10. Separate Assembly and Objects
Part of
CS:2630, Computer Organization Notes
|
In the last chapter, we discussed many distinct number representations, along with the implementation of operations ranging from addition and subtraction, to multiplication and division. In an object-oriented programming language such as C++ or Java, we can define each of these classes or data types with a specific linguistic construct, the class definition. A class definition encapsulates all of the details of the representation of all objects in the class, so that outside that class definition, operations on objects of that class are carried out only by the methods defined for that class.
Assembly and machine language programmers cannot completely hide the details of the data types with which they work. Any time an object is loaded into registers, its size is exposed, and any time specific machine instructions are used to manipulate an object, these instructions must be used with full knowledge of their effect on the object's representation as well as on its abstract value.
Nonetheless, an assembly language programmer on a machine such as the Hawk can go a considerable distance toward isolating the users of objects from the details of their representations. We can do this in several steps, first isolating the code used to implement operations from the code that uses those operations, second, providing clean interface specifications for the objects, and finally allowing for polymorphic classes, that is, mixtures of different but compatable representations.
Suppose you have a set of subroutines, for example, multiply and divide, that you want to break off from a large program. Since the mid 1950's, there have been assembly languages that allowed such routines to be separately assembled before use in other programs. We have already been using such tools here in order to call routines in the Hawk Monitor without having to include that code as part of each source file.
There are at two good reasons to separate a program into multiple source files, no matter what programming language is being used. First, smaller source files can be easier to edit. Real-world application programs are frequently huge, with total sizes measured in thousands or even millions of lines of code. Second, separating an application into separate pieces lets us isolate program components that have already been tested from those currently under development. Some files may contain standard components that are used in many applications, while other files are unique to one application. The Hawk monitor is a good example of the later.
In assembly language programs, and to some extent, in C and C++ programs, there is another reason to separate programs into multiple source files. In these languages, some identifiers are defined locally within one source file, while other identifiers are global to all source files. In C and C++, for example, static functions and static global variables are local to the source file in which they are defined, while other functions and globals are genuinely global across all source files that make up an appliction. The use of the type qualifier static in these languages is eccentric, in that the word does not say what it means, but the idea remains quite useful despite its misnaming.
Here is a very small example C program, far too small to break up for separate assembly, but we will use it as an example. Our goal is to split out the subroutine library that supports the main program from the main program:
#include <stdio.h>
unsigned char charmul(unsigned char a, unsigned char b) {
return a * b;
}
unsigned char chardiv(unsigned char a, unsigned char b) {
return a / b;
}
int main() {
fprintf("%d = 10\n", chardiv(charmul(10, 12), 12));
return 0
}
|
If we try to simply split this file into two files, say main.c holding the main program and charlib.c holding the library of C functions, we can compile it using cc main.c charlib.c and it will work. This relies on the several defaults in C: Undefined functions are assumed to be externally defined and with integer values and take integer arguments, and when C functions take or return character values, those values are implicitly widened to int. Relying on these defaults without documenting them is bad form. Here is the code we ought to write:
/* charlib.h */
unsigned char charmul(unsigned char a, unsigned char b);
/* multiplies a and b */
unsigned char chardiv(unsigned char a, unsigned char b);
/* divides a by b */
|
This header file gives the interface definition for the two functions in our character-math library. In C, the interface definition for a function is simply the function header giving argument and return types without a body. We've followed three conventions here: First, that every file begins with a comment giving its file name. Second, that every interface definition is commented with documentation for its function. Third, header files for C programs use the file suffix .h. On Unix systems, there is no enforcement for any of these conventions. While the cc command enforces some file suffix conventions, the compiler itself does not.
Given this header file, we can write use the following library file for our library of character-math functions; here, we've followed yet another convention, that the inteface specification for a library should have the same name as the source file for that library, differing only in the suffix:
/* charlib.c */
#include "charlib.h"
unsigned char charmul(unsigned char a, unsigned char b) {
return a * b;
}
unsigned char chardiv(unsigned char a, unsigned char b) {
return a / b;
}
|
Given this, if we use cc charlib.c to compile this, the C compiler will force or definitions of charmul and chardiv to conform to the definitions in the header file. It will also complain that there is no main program, because we need to define the following:
/* main.c */
#include <stdio.h>
#include "charlib.h"
int main() {
printf("%d = 10\n", chardiv(charmul(10, 12), 12));
return 0;
}
|
Given all three of the above file definitions, we can compile our project with this command line: cc main.c lib.c. The compiler now has enough information about the library to check both the function declarations against the interface definitions and their uses against the interface definitions, and the cc command knows enough to take the object files resulting from the two compilations and link them into one a.out file.
The above file does rais one question. Why write <stdio.h> but "charlib.h"? This follows from an odd convention of the C preprocessor. When the preprocessor sees angle brackets as quotation marks, it looks for the quoted file name somewhere on the C system include directory search path. On Unix-based systems, this typically begins with /usr/include and then, if your file is not found there, other files. If, on the other hand, the C preprocessor finds double quotes, it looks on a search path that, by default, begins with the current working directory. For small prokects, if you store all the files in each project in the same directory and change to that directory while working on that project, the result works very well.
What about large projects? C was developed as a language for writing compilers and operating systems, usually very large programs. The developers of C at Bell Telephone Laboratories addressed this by creating a completely new tool, make. This is a general purpose tool for building software, regardless of language, so long as each build step can be done with shell commands. The input to make is a makefile that documents the interconnections between the files that make up a project, and more specifically, what shell commands to run in order to build each file from the files on which it rests. Here is a makefile for our little example:
# Makefile
a.out: main.o charlib.o
cc -o a.out main.o charlib.o
main.o: main.c charlib.h
cc -c main.c
charlib.o: charlib.c charlib.h
cc -c charlib.c
|
Each non-indented line in the makefile (aside from comments that begin with a pound sign) identifies a make target followed by a list of files needed to build that target. If make finds that the target needs rebuilding, either because it is missing or out of date, it will first make sure that each of the needed files is available, and then it will execute the shell commands that were indented under that target in order to build that target. This process is recursive: To build a.out, make may need to build main.o and charlib.o, and to build each of these, other things may need to be built.
While make usually does the right thing, the syntax has one horrible pitfall: Shell commands must be indented by tabs. Spaces and tabs are not equivalent in this context. Some versions of make try to fix this "feature," but this just creates incompatabilities.
The shell commands in the above makefile contain a number of command line options on the cc commands. The cc -c command means "just compile the program, producing an object file, don't try to link it into an executable." The cc -o xxx command means "produce the executable in a file named xxx." When cc is used with a list of files with .o suffixes, it knows that these are object files and it should just use the linker.
If the current directory contains a makefile, for example, a file named Makefile, the default name, then you can type just make with no arguments and it will build the first target listed in that makefile, if it can. Note that makefiles do not have a dotted suffix when used on Unix-based systems. In the context of our little example, make will build a.out from main.c, charlib.c and charlib.h, constructing charlib.o and main.o along the way. Type make followed by the name of a specific target to build just that target.
Make looks at the date of last edit while it works, and it understands that if you edited some file, all of the files that depend on that file will need to be rebuilt. So, after you make the example project, if you edit main.c and then run make again, it will recompile main.c and redo the final linkage step to make a.out, without rebuilding charlib.o
Note that make was developed for use with C programs, and it contains a number
of features that are C specific. By default, it knows that if a file named
x.o is needed and a file named x.c exists, it can use
the cc -c command to make it. C programmer can write shorter
makefiles by careful use of these features. We have only scratched the surface
of what make does.
| source code | main.c | charlib.h | charlib.c | |
|---|---|---|---|---|
| compiled by | cc -c main.c | cc -c charlib.c | ||
| object code | main.o | stdio.o | charlib.o | |
| linked by | cc -o a.out main.o charlib.o | |||
| executable code: | a.out | |||
The above figure summarizes all of the files involved in building our
project, in boxes, and the shell commands executed to translate each file
into a file closer to the final product. Note that charlib.h is
an implicit input to both of the cc -c commands because both
main.c and charlib.c include it.
Also note one file that was never mentioned above, stdio.o. When we run the linker, either the C linker or the Hawk linker, the linker always searches the system library for any library routines needed by the code being linked. The C main program in our example used printf, and the linker will find this, quite possibly in an object file called stdio.o that is embedded in a larger library of object files called stdlib. The detailed organization of this library is not the focus here, but the linkers we are using all have options that suppress linkage with the standard library in the rare event that is needed.
In C, all identifiers declared at the outer nesting level in a program are implicitly global unless declared to be static. In SMAL, on the other had, the default is that all identifiers are purely local to the source file in which they are declared. A SMAL identifier may be declared to be global by using explicit INT and EXT directives. INT X says that the symbol X defined internally in this source file is to be globally visible (it definitely does not mean integer). If X is not given a value in this file, it is an error.
EXT X says that the definition of the symbol X is external to this source file. This source file must not give X a value. Some other source file must contain the declaration INT X and that source file must define a value for X.
To continue this chapter's running example, we will construct SMAL Hawk source files and a makefile that are parallel to the C code already given. We'll begin with a SMAL Hawk header file:
; charlib.h -- a character arithmetic library
EXT CHARMUL
; expects R3,R4, 8-bit bytes to multiply
; returns R3, the product R3*R4, one byte
EXT CHARDIV
; expects R3,R4, 8-bit bytes to divide
; returns R3, the quotient of R3/R4 as one byte
|
Header files in assembly language are a distinctly weaker tool than in C.
The SMAL version of the charlib.h header file cannot give the types
of the parameters and return values in any form that the SMAL assembler can
enforce, but it can document this information for human readers in comments.
Given this header file, we can now write the SMAL version of charlib.a:
Note that the header file does not have a TITLE directive, just a
first-line comment. This is because, by default, header files are not listed
in the assembly listing file.
TITLE "charlib.a -- a character arithmetic library"
USE "hawk.h"
USE "stdlib.h"
INT CHARMUL
RETAD = 0
ARSIZE = 4
CHARMUL:
; expects R3,R4, 8-bit bytes to multiply
; returns R3, the product R3*R4, one byte
STORES R1,R2
ADDSI R2,ARSIZE
LIL R1,TIMESU
JSRS R1,R1 ; product = R3 * R4
TRUNC R3,8
ADDSI R2,-ARSIZE
LOADS PC,R2 ; return product % 256
INT CHARDIV
RETAD = 0
ARSIZE = 4
CHARDIV:
; expects R3,R4, 8-bit bytes to divide
; returns R3, the quotient R3/R4, one byte
STORES R1,R2
ADDSI R2,ARSIZE
LIL R1,DIVIDEU
JSRS R1,R1 ; quotient = R3 / R4
TRUNC R3,8
ADDSI R2,-ARSIZE
LOADS PC,R2 ; return quotient % 256
|
There are several things to note here: First, unlike C, SMAL does not have a distinctive form of quotation to indicate that a header file is in the system library. Instead, SMAL searches for the file in the current directory first, and if it does not find it there, it searches the SMAL Hawk system directory.
Second, charlib.a did not use the charlib.h header file because we needed to use INT directives in charlib.a while the header file gave EXT directives. Had charlib.a included a use directive for charlib.h, there would have been a number of error messages because it is illegal to declare the same symbol to both be EXT and INT.
Third, the C program merely declared the return types of the functions to be
unsigned char, leaving it to the compiler to make sure that the
value is truncated to the size allowed by that type. In the SMAL code, we
had to explicitly truncate the results of calling the multiply and divide
routines.
TITLE "main.a -- demonstrate use of charlib.a"
USE "hawk.h"
USE "stdio.h"
USE "ascii.h"
USE "charlib.h"
INT MAIN
RETAD = 0
ARSIZE = 4
MAIN: ; expects nothing, returns nothing
STORES R1,R2
ADDSI R2,ARSIZE
LIS R3,10
LIS R4,12
LIL R1,CHARMUL
JSRS R1,R1 ; t = charmul(10, 12)
LIS R4,0
LIS R4,12
LIL R1,CHARDIV
JSRS R1,R1 ; t = chardiv(t, 12)
LIS R4,0
LIL R1,PUTDEC
JSRS R1,R1 ; putdec(t, 0)
LEA R3,TEXT
LIL R1,PUTSTR
JSRS R1,R1 ; putstr(" = 10\n")
TRUNC R3,8
ADDSI R2,-ARSIZE
LOADS PC,R2 ; return
TEXT: ASCII " = 10",LF
|
This main program does exactly the same thing as the C program given earlier,
but it uses a fairly large number of header files. As the number of header
files grows, it makes sense to try to organize them. Here, system header files
are grouped first, while application header files come last.
The application header files are the only ones that need to be listed in the
makefile, so they need to be easy to see when the makefile is written or
checked.
Within each group,
more prominent or important header files come first, and related header files
are grouped together.
It seems natural, for example, to put ascii.h with stdio.h,
becaouse in this program, our only use of control characters in in the output
string.
# Makefile
link.o: main.o charlib.o
link -o link.o main.o charlib.o
main.o: main.a charlib.h
smal main.a
charlib.o: charlib.a
smal charlib.a
|
Notice that the overall structure of the makefile is the same for the assembly language and C versions of our little project. The shell commands have changed, but they do analogous things. The only substantial change is that charlib.o does not depend on charlib.h because that header file was not used by charlib.a.
a) Write a makefile for the hello.a program from Chapter 5. Given that this program is only a single source file, this is a degenerate case and leads to a very simple makefile with at most two make targets.
b) In Chapter 10, the functions putdecu and fibonacci were given. Assume that the main program calls fibonacci and prints the result using putdecu. Assuming that each function is in a separate source file, and that (aside from the main program) each source file has a header file, write a makefile for that project.
Before advancing to full-scale objects, it's useful to look at a degenerate case, where there is just one instance of the object. Many object-oriented languages allow you to define a class where the class itself in a single logical object. This is done in languages like C++, Java and related languages, by using private static fields for the data, which is manipulated by static methods. The separate compilation tools of C and SMAL provide natural support for this type of single-instance abstraction. In the following subsections, we'll use a stack as an example, giving code for a stack in C and an assembly language.
Within any separately compiled C file, variables and functions declared static are private to that file, while other global declarations are potentially visible everywhere. So, our stack.a code will include static definitions for the data representing the stack and non-static (that is, public) definitions of the functions that implement logical methods applicable to the stack object.
/* stack.h -- an array implementation of a stack */ void stack_push(int i); int stack_pop(); |
The above header file is deliberately minimal. Most real uses of stacks require other functions, or methods, if you prefer object-oriented terminology. At the very least, there ought to be a way to test for an empty stack and some action to take in the event of stack overflow. These are trivial to add, but we'll ignore them here because or focus is on the framework, not the details. If we wanted to add public fields to our stack abstraction, we could simply declare them here, as global variables visible to any code that includes this header file.
/* stack.c -- an array implementation of a stack */
#include "stack.h"
#define STACKSIZE 1000
static int stack[STACKSIZE];
static int sp = 0;
void stack_push(int i){
stack[sp] = i;
sp = sp + 1;
}
int stack_pop(){
sp = sp - 1;
return stack[sp];
}
|
This code is deliberately minimal. Production versions of this code ought to include defenses against popping from an empty stack and against pushing on a full stack. Ideally, these should raise or throw exceptions, but we have not yet discussed exceptions in C or assembly language, so we'll have to defer this issue.
In the stack implementation given here, note that the variables that representat the stack are both declared to be static. Static global variables in C are private to the source file in which they are declared. This means that if, at some later time, someone wants to change the epresentation of this stack, for example, so it uses a linked list of elements, all the changes required will be local.
Programs that use stack.c can only access the stack through the interface declared in stack.h. This forces outside code to use the stack abstraction, with only the stated access functions. The implementation is effectivel hidden inside stack.c, just in the way that the implementation of a class is can be hidden by the use of private fields in languages like Java.
Why does static mean private in C? The C keyword static takes its name from static memory allocation, and that is what it means when applied to local variables. By default, local variables are stored in the activation record that is dynamically allocated on the stack when on function entry and deallocated on exit. A local variable declared to be static is allocated statically, at a fixed address. As a result, that variable persists from call to call, even though it is only visible inside the function where it is declared.
All global variables in C are allocated statically, and if two different source files mention global variabls with the same name, they refer to the same variable. If there are two static local variables with the same name but declared in different functions, these refer to different variables. When the keyword static is used with a global variable, it doesn't change the static allocation of that variable, what it does is prevent the linker from linking that variable with others of the same name, in the same way it does this for static local variables.
If we did not declare the stack pointer sp in the above example to be static, we could put the declaration int sp in some other source file, and the linker would automatically make all references to that variable refer to the exact same memory location as is used for the sp declared in stack.c. If you really want a global variable to be shared between a large number of different source files, it is best to put the declaration in a header file so that all the source files see exactly the same declaration. Very few linkers can do type checking across separately compiled source files, and when they do it, they frequently do it poorly, for example, by checking the number of parameters, but not their types, or by enforcing only the simplest of type models.
c) Write a C main program and its makefile to test the stack implementation given here. It should push two different numbers on the stack and verify that they come out in LIFO order.
d) Modify the stack implementation so that sp is not declared to be static and then write a main program that peeks at the value of sp before and after push and pop operations, demonstrating that the sp is indeed accessible to the public.
TITLE "intmuldiv.a, integer multiply and divide"
USE "hawk.h"
INT STACK_PUSH
INT STACK_POP
STACKSIZE= 1000
COMMON STACKCOM,(STACKSIZE<<2)+4
SP = 0 ; the first word of stackcom
STACK = 4 ; the remainder of stackcom
LC = .
. = STACKCOM+SP
W 0 ; sp = 0
. = LC
STACK_PUSH:
; expects R3 -- i, the value to push
; uses R4 -- pointer to stackcom
; R5 -- working copy of sp
; R6 -- address of stack array
LIL R4,STACKCOM
LOADS R5,R4 ; -- sp
LEA R6,R4,STACK ; -- &stack[0]
ADDSL R5,R6,2 ; -- &stack[sp]
STORES R3,R5 ; stack[sp] = i
LOADS R5,R4 ; -- sp
ADDSI R5,1
STORES R5,R4 ; sp = sp + 1
JUMPS R1 ; return
|
There are several details in the above code worth comment. First, we could have used two separate COMMON declarations, one for STACK and one for SP. In effect, that is what C does with variables that are not declared to be static. The SMAL assembler provides only one tool for allocating global variables, the COMMON directive. If we want to allocate static variables that are not shared, what we need is a convention for naming the common block that holds those variables. What we've done here is use the file name as a prefix, and then bundle all of the private globals needed by that file into one common. Fields of this common are addressed as fields of a record.
The second argument on the COMMON directive gives the size of the desired statically allocated memory block. This information is passed to the linker, which does the actual allocation. The linker guarantees that each COMMON block begins at a word-aligned address, and if multiple source files happen to contain COMMON directives with the same name, they should all declare the same size; the best way to guarantee this is to put the declarations for shared COMMON blocks in a header file, the same advice that applies to shared global variables in C.
The code following the declaration of the fields of the COMMON initializes the SP field. This form of load-time initialization works for any statically allocated variable. We simply set the assembly origin to that variable, assemble the desired value into memory, and then restore the assembly origin to what it was before the initialization. The object code carries this information to the loader, and it is the loader itself that does the actual initialization.
The COMMON directive requires the programmer to give the size of the memory block being declared. The pattern we used for this is similar to the pattern we used for activation records. Each field of the COMMON block has a symbolic name, and the block size is named last.
What is common about a COMMON block? The term dates all the way back to FORTRAN II, introduced in 1958. As in SMAL, variables declared to be COMMON in FORTRAN II could be addressed in common from many separately compiled pieces of code. FORTRAN II was the first version of FORTRAN to support subroutine and function calls, and it set the model for the memory semantics of linkers that was assumed by the developers of C. The huge influence of C on modern languages means that, to this day, most linkers still support the memory model of FORTRAN II, and most assemblers and compiled programming languages still live within these constraints.
To reference a field of the COMMON block, we load a register with the block's address and then reference fields in exactly the same way we reference fields of any record. Where we reference local variables go in the activation record relative to R2, we reference fields of the COMMON block relative to some other register. Here we used R4. Because all fields of the common have static addresses, all of the addressing arithmetic can be done by the linker.
LEA R6,R4,STACK |
LIL R6,STACKCOM+STACK |
These two approaches to addressing fields of a COMMON on the Hawk take exactly the same amount of space in memory The difference is that one does its addition at run-time while the other does its addition at assembly and linkage time. On the most likely implementation of the Hawk, one using pipelined execution, these two instructions would be most likely to run at exactly the same speed; we will discuss this later.
e) Rewrite the recursive FIBONACCI routine from Chapter 6 so that it uses a common block to count the number of calls to FIBONACCI (recursive calls as well as calls from outside).
f) The POP routine was omited from the SMAL Hawk code given above. Write it for clarity, with little or no optimization.
g) Write the most optimal version of POP you can.
h) Write a main program that makes minimal use of the stack, just initializing it and then pushing and popping a value, and then write the header file and makefile so you can test it.
At this point, it should be clear that any object, say a stack, is represented by some memory locations to hold the variables that compose the representation of the object, and that the methods of a class are simply subroutines that operate implicitly on that object. In the special case where there is just one instance of the object, it can be statically allocated and initialized by the loader. In the fully general case where there are potentially an unbounded number of object instances, it must be allocated on the heap and initialized by run-time code.
Suppose we want to create multiple stacks? In a language like Python or Java, In this case, we must allow multiple instances of a stack to be created, and when we call the functions that implement methods of the stack class, we must tell the subroutine which object it is supposed to act on. In a language such as C++, Java or Python, if we needed to work with two stacks, a and b, we might write a.push(b.pop()) if we want to pop an item off of stack b and push it onto stack a.
Object-oriented dot notation such as a.push(1) becomes particularly critical whe the class of a is polymorphic, for example, if we have some stacks that use an array implementation and others that use a linked list. If a is not from a polymorphic class, we might just as well write stack_push(a,1). We used an underscore to separate the class name from the method name because underscores are legal parts of an identifier in C. The result of this conversion is that methods no-longer have any special status, they are just global functions or subroutines that happen to take a first argument that is of some particular type.
| Object oriented | Conventional | |
|---|---|---|
| a.push(b.pop()) | stack_push(a,stack_pop(b)) |
The point is, so long as polymorphism is not involved, the mechanisms we have already discussed in the context of the stack example are sufficient. The next step is to package the data required by the stack. To do this in C, we use a struct declaration. A struct in C is a collection of fields much like the fields of a class instance. Each field may be of a different type, and each field has a name. Here is a C definition of a struct allowing multiple instances of a stack:
struct one_stack {
int sp;
int stack[STACKSIZE];
};
|
Given this declaration, if we have a struct one_stack object named s, then s.sp, then is the stack pointer field of s and s.stack[0] is the bottommost item on the array field of s. Of course, we want a handle on our stack, that is, a light-weight way to reference a stack without makeing a copy every time we want to move that reference. This is done in C with pointers. If p is a pointer to a struct one_stack object, then we can refer to the stack pointer field as either (*p).sp or as p->sp.
The former notation is clunky but self explanatory. The * operator, as a prefix, applies only to pointers and means dereference that pointer of "follow it to the thing it points to", while the dot has its usual meaning for field selection. The -> notation seems to have come later as a short-hand to eliminate large numbers of parentheses.
The term struct is short for structure, but this is something of a misnomer, because a group of related fields is only one kind of data structure. Arrays are another data structure, as are linked lists, trees and graphs. To claim the term structure for one just one kind of data structure is almost certainly a mistake.
The same concept has other names in other languages. In COBOL and Pascal, it is called a record. Algol 68 also used the struct keyword. Fortran 90 calls this concept a type, another very odd choice of terms.
The next problem we face in C is how to hide fields of the record from users of our stack abstraction. We will do this by putting only limited information in the header file, while putting all of the information in the implementation. Here is the stack header file we will use:
/* stack.h -- interface allowing multiple stack instances */ struct one_stack; typedef struct one_stack * stack; stack stack_constructor(); void stack_push( stack this, int i ); int stack_pop( stack this ); |
Here, we used a forward declaration of struct one_stack in order to tell the compiler that there is such data type without giving any details. This allows us to declare the type stack to mean pointer to a struct one_stack, and it allows us to declare a collection of functions that take and return such pointers. Users of stacks who include this header file can use stacks freely, but they have no access to the details of what a stack is. Only in stack.c where the actual implementation of stacks is given will we finish the declaration of struct one_stack.
With only a single instance of a stack, the previous version could rely on the linker to do the construction. With multiple dynamically created instances, we need an explicit constructor that returns a newly allocated and initialized stack. There is no reason to use any particular formal parameter name inside any function, but here, we used this for the first parameter because this parameter is the object that would be referenced as this inside a Java method. This header file supports the following stack implementation:
/* stack.c -- implementation allowing multiple stack instances */
#include <stdlib.h>
#include "stack.h"
#define STACKSIZE 1000
struct one_stack {
int sp;
int stack[STACKSIZE];
};
stack stack_constructor() {
stack this = malloc(sizeof(*stack));
this->sp = 0;
return this;
}
void stack_push( stack this, int i ) {
this->stack[this->sp] = i;
this->sp = this->sp + 1;
};
|
The constructor given here beggins by calling malloc (defined in stdlib.h) to get enough memory to hold one stack instance. The sizeof function is not really a function; rather, it is a compile-time operator that gets the memory requirements of any data type, in bytes. On a 32-bit machine, for example, sizeof(int) is 4. Here, note that sizeof(stack) is 4, but sizeof(*stack) is the size of the object pointed to by that type, that is, the same as. sizeof(struct one_stack).
The malloc function returns a value of type void*, that is, pointer to an object of no particular type. C allows void* pointers to be assigned to any pointer type, and it allows any pointer type to be assigned to a void* variable. This is dangerous, because it allows all type checking to be defeated, but users of malloc rely on this feature.
There is no particular need for a destructor, because users of stack objects may directly call free to dispose of them when they are no-longer needed. The parameter type expected by free is void*, so it is legal to pass a stack or any other pointer type to free.
This code illustrates an important scope rule: Fields of a C struct have their own scope. There is no confusion betwee the global declaration of stack as a data type (a pointer to a struct one_stack), and the local declaration of stack as a field of struct one_stack.
i) Write the missing stack_pop routine that was omitted from the above C implementation.
j) Write a C main program that uses the above stack implementation to define two stacks, push a sequence of integers from 1 to 10 on one of them, pop them off onto the other, and then print them in the order they are popped from the second stack.
; stack.h -- interface allowing multiple stack instances
EXT STACK_CONSTRUCTOR
; expects nothing
; returns R3 -- the handle for one stack object
EXT STACK_PUSH
; expects R3 -- the handle for a stack object
; R4 -- i, the integer to push
; returns nothing
EXT STACK_POP
; expects R3 -- the handle for a stack object
; returns R3 -- i, the integer popped from the stack
|
Note that the header file for the C version declared the type one_stack while there is nothing analogous to that here, except for comments indicating that the parameters are stack handles. Assembly languages have no more concept of type than they have concept of parameters to subroutines. It is up to the programmer to document types and parameters, but the language itself does nothing to help enforce any of the rules mentioned in those comments.
TITLE "Stack implementation"
USE "stdlib.h"
STACKSIZE= 1000 ; the size of each stack
; fields of a stack object
SP = 0 ; an integer stack pointer
STACK = 4 ; a stack of STACKSIZE words
OBJSIZE = STACK+STACKSIZE ; size of one object
INT STACK_CONSTRUCTOR
; activation record format
RETAD = 0
ARSIZE = 4
STACK_CONSTRUCTOR:
; expects nothing
; returns R3 -- the handle for one stack object
STORES R1,R2
ADDI R2,R2,ARSIZE
LIL R3,OBJSIZE
LIL R1,MALLOC
JSRS R1,R1 ; this = malloc( objsize )
STORE R0,R3,SP ; this->sp = 0
ADDI R2,R2,-ARSIZE
LOADS PC,R2 ; return this
|
The constructor given here exactly parallels the code for the C version. In the single-instance version of the stack abstraction, allocation and initialization, the key jobs of an object constructor, were all done by the loader. Here, we rely on run-time code to first allocate the object and then perform the assignments needed to initialize it.
INT STACK_PUSH
STACK_PUSH:
; expects R3 -- the handle for a stack object
; R4 -- i, the integer to push
; returns nothing
LOAD R5,R3,SP ; -- this->sp
LEA R6,R3,STACK ; -- &this->stack[0]
ADDSL R5,R6,2 ; -- &this->stack[this->sp]
STORES R4,R5 ; this->stack[this->sp] = i
LOAD R5,R3,SP ; -- this->sp
ADDSI R4,1
STORE R4,R3,SP ; this->sp = this->sp + 1
JUMPS R1 ; return
|
The most notable thing about the stack push operation given here is that it is essentially the same as the code given for the statically allocated single-stack version of the code. The static version is one instruction longer, but every call to this version requires one extra parameter to be passed, but that is the only performance penalty we pay for using a dynamically allocated object.
k) Write the missing STACK_POP routine that was omitted from the above C implementation.
l) Write a SMAL Hawk main program that uses the above stack implementation to define two stacks, push a sequence of integers from 1 to 10 on one of them, pop them off onto the other, and then print them in the order they are popped from the second stack.
m) The code for STACK_CONSTRUCTOR and STACK_PUSH given above can be improved. Both routines have at least one long instruction that can be replaced by a short one. Identify them and give their replacements.
n) Memory references are more expensive than register references, even if the code is the same size. Rewrite STACK_PUSH to reduce the number of memory references by using another register.
Generally, C and assembly language programmers stop here. Most problems can be solved with either a single instance of a class or with multiple instances that share common implementation. Even C++, Java and Python programmers, when they design new classes, frequently use only one implementation. The standard libraries used with those languages, are quite different. These libraries are full of polymorphic classes, that is, abstract classes with multiple compatible implementations.
Consider, for example, the class stream of characters. Opening a file creates an instance of either subclass input_stream or output_stream, depending on whether the file was opened for input or output, and there might be a string to stream constructor that, given a string, returns a read-only stream that delivers successive characters of that string, and also a stream to string constructor that creates a string containing all of the text read from some stream. The file model of Unix is built on such a stream abstraction, even though it was originally exposed to users through the C library, which is distinctly not an object-oriented library.
The need for polymorphic input-output streams in operating systems was one of the two places from which object-oriented programming emerged. The other source of these ideas was discrete-event simulation, and more specifically, the Simula '67 programming language developed in the late 1960s at the Norwegian Computing Center by Ole-Johan Dahl and Kristen Nygaard. That language is the point of origin for the terms object, class, subclass and method, terms that dominate today's object-oriented programming languages.
For another example, all of the implementations of the stack of integers abstraction given above used an array with a stack pointer. Another equally useful implementation uses a linked list, where the push operation adds an element to the head of the list and the pop operation removes and returns an element. From the outside, a user of stacks may not be able to tell which implementation is being used, except perhaps if the user does careful performance measurements. In languages that inherit the object model of Simula '67, these two implementations can coexist in user programs, and code can be written that works equally well with both implementations.
The first and most obvious requirement for polymorphic data objects is that each object must contain some data to indicate which implementation it uses. For example, a polymorphic stack object could begin with a field indicating whether it is a linked-list stack or an array stack, and every call to a stack method could begin by testing this field to see which implementation to use. To the extent that early systems supported any kind of polymorphism, this was the only way it was done in the early 1960s, but by the end of that decade, the far more elegant (but perhaps difficult to understand) approaches outlined below emerged.
In the code that follows, we use function pointers, that is, variables that point to functions. These are not as complex as lambda abstraction in languages like Java and Python, because the λ mechanism not only allows a function to be passed, but also creates bindings of some or all of the variables used in that function.
/* stack.h -- polymorphic stack interface specification */
struct one_stack; /* use only to implement subclases */
typedef struct one_stack * stack;
struct one_stack;
void (*push)(stack,int);
int (*pop)(stack);
};
#define stack_push(s,i) s->push(s,i)
#define stack_pop(s,i) s->pop(s)
|
This header file corresponds to what you would declare as an abstract class in a language like Java. It has no implementation, because the implementations are expected to be provided by the subclasses that provide various implementations of the class. What it does do is tell the user of stacks, regardless of their implementaiton, that every stack has two fields, push, a pointer to the function that implements the push method, and pop, a pointer to the function that implements the pop method. We could add other public fields shared by all stack objects as fields of one_stack.
The format of the declaration of a function pointer in C and languages descended from C is not very well designed. The identifier being declared is hidden inside parentheses in the middle of the declaration.
As the comment suggests, struct one_stack should never be instantiated. No constructor is provided, but unfortunately, we cannot prevent a stupid programmer from creating one.
We also included two macros in this header file, stack_push and stack_pop. These macros package the awkward format of a call to a method, so that users need to mention the object just once, instead of having to mention it twice. Without this macro, for example, we would have to write mystack->pop(mystack) where, in languages like Java and Python, we would just write mystack.pop().
Given this set of definitions, the next challenge is to create a second header file defining the interface to one specific implementation of stacks, a subclass of the abstract class we have already implemented. This header file will declare the array-stack type and functions that implement the methods of that type.
/* arraystack.h -- stacks implemented with arrays */ /* always do an #include "stack.h" before including this */ struct one_array_stack; typedef struct one_array_stack array_stack; stack array_stack_constructor(); void array_stack_push(stack a, int i); int array_stack_pop(stack a); |
The interface is a little strange because an array_stack_constructur doesn't construct an array_stack, it constructs a stack, and the functions that implement the methods of an array_stack take parameters of type stack and not array_stack. This is due to the fact that C has weak but still significant type rules, and this is the best we can do under those rules. The net result is code that will break spectacularly if you accidentally pass a linked_list_stack to a function in array_stack.
Also notice the comment asking that any code that does #include "arraystack.h" first do #include "stack.h". Failing to do this will result in an error because arraystack.h assumes that type stack.h is already defined. We could have put the line #include "stack.h" at the start of arraystack.h, but then a program that used both arraystack.h and liststack.h would end up including stack.h twice. This style can lead to circular #include loops. There are mechanisms to fix this, but they are ugly.
/* arraystack.c -- implementing stacks with arrays */
#include <stdlib.h>
#include "stack.h"
#include "arraystack.h"
#define STACKSIZE 1000;
struct one_array_stack {
struct one_stack prefix;
int sp;
int stack[STACKSIZE];
};
stack array_stack_constructor() {
array_stack this = malloc(sizeof(*array_stack));
this->prefix.push = array_stack_push;
this->prefix.pop = array_stack_pop;
this->sp = 0;
return (stack)this;
}
void array_stack_push(stack a, int i) {
array_stack this = (array_stack) a;
this->stack[this->sp] = i;
this->sp = this->sp + 1;
}
|
In the above, note the use of casting. Inside the constructor an array stack is allocated and initialized, but before return, the pointer to it is cast to type stack in order to conform with the interface specification. Similarly, the stack pointer that is passed to the push routine is first cast to type array_stack before use. Aside from the use of casting, the code for array_stack_push is identical to the code for stack_push when there was no polymorphism, and the only changes to the constructor have to do with the prefix field.
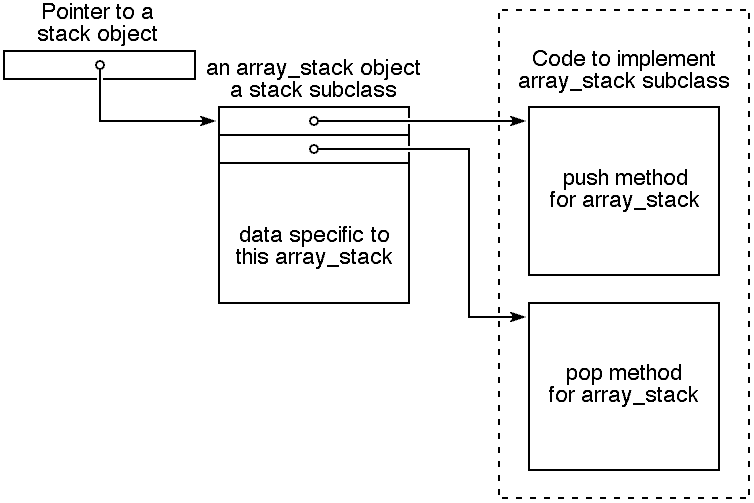
Also note that struct one_array_stack begins with struct one_stack, so that anyone following a stack pointer will see a one_stack object, and the constructor initializes both fields of this prefix. So long as the implementation of every subclass begins this way, the basic method dispatching code given in the #define directives in stack.h will work. The overall structure created by the constructor is summarized in the following diagram:
|
|
o) Write the missing array_stack_pop function.
p) Why can't we have array_stack_constructor return an array_stack and have array_stack_push take an array_stack as its first parameter. Hint: What happens when you use the code from stack_push with a pointer of type stack.
q) Given stack s, known not to be NULL, when is it safe to call list_stack_push(s,1) instead of stack_push(s,1)?
r) Write the code for list_stack.h and list_stack.c that implement a linked-list version of stack. The code in list_stack.c will have to declare a struct that holds one list element, holding a pointer to the next element and the integer that was pushed; list_stack_push will need to call malloc to get a new list element, and list_stack_pop will need to call free to deallocate the stack elemen that is no longer needed.
; stack.h -- polymorphic stack interface specification
; every stack, regardless of implementation, starts with these fields
PUSH = 0 ; address of the push code
POP = 4 ; address of the pop code
STACKSZ = 8 ; size of the basic prefix
; calls to the push code
; expects, R3 -- the handle for the stack object
; R4 -- i, the integer to push
; returns nothing
|
Notice that the above header file is mostly comments. Where C enforces rules about declaring parameter types and return-value types, all we can do in assembly language is write comments describing these. The rest of the header file, describing the interface to the pop code, is left as an exercise. In the C code given previously, we also provided #define statements that packaged and illustrated how to call each method of this polymorphic class. We could also add comments to the header file giving this, although the cod may be close to being self-evident:
LOAD R3,R2,MYSTACK ; -- parameter 1 and object handle LOAD R4,R2,MYVALUE ; -- parameter 2, the value to push ADDI R2,R2,ARSIZE LOAD R1,R3,PUSH ; -- get the pointer to the method code JSRS R1,R1 ; mystack.push(myvalue) ADDI R2,R2,-ARSIZE |
The most notable thing about this code is that it contains exactly the same number of instructions as the code to call a separately assembled subroutine. The only change is the replacement of an LIL instruction that gets the statically determined address of the code with a LOAD instruction to get the address out of the object itself. We did replace a load-immediate with a load instruction, which is to say, the code does one more memory reference, but considering the flexibility that polymorphism gives us in our programs, the cost is startlingly low.
There is almost nothing needed in the polymorphic version of the arraystack.h file, just EXT directives to declare the symbols for the subroutines there, plus comments. The code for the constructor, however, is interesting enough to give here:
TITLE "Array stack implementation"
USE "stdlib.h"
USE "stack.h"
STACKSIZE= 1000
; fields of an array-stack object
; fields from "stack.h" are implicit here
SP = STACKSZ ; an integer stack pointer
STACK = SP+4 ; a stack of STACKSIZE words
OBJSIZE = STACK+STACKSIZE ; size of one object
INT ARRAY_STACK_CONSTRUCTOR
; activation record format
RETAD = 0
ARSIZE = 4
ARRAY_STACK_CONSTRUCTOR:
; expects nothing
; returns R3 -- the handle for one stack object
STORES R1,R2
ADDI R2,R2,ARSIZE
LIL R3,OBJSIZE
LIL R1,MALLOC
JSRS R1,R1 ; this = malloc( objsize )
LEA R4,ARRAY_STACK_PUSH
STORE R0,R3,PUSH ; this->push = array_stack_push
LEA R4,ARRAY_STACK_POP
STORE R0,R3,POP ; this->pop = array_stack_pop
STORE R0,R3,SP ; this->sp = 0
ADDI R2,R2,-ARSIZE
LOADS PC,R2 ; return this
|
The declaration of the fields of an array-stack object above is ugly, at best. Up to now, we have been describing record structures using explicit constants for the offset of each field. This works fine when the fields are of fixed and known size, and all of the records we've described up to this point had either one-word fields, except for the various array implementations of stacks, where the record had a single "elastic" field at the end. The size of that field, of course, had to be taken into account in just one place, the overall size of the record.
Now, we have a record representing an array-stack object where the size of the prefix of the record is unknown; it depends on STACKSZ, a constant exported from stack.h that depends on the space occupied by what we called the prefix of the record in our C code, or what a Java programmer would call the superclass. This means that the location of each field in an array stack must be adjusted relative to the already-declared fields.
The constructor given here uses LEA instructions to get the addresses of the subroutines that implement the methods. These use pc-relative addressing, so the methods must be declared nearby, in the same source file. If they are declared externally, we'd need to use LIL instructions.
The code for ARRAY_STACK_PUSH is not given hee because it is identical to the code for the non-polymorphic STACK_PUSH already given
s) give the missing text of the polymorphic version of the SMAL Hawk stack.h file that were not given above. Comments matter here!
t) give code for the polymorphic version of arraystack.h Comments matter here!
A serious shortcoming of the polymorphic class implementation suggested above arises when a class has a large number of methods. Consider the case in a language like Java, where every class has a to_string method and an equals method, and instances of class Integer have 10 methods, 6 of which are definitely polymorphic because they are shared by all subclasses of Number. If we used the methodology outlined above for implementing polymorphic classes, we would augment every 32-bit integer with at least 6 method pointers plus whatever the overhead is for each object on the heap. The story is similar in Python.
That is, for each useful variable in our programs, languages like Java would impose an memory overhead that easily approachs a factor of 10 if they used the approach outlined above to implement polymorphism. Fortunately, there is an alternative.
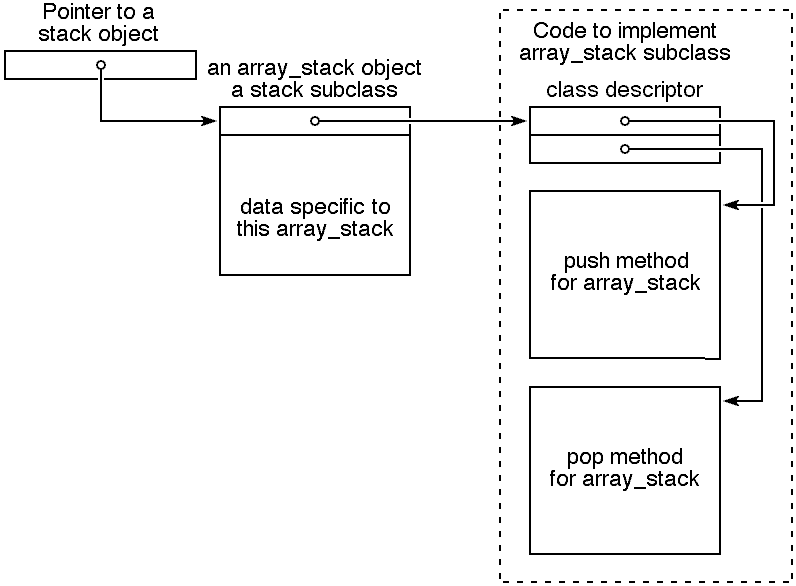
|
In computer science, the term descriptor is a standard term used for any part of a data structure that serves to describe that data structure or how to use it. Here, the descriptor tells us where the methods are for operating on some object, but descriptors may tell many other things. Garbage collectors work better if each memory segment descriptor tells which words in that segment are pointers to other segments. Storage managers need a descriptor that tells the size of each segment and whether it is currently in use or free. The word tag is sometimes used when the descriptor is just one word or one byte.
The alternative approach involves a more complex data structure, moving the record of method pointers out of the object. Instead, all objects of each class begin with just a single pointer to the class descriptor. The descriptor is a constant record; for our purposes, what matters is that it holds all of the method pointers, but it may also hold structural information needed by the memory manager and other information to support the object model of the language.
/* stack.h -- compact polymorphic stack interface specification */
struct one_stack; /* use only to implement subclases */
typedef struct one_stack * stack;
struct stack_descriptor { /* every subclass has one of these */
void (*push)(stack,int);
int (*pop)(stack);
}
struct one_stack;
struct stack_descriptor * descriptor;
};
#define stack_push(s,i) s->descriptor.push(s,i)
#define stack_pop(s,i) s->descriptor.pop(s)
|
The header file giving the interface to our compact polymorphic stack has one big addition, struct stack_descriptor, giving the layout of the class descriptor layout that must be provided by each implementation of the stack.
We still have the option of adding public fields that are shared by all stack objects to struct one_stack, but in the absence of such fields, this struct has been reduced to just one field, a pointer to the descriptior.
As in the first polymorphic stack, we have provided stack_push and stack_pop macros. These are slightly more complex than the versions given previously, but to see the actual cost, we need to translate one of these to assembly language.
LOAD R3,R2,MYSTACK ; -- param 1, object handle LOAD R4,R2,MYVALUE ; -- param 2, value to push ADDI R2,R2,ARSIZE LOADS R1,R3 ; -- get this stack's descriptor LOAD R1,R1,PUSH ; -- get the pointer to method JSRS R1,R1 ; mystack.push(myvalue) ADDI R2,R2,-ARSIZE |
The most noteworthy thing about this code is that it takes just one more machine instruction per call than the original code given above for a polymorphic call, and because we put the pointer from the object to its descriptor as the first field of the object, we were able to use short-indexed addressing on the Hawk instead of the more expensive long form. Even the C code doesn't hint at the low cost of this implementation of polymorphism.
A good C++ compiler should be able to generate code comparable to the above for any call to a method of a polymorphic class. When the method being called can be statically determined, that is, when the compiler can figure out which subclass is actually being used, the compiler has the option of directly calling the method without following a pointer to the descriptor.
The header file given for the first version of arraystack.h will work just as well with this verison, since nothing in that header file mentions how we have handled polymorphism. The constructor, however, has to change because it must now provide a specific instance of struct stack_descriptor for use by all instances of one_array_stack.
/* arraystack.c -- implementation of an array stack */ #include |
In the above, descriptor is declared to be static so that it cannot be seen from any other source file, and it is declared to be const so that it cannot be modified. On many machines, this means that the descriptor will be stored in with the program code, initialzed by the loader before it is marked read-only so that it cannot be changed. In later chapters, we will discuss how read-only restrictions can be enforced on regions of memory using the memory management unit.
All versions of C allow structures to be initialized by listing the values of the fields inside curly braces. In the original version of C, the values of the fields were simply given in order. ANSI Standard C, released in 99, added the ability to name the structure fields being initialized, as is done here.
Finally, note that the C code for the push and pop routines given for the previous polymorphic stack implementation would work identically with this implementation.
u) No assembly language code was given for the stack.h file for the compact polymorphic stack. Write one.
v) Write the SMAL Hawk code for array_stack.a, up through the constructor.
w) Aside from the offsets of fields within records, how would the SMAL Hawk code for the compact version of the push and pop routines differ from the code for the first polymorphic version given above. (The code for the calls is already given. Here, our concern is with the subroutines themselves.)
C++ and Java support generic classes, while the code given above, both for simple and polymorphic stacks, supported just one abstract type, stacks of integers. This seems limiting.
In both C++ and Java, all instances of objects are on the heap, and all code that manipulates objects does so by passing object handles. As we have seen, object handles are just pointers in C and assembly language, so if we create an abstraction that can accept any pointer to an object as a parameter, we have created a generic object.
C allows has a special type, void* that, read narrowly, means "pointer to nothing." The library routine malloc returns a void * pointer because it has no clue about the type of the object it is allocating, only the number of bytes to allocate. Every time we allocated an object using malloc we had to cast that object to our desired type, for example by using (array_stack)malloc(...).
We can use casting in C to build generic classes. To build a generic stack, for example we declare our stack to hold void* objects, so if s is a generic stack and o points to some object, we call s.push((void*)o) and when we call pop, we will get back a void* pointer that we must then cast to the pointer type of the object we pushed.
If we have been pushing only one pointer type, then all the pointers we pop will refer to objects of that type, and there is no need to do any chacking. The type rules of Java and C++ automatically enforce this when you, for example, create a stack of strings from a generic stack class and the string class. The language prevents you from pushing anything but a string on that stack, and it knows that everything popped from that stack will therefore be a string.
Hawk code is even less constrained by any concept of type than C. The PUSH and POP code we have written above works with any 32-bit quantity, whether that quantity is an integer or a pointer to some object. It is up to the programmer to prove, with no help from the programming environment, that either everything pushed on the stack is from the same class, or that everything pushed includes an indicator of the class to which it belongs so that it can be correctly classified after it is popped.