therefore, a smart operand
fetch stage can get the data from that internal register instead of going to
R3 as directed by the instruciton.
This is called register remapping.
Result forwarding logic can
generally eliminate one delay cycle per operand dependency.
| LOAD R3,R2,B | IF | OF/AC | ALU/MA | RS | |||
| STORE R3,R2,A | IF | delay | OF/AC | ALU/MA | RS | ||
| time | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
Compilers can also play an important part in eliminating operand dependencies by rearranging the order of instructions in a program. Assembly language programmers can also reorder their instructions to eliminate operand dependencies, but the result is generally far less readable than an ordering that emphasizes the relationship of instructions to each other. As a result, hand crafted assembly code frequently runs slower than compiled code, given the use of a high quality compiler.
There are other delays that must be considered. Consider the problem of branch and jump instructions. Generally, the address computation stage of branch instructions computes the destination address, the ALU stage checks the condition codes to see if the branch should take place, and the result store stage actually sets the program counter. As a result, branch delay slots must be introduced to delay the next instruction instruction fetch after a branch instruction. In the worst case, a 4-stage pipeline requires 3 branch delay slots. Result forwarding can eliminate one of these, but to eliminate the others requires branch prediction logic to guess what instruction will follow each branch instruction and speculative execution to partially execute predicted instructions in the hope that the guess was correct.
Exercises
b) Consider the high level code a=b;c=d. This can be converted to assembly language in two different ways, assuming that the variables are all local. Which will be faster? Why?
LOAD R3,R2,B LOAD R3,R2,B STORE R3,R2,A LOAD R4,R2,D LOAD R3,R2,D STORE R3,R2,A STORE R3,R2,C STORE R4,R2,C c) Give a pipeline diagram for each of the above instruction sequences, assuming a simple pipelined processor without result forwarding or other tricks to reduce the number of delay slots.
The Hawk architecture was designed for the 4-stage model described above. In order to understand how this works, we must examine how the pipeline stages communicate with each other. In all pipelined processors, the output of each pipeline stage is stored in interstage registers that serve as input to the next pipeline stage. For example, in a pipelined processor, the instruction register is an interstage register loaded by the instruction fetch pipeline stage and serving as an input to all later stages. Similarly, the effective address register is an output of the address computation stage and an input into the memory access stage.
The first step in designing a pipelined processor after laying out the basic pipeline stages is to determine the interstage registers. Of course, the design process itself is iterative, so the first attempt usually contains errors or omissions that must be corrected in later refinements of the design. For a first attempt at pipelining the Hawk, the following interstage registers appear necessary:
The following figure shows these registers in pictoral form, in relation to the pipeline stages they interconnect. The figure also shows the relation of the pipeline stages to memory and the 15 general registers. The instruction-fetch stage needs read-only memory access, while the memory-access stage needs read-write memory access. The operand-fetch stage needs read-only access to registers, while the result-store stage needs write-only access.
|
|
Exercises
d) Which interstage register would provide data for result forwarding to the operand-fetch stage.
Given these registers, we can now begin to work out, in algorithmic form, the behavior of each pipeline stage. Consider, for example, the instruction fetch stage. If we ignore the problem of implementing branch instrucitons and if we ignore all long instructions, so we assume all Hawk instructions are 16 bits, this stage becomes very simple:
{ /* once per clock cycle */
if_pc = if_pc + 2;
if_ir = * (halfword_pointer) if_pc;
}
|
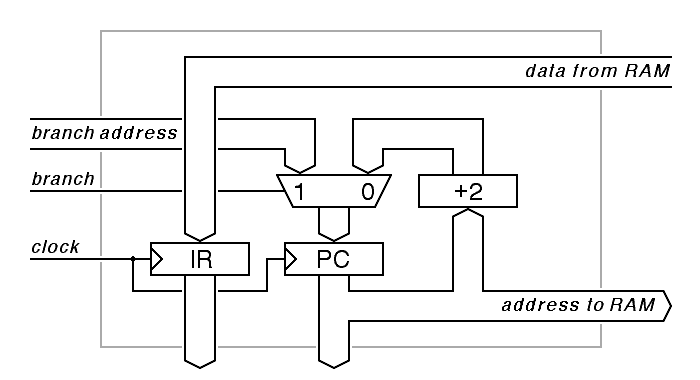
This version of the instruction-fetch stage is seriously oversimplified. In any useful computer, there must be some way to force a branch. We do this with an output from a later stage, for example, the result store stage. If the result-store stage detects a branch instruction, it must send the branch address to the instruction-fetch stage, along with a signal indicating that a branch is to be taken.
{ /* once per clock cycle */
if (branch) {
if_pc = branch_address;
} else {
if_pc = if_pc + 2;
}
if_ir = * (halfword_pointer) if_pc;
}
|
We can build this circuit using a multiplexer to select between the two potential values for the program counter, plus an incrementer.
|
We have preserved two major oversimplifications through this exercise. First, we have ignored long instructions. The Hawk computer is usable with only short instructions, but programs are far more compact if long instructions are permitted. Second, we have ignored the fact that physical memory addresses are 30-bit quantities (or 32 bits with the least significant two bits ignored), and that data to and from main memory is always transferred 32 bits at a time.
When multiple instructions are packed into each word, the instruction fetch stage typically includes a one-word instruction register. As each instruction is processed, there are two possibilities. If the instruction just processed is the last instruction in this word, the next word is fetched. Otherwise, the word is simply shifted to place the next instruction in position for processing. If all the instructions are the same length, for example, one 16-bit halfword, then all shifts are by the same amount, 16 bits.
Where variable-length instructions are involved, the instruction must be decoded enough to recognize the instruction length and the instruction register must be shifted by that amount. If instructions may straddle word boundaries, as is the case with long instructions on the Hawk, then the instruction register must be longer than one word, so that the word holding the tail end of an instruction can be fetched to append to the head end of the instruction that was fetched from the previous word.
Exercises
e) For each of the following, write an equivalent instruction sequence, using only short instructions. If you need a scratch register, use R1.
— LIL R3,#123456
— LOAD R4,R3,#1234f) Assume the data path from memory is 32 bits wide, and you have a 31 bit halfword address. Draw a circuit that splits the 31-bit address into b 30 bit word address and a 1 bit halfword-in-word signal, and then uses a multiplexer to select the correct halfword.
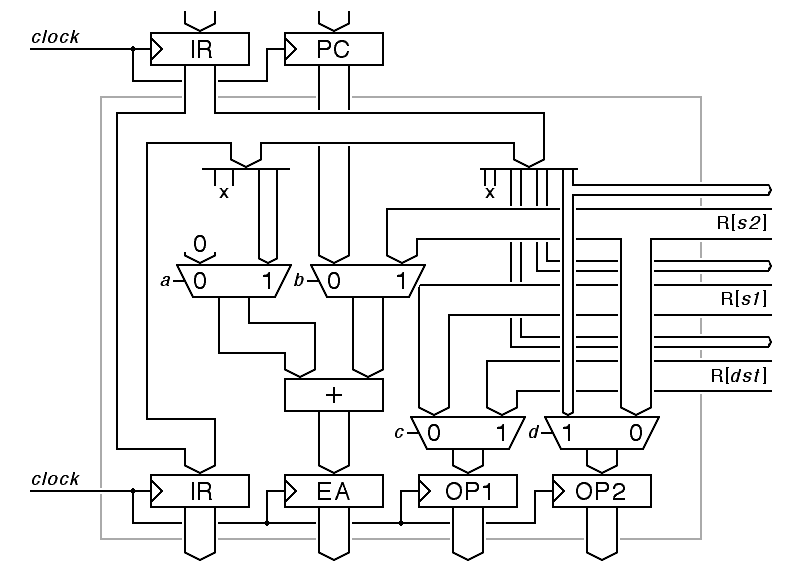
The operand-fetch/address-computation stage is sometimes called the operand-marshalling stage. Much of this stage's logic involves marshalling or shunting the values from various registers into the right inputs of the next pipeline stage. In British English, a railroad marshalling yard is where railroad cars are shunted around to make up trains. The one piece of logic that does something other than shunt operands around is the adder used for program-counter-relative and indexed address computation.
The details of the marshalling job depend on the value if the instruction register. For some instructions, we need the values of up to three registers. We can express the details as code, using a sequence of if statements to detail which inputs to this pipeline stage are sent to what outputs under what circumstances. The assignments can all be done in parallel, given parallel access to the general purpose registers.
{ /* once per clock cycle */
int dst = extract_dst_field( if_ir );
int s1 = extract_s1_field( if_ir );
int s2 = extract_s2_field( if_ir );
int disp = extract_disp_field( if_ir );
of_ir = if_ir;
if (is_branch( if_ir )) {
of_ea = PC + (disp << 1);
} else if ( s2 == 0 ) {
of_ea = PC;
} else {
of_ea = register[s2];
}
if (is_memref_or_two_register( if_ir )) {
of_op1 = register[dst];
} else {
of_op1 = register[s1];
}
if (is_ADDSI( if_ir )) {
of_op2 = if_s2;
} else {
of_op2 = register[s2];
}
}
|
In the above, and in the following logic diagram, a number of details have been omitted. Sign extension has not been documented at all, where it is required, and the data paths are insufficient to support several instructions. The logic diagram makes it clear that all of the inputs are delivered to every possible destination, with multiplexers at the destination determining which inputs are used and which inputs are ignored.
|
The control inputs a, b, c and d in the above diagram are all the result of decoding fields of the instruction register. Each multiplexer in the logic diagram corresponds to one of the if statements in the code, but in one case, operations are done in a different order. The code shows a 3-way choice of inputs to the effective address register, where only one of these choices involved the effective address adder. The diagram shows the adder last, with multiplexers selecting the inputs to the adder. This design allows the same adder to be used for indexed addressing when the design is extended to support the full Hawk instruction set.
Exercises
g) Express the inputs a, b, c and d used to control the multiplexers in the above drawing in terms of values of various bits or fields in the instruction register. Comparison with the code given previously should help.
h) There are at least two places in the code, and two places in the logic diagram, where sign extension or other alignment issues have been omitted. Identify each of these and explain what was left out of the code or logic diagram.
i) This logic diagram allows a 4-bit value from the s2 field of PC to be passed through into the OP2 register. What instructions need this? Does the difference in sign extension requirements for these two contexts make any difference to this pipeline stage?
j) This logic diagram does not appear to support the 8-bit constants needed for the LIS and ORSI instructions. Discuss how to add support for these instructions. It will probably take another 2-way multiplexer or alternatively, widening one of the 2-way multiplexers to a 3-way multiplexer. There may be alternatives, depending on which register you elect to use for the value being loaded.
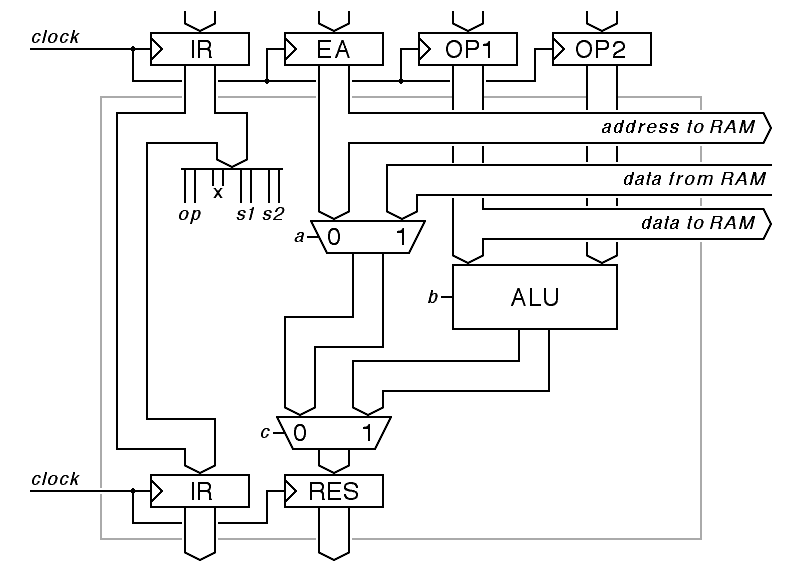
The arithmetic-logic-unit/memory-access stage either performs an ALU (including, possibly, shifts) on the two operand inputs, or it does a memory access for a load or store instruction. In addition, this stage can route the effective address to the result stage in order to handle the load-effective-address instruction. Here, we do not show code, but jump directly to the logic diagram.
|
As in the previous stage, the control inputs here, a, b, and c, derive from fields of the instruction register. Both a and c depend on whether the instruction is a memory reference instruction or an arithmetic instruction. Control input b is the function select for the ALU, including the shift count, so it is quite complex.
The version of the ALU stage shown here omits one very important detail: The
condition codes. Obviously, the condition code register must be an output
of this pipeline stage, with logic to select between those instructions
that change the condition codes and those that do not. It may well be that
the entire processor status word belongs in this stage. The multiplexer
controlling the input to the condition codes must have three settings, one
for loading the condition codes from the ALU output, one for loading the
condition codes in the CPUSET instruction, and one for instructions
that make no changes to the condition codes.
Exercises
k) Write out this stage, at a level of detail similar to that in the drawing, using a program notation similar to that used to describe the first two pipeline stages above.
l) What fields or bits of the instruction register control the multiplexer input shown as a in the diagram.
m) What fields or bits of the instruction register control the multiplexer input shown as c in the diagram.
n) The ALU control input b is a complex function of a number of fields of the instruction register. Use example instructions to show each field that matters.
o) There are obviously at least two control signals from this pipeline stage to memory, one used to indicate the need to read from memory and one used to indicate the need to write to memory.
— What fields or bits of the instruction register determine the value of the read-from-memory signal.
— What fields or bits of the instruction register determine the value of the write-to-memory signal.
The result-store stage takes the result from the previous stages and does one of several things:
The logic in this pipeline stage decides what to do with the result. The final decision about whether or not a conditional branch should be taken is made here, and this stage also makes the final decision about whether or not to save a result to one of the registers. The basic data flow in this stage is simple:
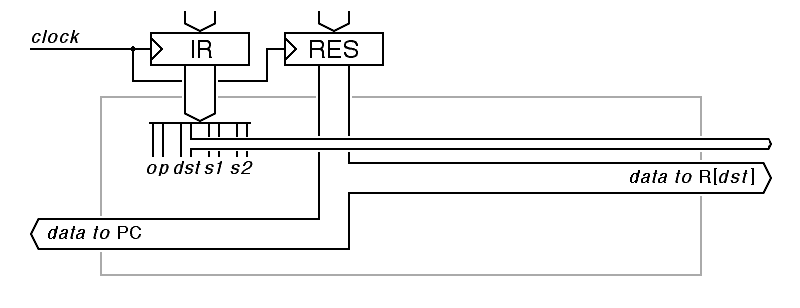
|
The version of the result-store pipeline stage shown here is oversimplified in two important aspects. First, it does not indicate the clock output to the registers or the take branch output to the instruction-fetch stage. These are derived from opcode decoding logic applied to the instruction register, augmented by the condition codes.
The second omission is just asjust as important: We have made no provision for call instructions. Calls must both change the program counter and save a result (the return address) to registers. We will have to fix our top-level design for the pipeline to solve this problem, adding at least one new interstage register so that this pipeline stage can see both the result and the return address (the old value of the program counter).
Some pipelined processors have what is called superscalar execution. This allows two (or more) instructions to be processed in parallel in each pipeline stage. So long as there are no operand dependencies between such instructions, this can lead to double (or more) the execution speed. The Hawk, with 16-bit instructions and a 32-bit data path to memory, lends itself naturally to two-way superscalar implementations.
Of course, superscalar execution means even more potential for operand conflicts, and the interlock logic needed to prevent unexpected results on a 2-way superscalar pipelined machine is frequently around four times the complexity of the interlocking needed in a simple pipeline. This leads to diminishing returns.
In the 1960's, Burroughs Corporation began seriously exploring the idea of building computers with multiple CPU's. These machines were somewhat successful in competition with IBM's mainframe family, but everything about the Burroughs family of computer architectures was sufficiently eccentric that most observers saw those systems as being well outside the mainstream of computer architectures.
In the 1970's, Gordon Bell of Digital Equipment Corporation and Carnegie Mellon University observed that multiple cheap minicomputers offered significantly more aggregate computing power than a single mainframe with the same cost. This led to a number of multi-minicomputer and multi-microprocessor architectures in the 1970's and 1980's. Some of these were marginally successful in the marketplace.
These multiprocessor experiments largely faded in the face of competition from pipelined superscalar machines, but in the 1990's, it was clear that the rate of return on pipelining and superscalar processors was in decline. Adding pipeline stages makes machines faster, but it increases the number of branch delay slots. A two-way superscalar processor can be twice as fast as a conventional processor, but only for straight-line code where there are not too many operand dependencies. Furthermore, a two way superscalar processor requires more than twice the silicon as the two pipelined processors it combines.
|
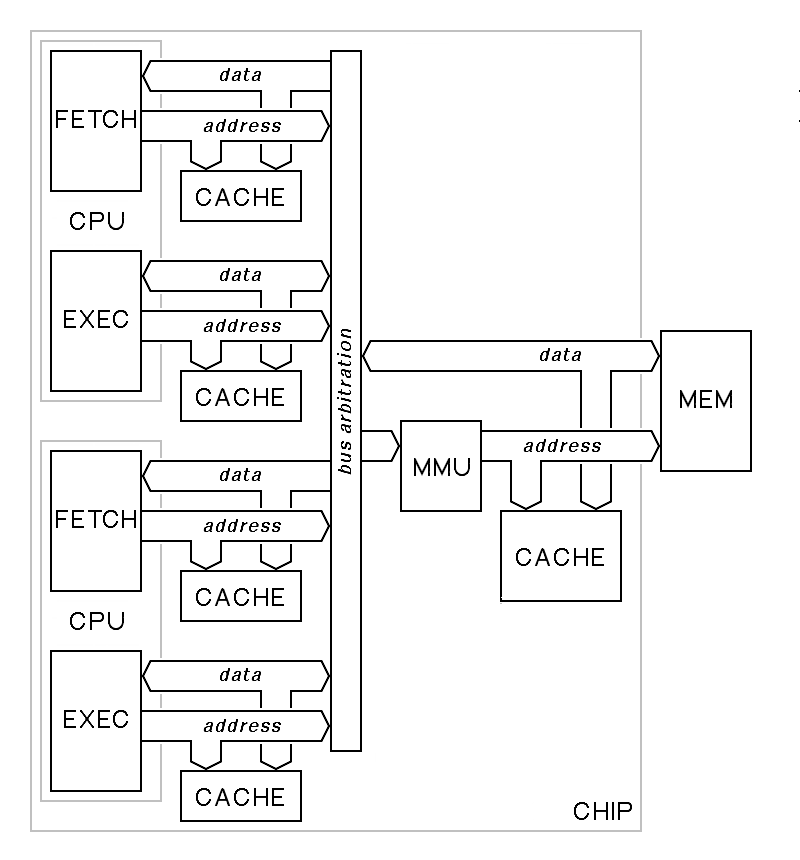
The diminishing returns gained from superscalar pipelines led, by the end of the 1990's, to the realization that the next direction in computer architecture was going to be single-chip processors with multiple CPUs. Such processors came to be called multicore processors. A multicore processor has two or more CPUs on one chip, sharing an on-chip cache and bus arbitration logic. The first generation of multicore processors had just two CPU cores, but four-core chips are now common, and Intel, IBM, Sun and AMD all have commercial offerings with 10 or more cores. Graphics coprocessors, the end product of an entirely different development path, frequently have even more processors on a chip, although without decent support for operating systems or non-display-oriented input-output
Because it has only one memory management unit, the multicore chip shown in the figure here requires that all processors operate in the same address space with the same access rights to memory. As such, it provides support for multithreaded applications but not for multiple independent processes that are protected from each other by separate memory management units. More sophisticated multicore systems either support multiple memory management units or more complex memory management units that allow each core of the processor to see a different memory address space.
Multicore chips, and before them, multiprocessors, pose real challenges to both operating systems and application developers. Unix proved, early on, to be well adapted to multiprocessors and was successfully ported to a number of multiprocessors in the 1980's. The X window manager for Unix works very well in the multicore-multiprocessor context because it uses a separate parallel process for the window manager. As processors expand above two cores, however full processor utilization will only be possible if the applications themselves are multi-threaded. Unfortunately, most applications programmers find it difficult to write multi-threaded code, but in the world of network servers, larger-scale multicore systems have worked quite well.
Pipelining, branch prediction and speculative execution have combined to create security problems. The Spectre vulnerability made public in early 2018 allows programs to crack several cryptographic algorithms by taking advantage of information that a program can learn about memory references that are speculatively executed but cancelled. Information about these references is left behind in various caches, and can be probed by detecting the extent to which the caches work to speed up different operations. The code needed to exploit such vulnerabilities is very subtle, but once written, it is very dangerous.